








引言
Word2Vec是google提出的一个学习word vecor(也叫word embedding)的框架。
它主要提出了两个模型结构CBOW和Skip-gram,这两个模型都属于Log Linear模型,结构如下所示:
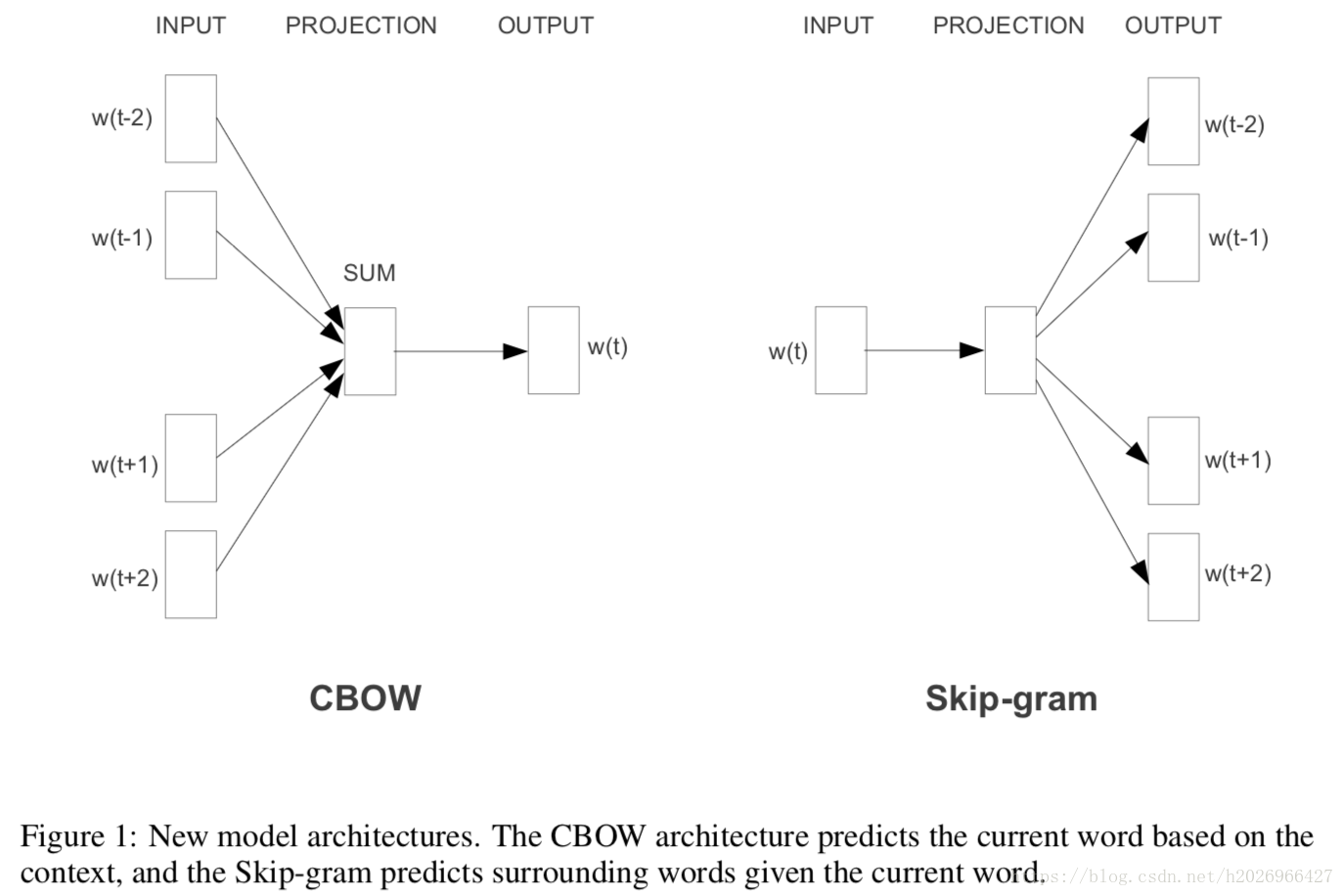
CBOW对小型数据比较合适,而Skip-gram在大型语料中表现得更好。
CBOW模型
CBOW main idea:Predict center word from (bag of) context words.
cbow全称为continues bag of words,之所以称为continues是因为学习出来的word vector是连续的分布式表示的,而又称它是一个bag of words模型是因为在训练时,历史信息的词语顺序不影响Projection,因为之后不是将各个词concate,而是sum,而且这样也大大较少了计算量!
CBOW的详细结构如下:
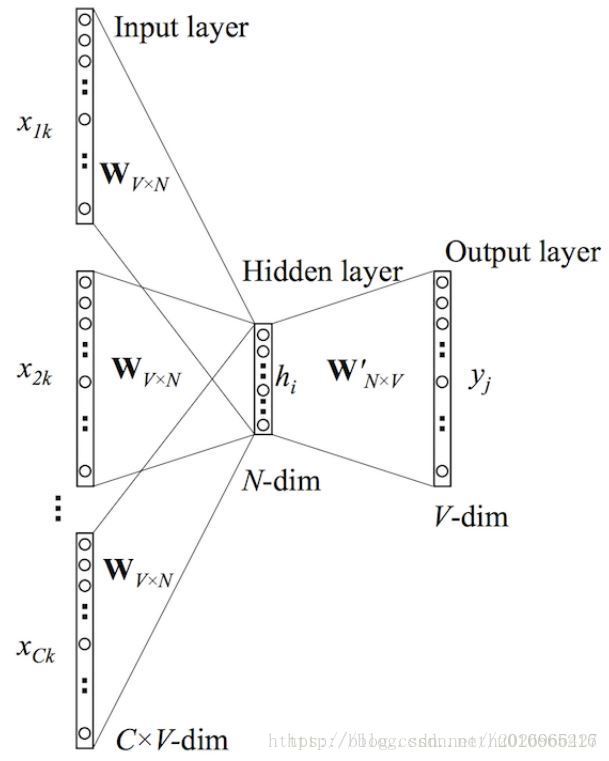
输入是one-hot向量表示的词,之后Projection成N维的低维稠密向量并加权求和,然后与W’相乘,经过softmax求得预测单词的概率分布y,概率分布中概率最大的单词就是应该输出的单词。
Skip-grams模型
SG main idea:Predict context (”outside”) words (position independent) given center word.
SG的详细结构如下:
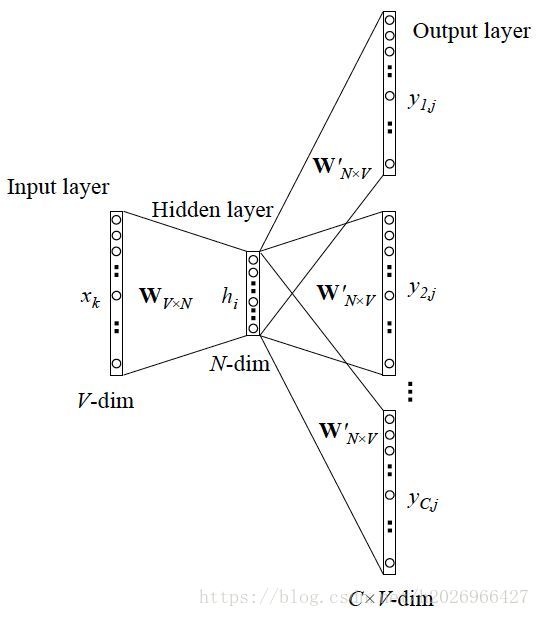
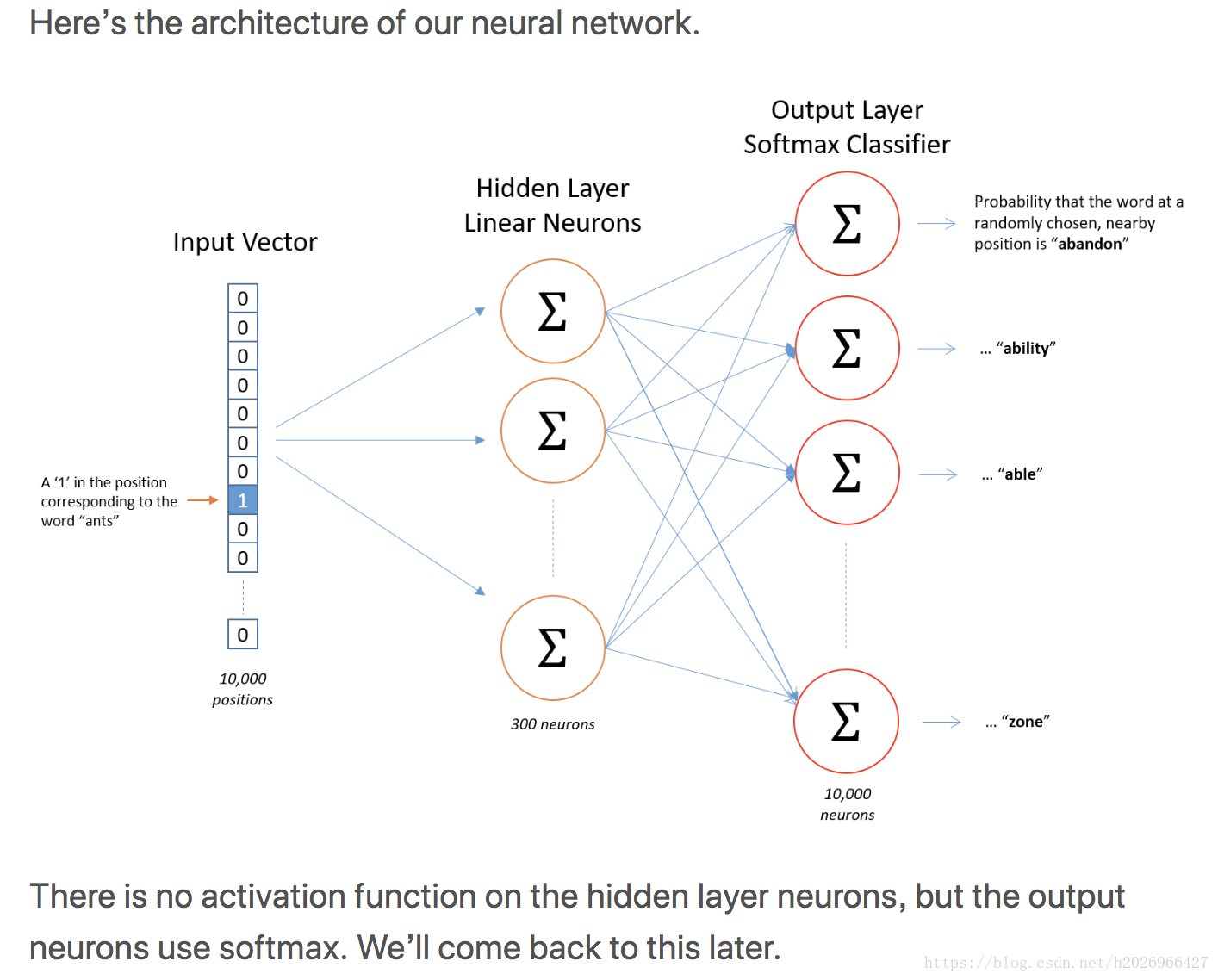
隐藏层如下:
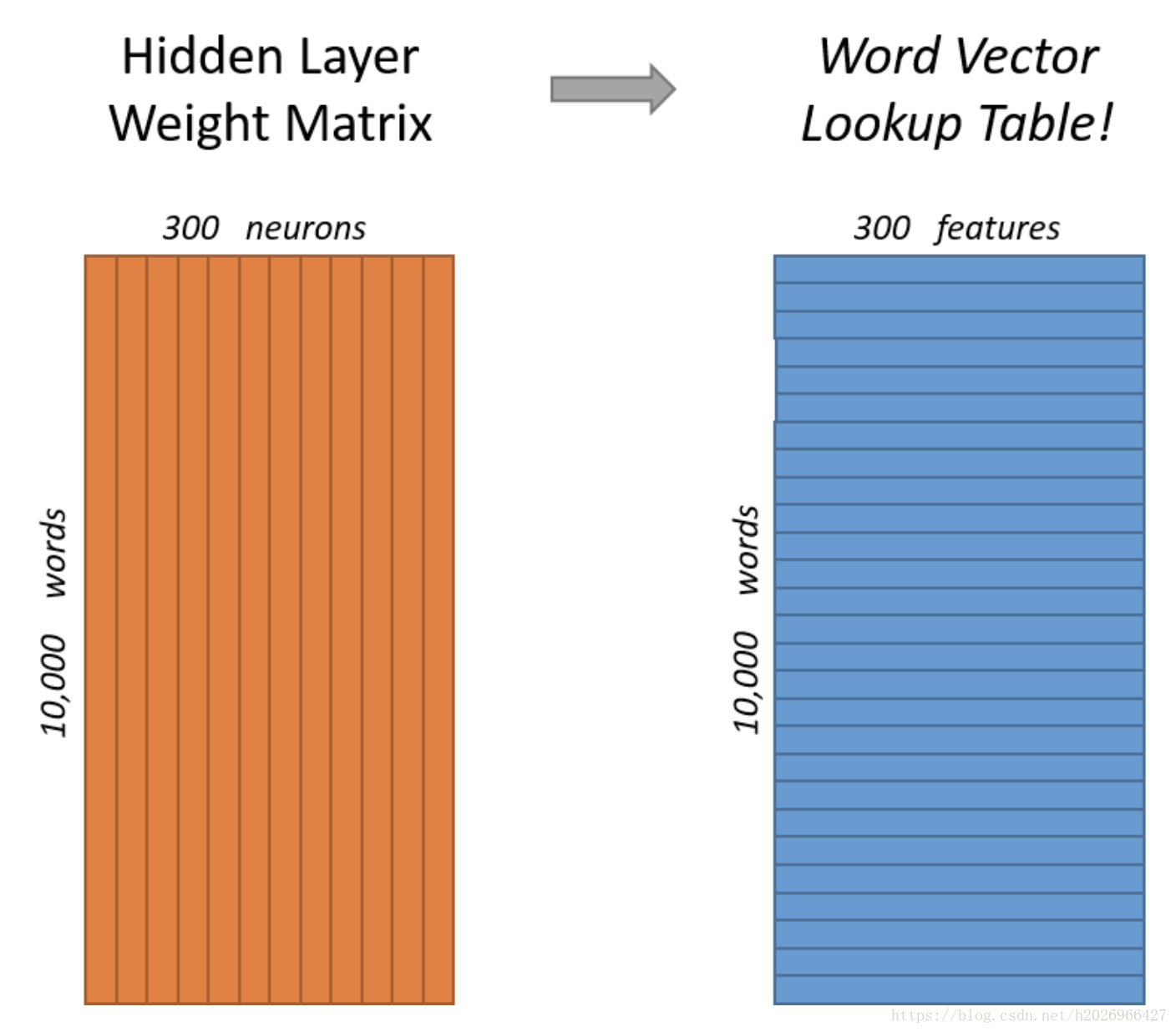
隐藏层的权重矩阵其实就是所要求的所有word vector合在一起的word vector matrix!
输出层每个神经元的意思如下:
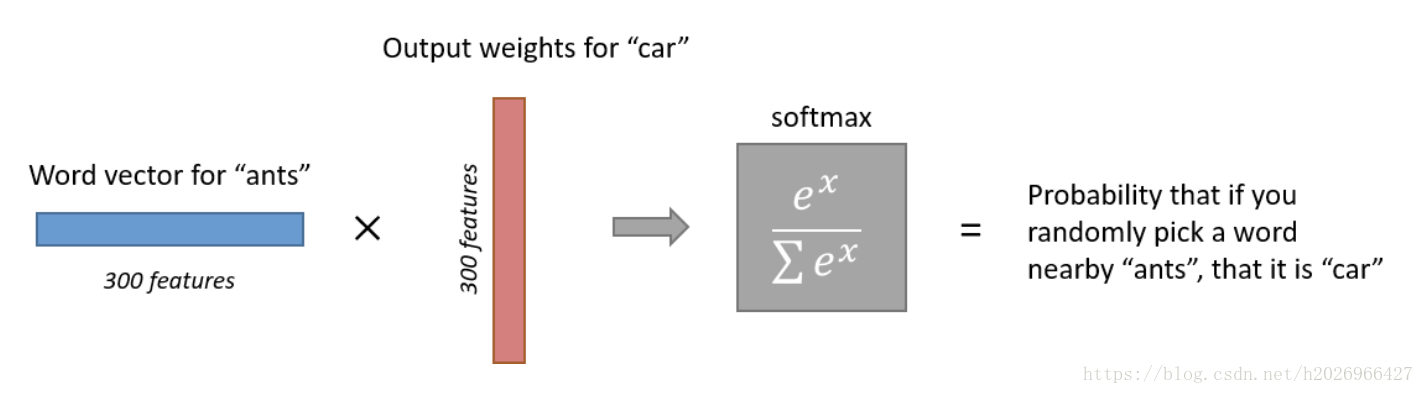
训练SG的核心如下:
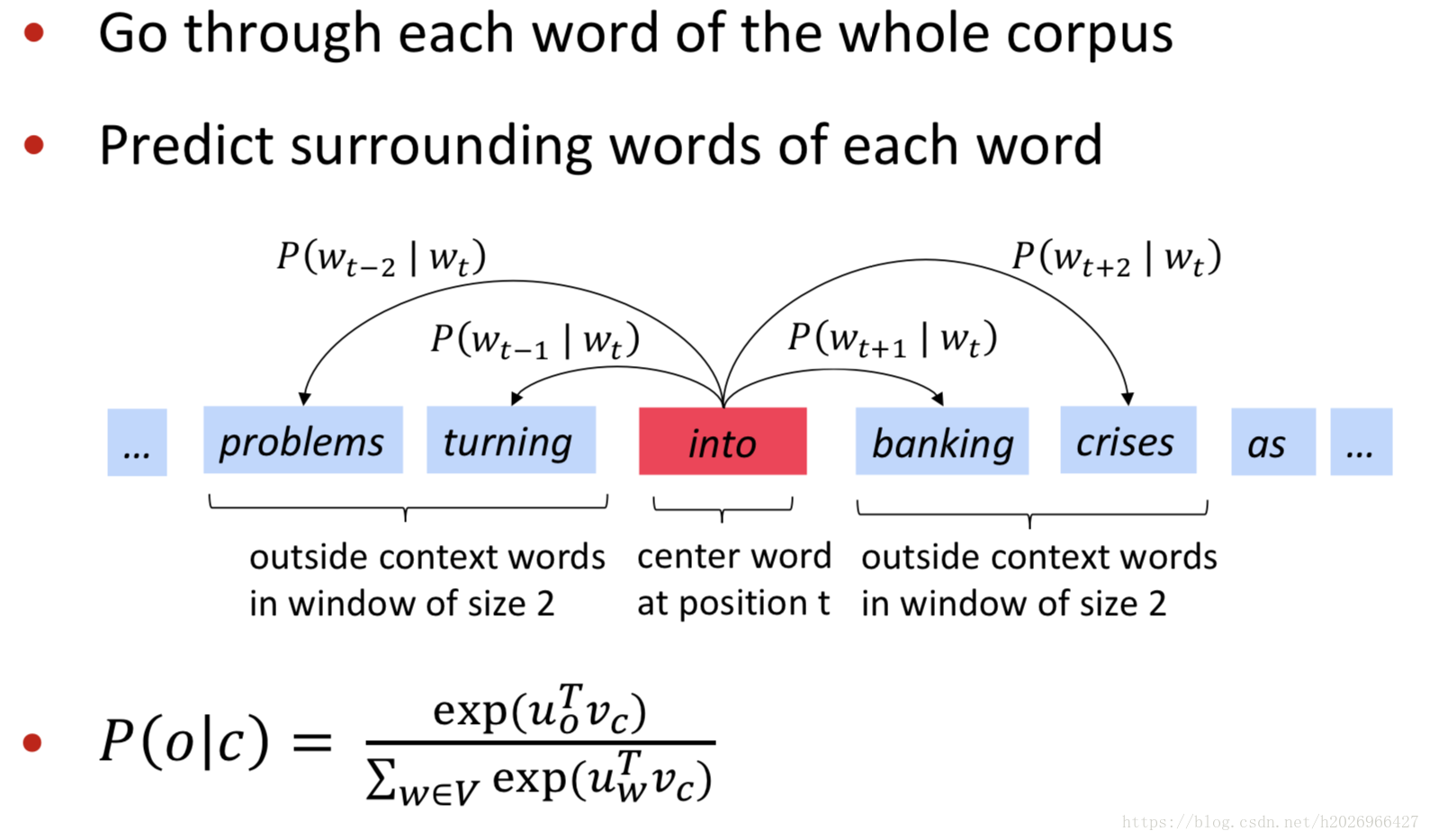
目标函数如下:
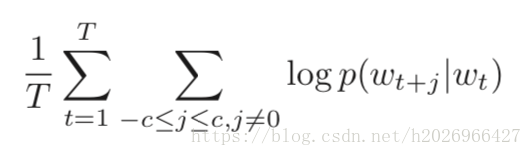
Skip-gram的训练语料需要经过如下的预处理:
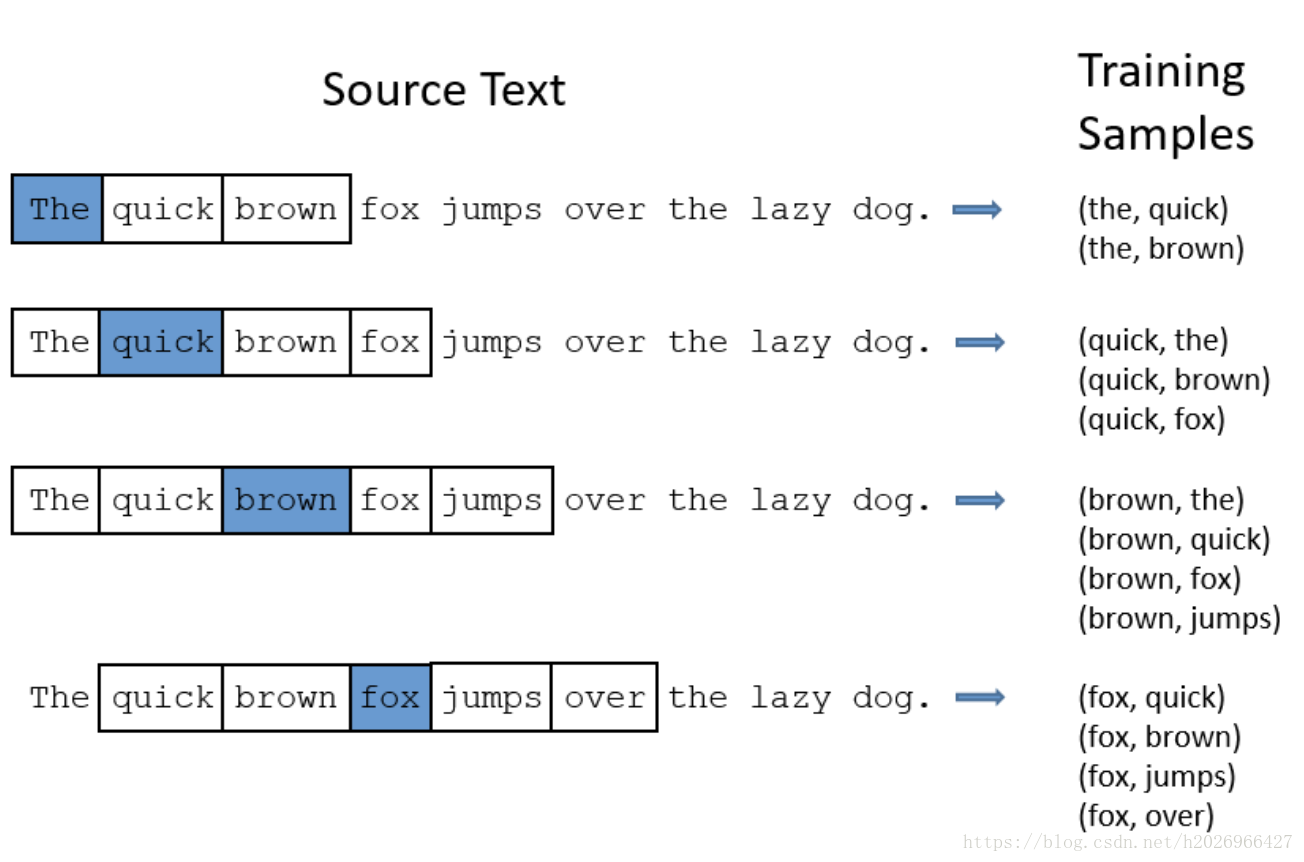
加速方法
为了提高word vector的质量,加快训练速度,Google提出了层次softmax和负采样的加速方法。普遍认为层次Softmax对低频词效果较好;负采样对高频词效果较好,向量维度较低时效果更好。
1,层次softmax
本质:把 N 分类问题变成 log(N)次二分类。
为了避免要计算所有词的softmax概率,word2vec采样了霍夫曼树来代替从隐藏层到输出softmax层的映射。
该方法不用为了获得最后的概率分布而评估神经网络中的W个输出结点,而只需要评估大约log2(W)个结点。层次Softmax使用一种二叉树结构来表示词典里的所有词,V个词都是二叉树的叶子结点,而这棵树一共有V−1个非叶子结点。一般采用二叉哈弗曼树,因为它会给频率高的词一个更短的编码。
如图所示:
2,负采样
本质:预测总体类别的一个子集。
让我们回顾一下训练的详细过程:每次用一个训练样本,就要更新所有的权重,这显然对于有大量参数和大量样本的模型来说,十分耗费计算量。但其实每次用一个训练样本时,我们并不需要更新全部的参数,我们只需要更新那部分与这个样本相关的参数即可。而负采样的思想就是每次用一个训练样本更新一小部分参数。负采样的意思是每次用的那个训练样本最后输出的值其实只有一个词的值是1,而其他不正确的词都是0,我们可以从那么是0的单词中采样一部分如5~20词来进行参数更新,而不使用全部的词。

负采样的目标函数:Maximize probability that real outside word appears, minimize probability that random words appear around center word.
参考
以下的参考博客解释得真的很棒!














 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









