








运行在Master节点上的第2个进程就是kube-controller-manager进程,即controller-manager server,kubernetes的核心进程之一,其主要目的是实现kubernetes集群的故障检测和恢复的自动化工作,比如内部组件EndpointController控制器负责Endpoints对象的创建和更新;ReplicationManager根据注册表中的ReplicationController的定义,完成Pod的复制或者移除,以确保复制数量的一致性;NodeController负责Minion节点的发现、管理和监控。
进程启动过程:
kube-controller-manager进程的入口源码位置如下:
kubernetes/cmd/kube-controller-manager/controller-manager.go
入口main()函数的逻辑如下:

从源码可以看出,关键代码只有两行,创建一个CMServer并调用Run方法启动服务。下面我们分析CMServer这个结构体,它是controller manager sever进程的主要上下文数据结构,存放一些关键参数,下表是对CMServer里的关键参数的解释。
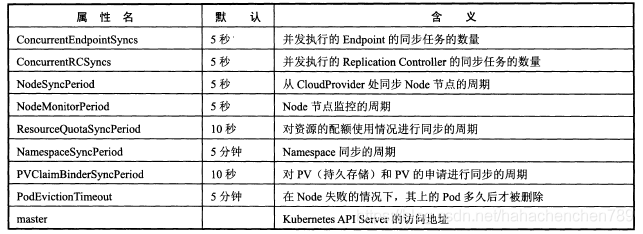
从上述这些变量来看,controller manager server其实就是一个超级调度中心,它负责定期同步Node节点状态,资源使用配额信息、replication controller、namespace、Pod的PV绑定等信息,也包括执行诸如监控Node节点状态,清除失败的Pod容器记录等一系列定时任务。
在controller-manager.go里创建CMServer实例并把参数从命令行传递到CMServer后,就调用其func(s* CMServer) Run(_ []string)方法进入关键流程,这里首先创建一个Rest client对象用于访问kubernetes API server提供的API服务:

随后,创建一个HTTP server以提供必要的性能分析和性能指标度量(metrics)的Rest服务:

我们注意性能分析的Rest路径是以/debug开头的,表面是为了程序调试所用,事实上的确如此,这里的几个profile选项都是针对当前Go进程的profile数据,比如我们在master节点上执行curl命令可以获取进程的当前堆栈信息,会输出如下信息:
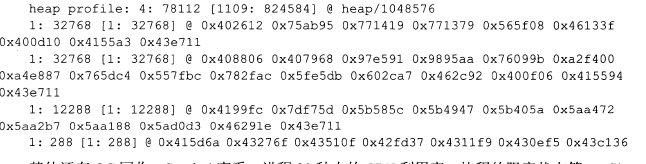
其他的还有GC回收,symbol查看,进程30秒内的CPU利用率、阻塞状态等profile功能,输出数据格式符合Google-perftools这个工具的要求,因此可以做运行期的可视化profile,以便排查当前进程潜在的问题或性能瓶颈。
性能指标度量目前主要收集和统计kubernetes API Server的Rest API的调用情况,执行curl,可以看到输出中包含大量类似下面的内容:

这些指标有助于协助发现controller manager server在调度方面的性能瓶颈,因此可以理解为什么要被包括到进程代码中去。
接下来,启动流程进入到关键代码部分。在这里,启动进程分别创建如下控制器,这些控制器的主要目的是实现资源在kubernetes API Server的注册表中的周期性同步工作:
1.EndPointController负责对注册表中的kubernetes service的endpoint信息的同步工作。
2.replicationmanager根据注册表中对replicationcontroller的定义,完成pod的复制或者移除,以确保复制数量的一致性。
3.Nodecontroller则通过cloudprovider的接口完成Node实例的同步工作。
4.servicecontroller通过cloudprovider的接口完成云平台中的服务的同步工作,这些服务目前主要是外部的负载均衡服务。
5.resourcequotamanager负责资源配额使用情况的同步工作。
6.namespacemanager负责namespace的同步工作。
7.persistentvolumeclaimbinder与persistentvolumerecycler分别完成persistentvolume的绑定和回收工作。
8.TokensController、ServiceAccountsController分别完成kubernetes服务的Token、account的同步工作。
创建并完成上述的控制器之后,各个控制器就开始独立工作,controller manager server启动完毕。
关键代码分析
上面分析可以看出,这个进程的主要逻辑就是启动一系列的控制器,这里以kubernetes中比较关键的Pod副本数量控制实现过程为例,来分析完成这个任务的控制器-replicationmanager具体是如何工作的。
首先,我们来看看replicationmanager结构体的定义:

在上述结构体里,比较关键的几个属性如下:
1.kubeclient,用来访问kubernetes API Server的Rest客户端,这里用来访问注册表中定义的ReplicationController对象并操作Pod。
2.podControl:实现了Pod副本创建的函数,其实现类为RealPodControl(位于/pkg/controller/controller_utils.go)。
3.syscHandler:是RC(ReplicationController)的同步实现方法,完成具体的RC同步逻辑,在代码中其被复制为ReplicationManager.syncReplicationController方法。
4.expectations:是pod副本在创建、删除过程中的流控机制的重要组成部分。
5.controllerstore:是一个具备本地缓存功能的通用的资源存储服务,这里存放framework.controller运行过程中从kubernetes API Server同步过来的资源数据,目的是减轻资源同步过程中对kubernetes API server造成的访问压力并提高资源同步的效率。
6.rcController:framework.controller的一个实例,用来实现RC同步的任务调度逻辑。
7.framework.controller:是kube-controller-manager里设计的用于资源对象同步逻辑的专用任务调度框架。
8.podstore:类似于controllerstore的作用,用来存储和获取Pod资源对象
9.podcontroller:类似于rccontroller的作用,用来实现Pod同步的任务调度逻辑。
理解了replicationmanager结构体的重要参数及其作用后,我们来看controller.newreplicationmanager()这个构造函数中的关键代码,注意到这通过调用framework.NewInformer()方法先后创建了用于RC同步及Pod同步的framework.controller。下面是framework.NewInformer()方法的源码:


在上述代码中,lw(listerwatcher)用来获取和检测资源对象的变化,而fifo则是一个deltaFIFO的queue,用来存放变化的资源(需要同步的资源)。当controller框架发现又变化的资源需要处理时,就会将新资源和本地缓存clientstate中的资源进行对比,然后调用相应的资源处理函数resourceeventhandler的方法,完成具体的处理逻辑。下面是针对RC的ResourceEventHandler的具体实现:

在上述源码中,我们看到当RC里Pod的副本数量属性发生变化后,ResourceEventHandler就将此RC放入ReplicationManager的queue队列中等待处理,为什么没有在这个handler函数中直接处理而是先放入队列再异步处理呢?最主要的一个原因就是pod副本创建过程中比较耗时。controller框架把需要同步的RC对象放入queue以后,接下来是谁在消费这个队列呢?
答案就在replicationmanager的Run()方法中:


上述代码首先启动rccontroller和podcontroller这两个controller,启动之后,这两个controller就分别开始拉取RC和Pod的变动信息,随后启动N个协程并发处理RC的队列,其中func Until(f func(), period time.Duration, stopCh <-chan struct{}>)方法的逻辑是按照指定的周期period执行方法f。下面是replicationmanager的worker方法的源码,负责从rc队列中拉取RC并调用rm的synchandler方法完成具体处理:
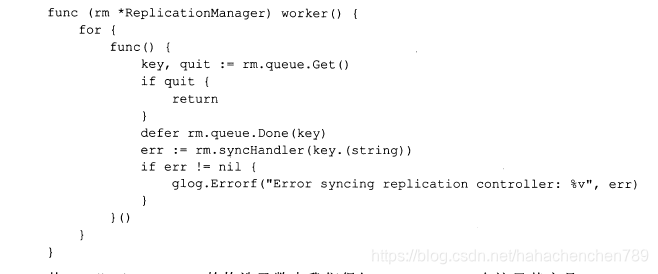
从replicationmanager(RM)的构造函数我们得知:synchandler在这里其实是func(rm *replicationmanager) syncReplicationController(Key string)方法,下面是该方法的源码:
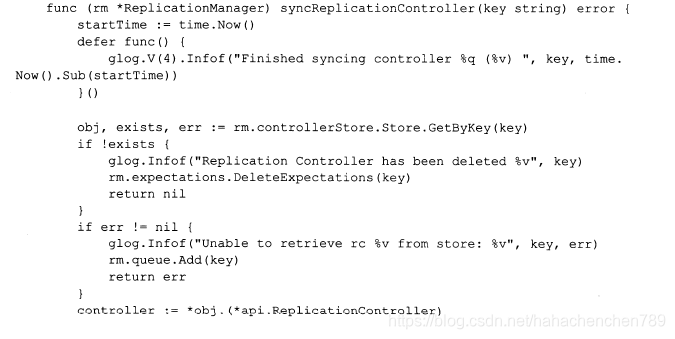

在上述代码里有一个重要的流控变量rcNeedsSync。为了限流,在RC同步逻辑的过程中,一个RC每次最多执行N个Pod的创建、删除,如果某个RC的同步过程涉及的Pod副本数量超过burstReplicas这个阈值,就会采用RCExpectations机制进行限流。RCExpectations对象可以理解为一简单的规则:即在规定时间内执行N次操作,每次操作都使计数器减1,计数器为0表示N个操作已经完成,可进行下一批次的操作了。
kubernetes为什么会设计这样一个流程控制机制?其实答案很简单—为了公平。因为谷歌的开发kubernetes开发者预见到某个RC的Pod副本数量一次扩容100倍的极端情况可能发生,如果没有流控机制,那么巨大的RC同步操作会导致其他散户崩溃。
接着看上述代码中所调用的replicationmanager的managerreplicas方法,这是RC同步的具体逻辑实现,此方法采用了并发调用的方式执行批量的Pod副本操作任务,相关代码如下:
![]()

追踪至此,我们才看到创建Pod副本的真正代码在Podcontrol.createreplica()方法里,而此方法的具体实现方法则是RealPodControl.createReplica(),位于controller_utils.go里。通过分析该方法,我们可以知道创建Pod副本的过程就是创建一个Pod资源对象,并把RC定义的Pod模板赋值给该Pod对象,并且Pod的名字用RC的名字做前缀,最后调用kubernetes client将Pod对象通过kubernetes API Server写入后端的etcd存储中。
首先,在controller框架中构建了reflector对象以实现资源对象的查询和监听逻辑,其源码位于pkg/client/cache/reflector.go中,我们看一下这个对象的数据结构就基本明白了其工作的原理:


核心思路就是通过listerwatcher去获取资源列表并监听资源变化,然后存储到store中。这里可能会有疑问,这个store究竟是什么对象?是replicationmanager里的controllerstore还是framework.NewInformer()方法里创建的fifo队列?
下面两段来自pkg/controller/framework/controller.go代码会告诉答案:
首先是来自controller的run方法:

然后是来自controller的NewInformer方法func NewInformer(lw cache.ListerWatcher, objType runtime.Object, resyncPeriod time.Duration, h ResourceEventHandler,)的代码片段:

分析上述代码可以发现,reflector的store其实是引用controller.config的queue属性,即fifo队列,而非replicationmanager里的controllerstore。
下面这段代码是controller从队列queue中拉取资源对象并交给controller.config对象中的process方法进行处理,从而最终完成整个controller框架的闭环过程。

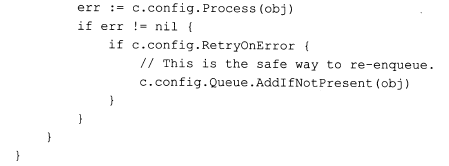
至于上述过程的调用则是在controller启动(run方法)的最后一步里,controller框架定时每秒调用一次上述函数,代码如下:
![]()
总结:
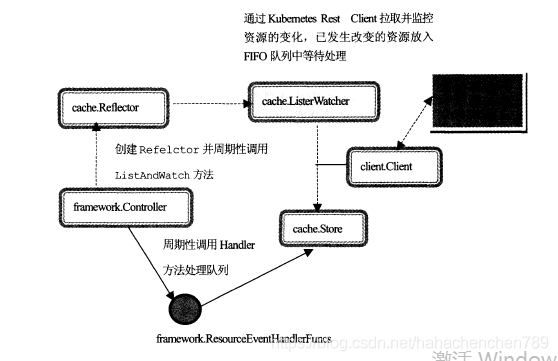
kubernetes controller server中的精华—controller framework的内部维护了一个config对象,保留了一个标准的消息、事件分发系统的三要素。
1.生产者:cache.ListerWatch
2.队列:cache.cacheStore(Queue)
3.消费者:用回调函数来模拟(framework.resourceEventHandlerFuncs)
整体架构设计图如下:














 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









