







转自:https://nicehuster.github.io/2019/06/12/fine-grain/
一般而言,图像识别分为两种:传统图像识别和细粒度图像识别。前者指的是对一些大的类别比如汽车、动物、植物等大的类别进行分类,这是属于粗粒度的图像识别。而后者则是在某个类别下做进一步分类。比如在狗的类别下区分狗的品种是哈士奇、柯基、萨摩还是阿拉斯加等等,这是属于细粒度图像识别。
数据集
在细粒度图像识别领域,经典的基准数据集包括:
- 鸟类数据集CUB200-2011,11788张图像,200个细粒度分类
- 狗类数据集Stanford Dogs,20580张图像,120个细粒度分类
- 花类数据集Oxford Flowers,8189张图像,102个细粒度分类
- 飞机数据集Aircrafts,10200张图像,100个细粒度分类
- 汽车数据集Stanford Cars,16185张图像,196个细粒度分类
细粒度图像分类作为一个热门的研究方向,每年的计算机视觉顶会都会举办一些workshop和挑战赛,比如Workshop on Fine-Grained Visual Categorization和iFood Classification Challenge。
挑战
上图展示的是CUB20鸟类数据集的部分图片。不同行表示的不同的鸟类别。很明显,这些鸟类数据集在同一类别上存在巨大差异,比如上图中每一行所展示的一样,这些差异包括姿态、背景等差异。但在不同类别的鸟类上却又存在着差异性小的问题,比如上图展示的第一列,第一列虽然分别属于不同类别,但却又十分相似。
因此可以看出,细粒度图像识别普遍存在类内差异性大(large intra-class variance)和类间差异性小(small inter-class variance)的特点。
方法
细粒度图像识别同样是作为图像分类任务,因此也可以直接使用通用图像识别中一些算法来做,比如直接使用resnet,vgg等网络模型直接训练识别,通常在数据集上,比如CUB200上就可以达到75%的准确率,但这种方法离目前的SOTA方法的精度至少差了10个点。
目前细粒度图像识别方法大致可以分为两类:
1.基于强监督学习方法:这里指的强监督信息是指bounding box或者landmark,举个例子,针对某一种鸟类,他和其他的类别的差异一般在于它的嘴巴、腿部,羽毛颜色等
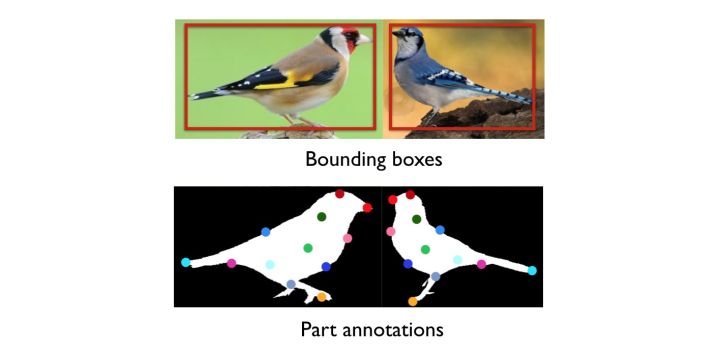
主流的方法像Part-based R-CNN,Pose Normalized CNN,Part-Stacked CNN等。
2.基于弱监督学习方法:什么是弱监督信息呢?就是说没有bounding box或者landmark信息,只有类别信息,开山之作应该属于2015年Bilinear CNN,这个模型当时在CUB200上是state of the art,即使和强监督学习方法相比也只是差1个点左右。
关于前几年细粒度图像分析的综述,可以参考这里。由于强监督学习方法中对于大规模数据集来说,bounding box和landmark标注成本较高,因此,现在主流的研究方法都是是基于弱监督学习方法。
下面是我要介绍的近1/2年来比较有代表性的顶会paper,这些paper都是基于弱监督信息,自主去挖掘Discriminative Region。
Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition
代码链接:https://github.com/Jianlong-Fu/Recurrent-Attention-CNN
这篇文章是CVPR2017的一篇oral paper。细粒度图像识别的挑战主要包括两个方面:判别力区域定位以及从判别力区域学习精细化特征。RA-CNN以一种相互强化的方式递归地学习判别力区域attention和基于区域的特征表示。具体模型结构如下:
主要思路
如上图,每一行表示一个普通的CNN网络,
(1)图片a1进入b1(堆叠多个卷积层)之后,分成两个部分,一个部分到c1连接fc+softmax进行普通的分类;另一个部分进入d1,Attention Proposal Network得到一个region proposal。
(2)在原图上利用d1提出的region proposal,在原图上crop出一个更有判别性的小区域,插值之后得到a2,同样的道理得到a3。
可以看出特征区域经过两个APN之后不断放大和精细化,为了使得APN选取的特征区域是图像中最具有判别性的区域,作者引入了一个Ranking loss:即强迫a1、a2、a3区域的分类confidence score越来越高(图片最后一列的对应Pt概率越来越大)。这样以来,联合普通的分类损失,使网络不断细化discriminative attention region。
部分细节
attention 定位和放大
作者使用二维boxcar函数作为attention mask与原图相乘得到候选区域位置。这样做的目的在于实现APN的端对端训练。因为普通的crop操作不可导。
损失函数
该模型的损失函数包含两个部分,一部分是每一路经过fc和softmax之后的一个分类误差;一部分是Ranking loss使得越精细化的区域得到了置信度分数越高。
对于ranking loss,![]()
在训练的过程中,迫使p(s+1)t>p(s)tpt(s+1)>pt(s)。
实验结果
在CUB-200-2011数据集上

Pairwise Confusion for Fine-Grained Visual Classification
代码链接:https://github.com/abhimanyudubey/confusion
这是ECCV2018的一篇文章,这篇文章提出了一种Pairwise Confusion正则化方法,主要用于解决在细粒度图像分类问题上类间相似性和样本少导致过拟合的问题。在通用图像分类问题上,由于数据集一般较大,直接使用交叉熵损失函数就可以迫使网络学习类间差异性。然而对于细粒度图像分类问题而言,数据集小,且普遍存在类间差异较小,类内差异较大的特点。假如对于两张鸟类图像样本,内容相似却有着不同的标签,直接最小化交叉熵损失将会迫使网络去学习图像本身的差异比如一些差异性较大的背景,而不能很好的挖掘不同鸟类的细粒度区别。

因此,作者提出了Pairwise Confusion方法 ,网络结构如上图所示。网络采用Siamese结构共享权值,对于一个Batch的图片会分成两部分,组成很多“图片对”,如果这些图片对属于相同的label,那么就把两张图片分别求Cross entropy loss;如果有一对图片属于不同的label,那么在分别对他们求Cross Entropy Loss的同时还要附加一个Euclidean Confusion作为惩罚项
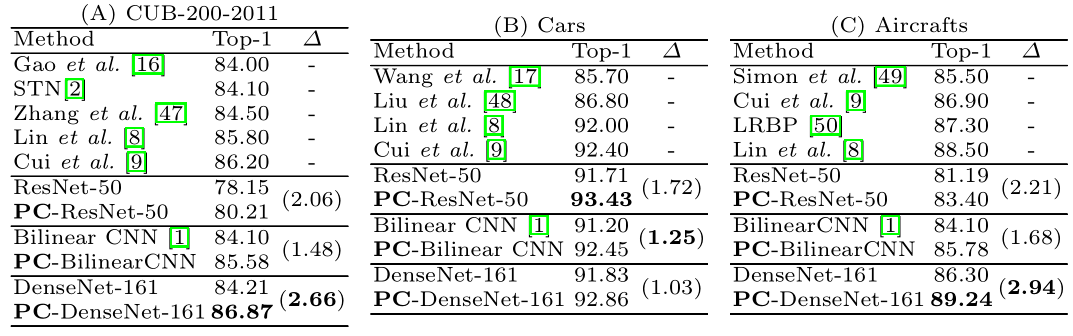
论文的主要出发点还是制约不同类别图片表示的特征向量之间的距离。作为一个涨点的trick。可以加在任何细粒度识别算法中。下面是一些实验对比结果,可以看出,添加PC之后在每个数据集都能带来1-2个点。
Learning to Navigate for Fine-grained Classification
代码链接:https://github.com/yangze0930/NTS-Net
这也是ECCV2018的文章,这篇文章借鉴了RPN的思路,通过在原图上生成anchors,利用rank loss选出信息量最大的一些proposal,然后crop出这些区域,和原图一起提取特征然后进行决策判断。这是这篇文章方法的一个大致结构。
Navigator
这个结构和FPN类似,在三个不同尺度的feature map上生成候选框,Navigator就是给每一个候选区域的“信息量”打分,信息量大的区域分数高。
Teacher















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









