









原文地址: http://docs.ceph.com/docs/master/architecture/
ceph独特的在统一的系统中提供了对象、块和文件三种存储接口。ceph是高可靠,容易管理,并且是免费的。ceph能够改变你的公司的IT基础设施,并且提供管理海量的数据的能力。ceph提供了非常高的可扩展性–成千上万的客户端可访问PB到EB级别的数据量。ceph节点由普通的硬件和智能的软件组成,一个ceph存储集群包含了大量的这些节点,这些节点互相之间通信以动态地复制和重新分配数据。
ceph存储集群
ceph基于RADOS提供了一个无限可扩展性的存储集群。一个ceph存储集群包含两种类型的服务进程:
* ceph monitor
* ceph osd daemon
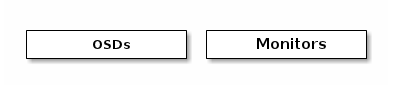
ceph monitor维护了标准的cluster map。monitor的集群在一个monitor失效时保证了系统高可用。存储集群客户端从monitor中获取1份cluster map的备份。ceph osd检查自身和其他相关的OSD的状态(同一个PG),并将状态上报到monitor。
存储集群客户端和OSD都使用CRUSH算法高效地计算数据存放位置,取代一个中心查找表。ceph的高级特性包括提供原生态的接口librados,并且在librados的基础上提供了一系列的接口。
数据存储
ceph存储集群从ceph客户端接收数据,无论客户端是block device,object storage,filesystem或者是自定义的实现(基于librados),ceph以对象为单位存储这些数据。每个object对应一个存储在OSD上的文件。ceph OSD服务进程磁盘的读写操作。
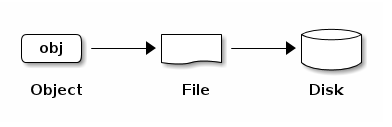
ceph OSD服务进程在一个扁平的命名空间内把所有的数据作为对象来存储(比如没有目录层级)。对象包含唯一标识,二进制数据和一组名字/值的元数据。对象的这层语言完全传递个客户端。例如,CephFS使用元数据去存储文件属性,如文件拥有者,创建时间,最后修改时间等。

Note:一个object id在整个集群是唯一的,而不是本地文件系统内。
可扩展性和高可用性
在传统的架构中,客户端需要与一个中心组件通信(如gateway,broker, API,facade等),这些中心组件便是整个子系统的单点。这样会有性能和扩展性的限制,也引入了系统的单点。(中心组件失效,整个系统也将失效。)
ceph排除了中心网关,使客户端直接与OSD进行通信。ceph osd服务进程通过在别的ceph OSD中创建object的备份,以保证数据安全和高可用性。ceph也使用monitor集群确保高可用性。为了去除中心节点,ceph使用了CRUSH算法。
CRUSH介绍
ceph 客户端和ceph OSD服务进程都使用CRUSH算法,高效地计算object的存储位置,取代了依靠一张中心的查询表。CRUSH相比于老的方法提供了更好的数据管理机制,通过清晰地分配负载到集群中所有的客户端和OSD服务进程使得集群能到达一个巨大的规模。CRUSH使用智能数据备份确保数据弹性,更合适超大规模的存储。接下来的章节提供额外的CRUSH说明。对于CRUSH更细致的讨论,看CRUSH论文:CRUSH - Controlled, Scalable, Decentralized Placement of Replicated Data。
CRUSH MAP
ceph依赖于ceph client和ceph osd服务进程都知道集群的拓扑,这5张map描述了集群拓扑,被称为“cluster map”。
* MON map:包含集群fsid,每个monitor的位置,名字和端口。也包含了当前epoch,map创建时间,最后修改时间。查看monitor map的命令:ceph mon dump 。
* OSD map : 包含集群fsid,map创建时间,最后修改时间,pool列表,备份数量,PG数量,OSD列表及其状态。查看osd map的命令: ceph osd dump 。
* PG map : 包含PG版本,时间戳,最新的OSD map的epoch,完整的比率,每个PG的细节:PG id、up集合、acting集合、PG状态(eg. active + clean),和每个pool的数据使用统计。
* CRUSH map : 包含存储设备列表,失效域层级结构(eg. device, host, rack, row, room, etc), 存储数据时遍历各个层级的规则。查看CRUSH map的命令: ceph osd getcrushmap -o {filename} ; 然后反编译该文件: crush -d {comp-crushmap-filename} -o {decomp-crushmap-filename}。可以使用cat命令来查看该反编译的map文件了。
* MDS map :包含当前MDS map的epoch, 创建时间,上次修改时间,包含存储元数据的pool, mds列表,每个mds是up或in。查看MDS map的命令:ceph mds dump 。
每个map维护操作状态改变的迭代历史版本。ceph monitors维护cluster map的主备份包括集群成员,状态,改变和所有存储集群的健康状态。
高可用性的monitor
ceph客户端在读写数据之前,它们必须要从ceph monitor中获取最近的cluster map备份。ceph存储集群允许使用单个monitor,然而这会引入集群的单点故障。(monitor挂了,ceph客户端无法读取数据)
为了增加可靠性和错误容忍性,ceph支持monitor集群。在monitor集群中,延迟或者别的错误会导致1个或者更多的monitor的cluster map版本落后于当前版本。因此ceph必须在不同的monitor中取得集群状态的一致性认识。ceph总数使用多数的monitor(eg. 1, 2:3 , 3:5, 4:6),和使用Paxos算法在多个monitor中取得集群当前状态的一致性。
高可用性的认证
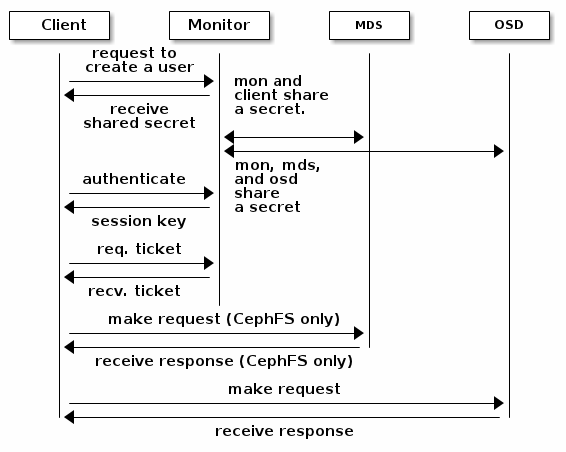
为了识别用户和防御中间人的攻击,ceph提供cephx认证系统,来验证用户和守护进程。
Note:cephx协议不会再传输过程中进行数据加密,也不会进行静态加密。
cephx 使用共享秘钥进行验证,意味着客户端和monitor集群都拥有相同备份的客户端秘钥。认证协议只是需要双方证明它们拥有相同秘钥的备份,而不是要透露这份秘钥。 这提供了共同验证机制,意味着集群确定用户持有的秘钥和集群拥有的秘钥是相同的。
ceph的秘钥扩展性特点是为了避免集群中有一个中心化的接口,这意味着ceph客户端必须能够直接更OSD通信。为了保护数据,ceph提供cephx认证系统,去验证操作ceph客户端的用户。cephx协议的验证方式与Kerberos类似。
用户请求ceph客户端去联系一个monitor,不像Kerberos,每个monitor能够验证用户和分发秘钥,这样使用cephx的时候不会存在单点故障和性能瓶颈。monitor返回一个认证的数据结构这与kerberos的ticket相同,该数据结构包含一个用来获取ceph服务的session key。这个session key是自身与用户的永久秘钥一起加密,所以只有用户能够向monitor请求服务。客户端使用session key去向monitor请求需要的服务,并且monitor提供客户端一个ticket,这个ticket将允许客户端到OSD中处理数据。ceph monitor和OSD共享一个秘钥,所以客户端能使用由monitor提供的ticket与同一个集群内任意一个OSD或MDS通信。就像Kerberos,cephx ticket有过期机制,所以一个攻击者无法使用一个过期的ticket或session key偷偷获取数据。这种形式的验证机制在确保秘钥在其过期之前不被泄露,即能防止攻击者以别的用户的名义创建伪造消息,又防止其更改合法用户的消息。
使用cephx,首先需要建立一个管理员用户,在下面的图中,用户client.admin使用命令ceph auth get-or-create-key创建一个用户及秘钥。ceph auth子系统生成用户和秘钥,并且存储在每个monitor中,并将用户秘钥传回client.admin。这意味着客户端与monitor共享一份秘钥。
Note: client.admin用户必须以安全的方式提供用户ID和秘钥给其他用户。
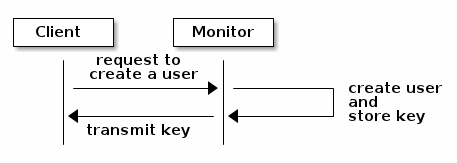
客户端传递用户名到monitor中进行验证,monitor生成一个session key并将其与该用户的秘钥一起加密。之后monitor传输这个已加密的session key到客户端。客户端将收到的加密session key进行解密,并使用秘钥去检索出session key。这个session key在当前的session中识别用户。客户端向monitor请求ticket,该ticket代表用户通过session key授权。monitor收到请求后将生成并加密该ticket,并将其返回给客户端。客户端解密该ticket,并使用它去标记发送给集群OSD和MDS的请求。
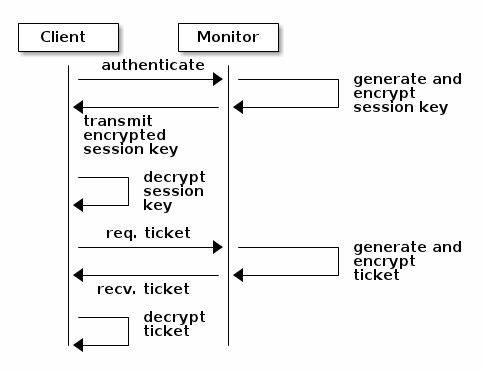
cephx协议认证正在通信的客户端和ceph server。在初始认证之后的每个消息都使用ticket进行标识,ceph集群中的OSD,MDS和MON都能使用它们的共享key来认证。
ceph认证机制只提供了ceph client到ceph server的保护,该机制不会延生到访问ceph client的机器。
智能守护进程使能超大规模集群
对于许多集群架构,都有一个中心接口知道哪些节点可以访问。该中心接口为客户端提供服务,但是对于PB级的规模这将是一个巨大的瓶颈。
ceph排除了这个瓶颈,cepp的OSD和ceph客户端都清楚知道集群架构,每个OSD都知道集群中其他的OSD。这使得ceph OSD能够直接与别的OSD,MON,MDS通信。尤其是可以使得客户端能够与OSD直接通信。
客户端,OSD,MON,MDS能够直接通信的能力,使得OSD能够利用CPU和RAM去执行那些会阻塞中心服务的任务。这种分布的计算有几个优势:
* OSD直接服务客户端:由于网络设备能支持的并发数有一个限制,中心化的系统便拥有了一个低门槛的物理设备限制。通过客户端与OSD直接通信,ceph从性能和系统容量都有了提升,并且排除了单点故障。ceph客户端在它需要时可以维持一个session,使用了ceph OSD取代了中心节点。
* OSD的成员关系和状态:ceph OSD加入集群时会上报自身状态。在最低的层次,ceph OSD状态只有up或down,反映它是否运行并能够处理客户端请求。如果ceph OSD在集群中的状态是down和in,这个状态表示这个OSD可能出现故障。如果一个ceph OSD没有运行(如崩溃了),该OSD不能通知MON它自身的状态为down。MON能够定期地ping每个OSD,确保OSD是否运行。ceph也使得OSD去检测它的邻居OSD是否down了,去更新cluster map和上报到MON。这意味着monitor能够保持轻量级进程。
* 数据整理:作为数据一致性和清洁度的参与者,OSD能够清理PG的object。OSD能够比较一个PG中的object元数据和其他OSD上的备份。清理过程(通常每天执行一次)去捕获bug和文件系统错误。OSD也执行深度的清理,一个bit一个bit地对比数据。深度清洗(通常一周一次)找到坏的磁盘扇区。
* 备份:类似ceph客户端,OSD使用CRUSH算法,但是OSD使用CRUSH去计算object备份应该存储的位置。对于典型的写应用场景,客户端使用CRUSH算法计算出存储object的位置,映射object到pool的一个PG,这看起来像,查找CRUSH map可以识别PG的主OSD。客户端写object需要找到PG的主OSD,然后主OSD使用自己那份CRUSH map识别到备份的OSD,然后Primary PG向备份节点进行数据的拷贝,当Primary PG确定数据成功存储后响应客户端请求。
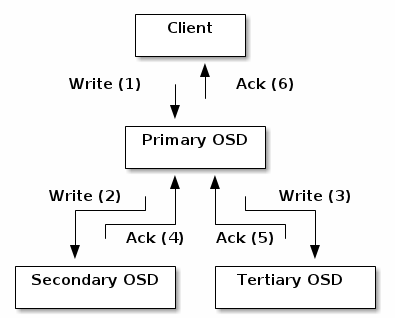
以这种数据备份的方式,ceph OSD在确保数据可用性和数据安全性方面,减轻了客户端的责任。
动态集群管理
在扩展性和高可用性的章节中,我们解释了ceph使用CRUSH算法,集群感知和智能守护进程以达到高扩展性和维持高可用性。ceph的关键设计是自治的,自我修复的和智能的OSD守护进程。我们将深入地了解CRUSH如何使得现代云基础架构放置数据,重平衡集群,和动态错误恢复。
关于POOL
ceph存储系统支持pool的概念,pool是存储object时的逻辑划分。ceph客户端从MON中获取一份cluster map,并将object写入pool中。pool的大小或备份的数量,CRUSH的规则集合,PG的数量,这些数据决定了数据的具体存放位置。
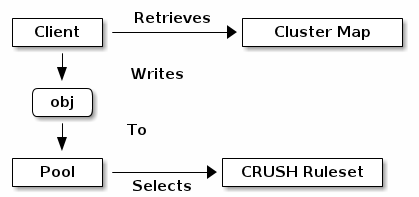
pool至少设置里如下参数:
* 所有者/可访问object的用户
* PG的数量
* 使用的CRUSH规则
PG到OSD的映射
每个pool都拥有一定数量的PG。CRUSH动态地映射PG到OSD。当客户端存储object的时候,CRUSH将会映射每个object到一个PG。
映射object到PG在客户端和OSD之间引入了一个中间层。ceph集群必须能动态地增加,减少和重平衡它所存储的数据。如果客户端知道哪个OSD拥有哪个object,这样将使得客户端和OSD紧密结合。CRUSH算法映射每个object到一个PG,映射每个PG到一个或多个OSD。这个中间层允许ceph在新的OSD加入或OSD失效恢复时,实现动态重平衡。下图描述了CRUSH如何映射object到PG,和PG如何映射到OSD。
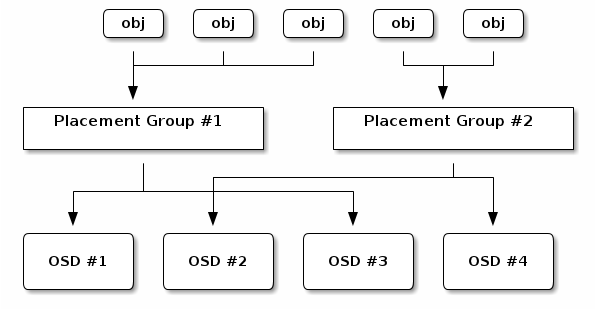
根据cluster map和CRUSH算法,客户端能够精确计算到对特定的object应该到哪个OSD上进行读写。
计算PG IDS
当客户端连接上(bind)一个MON时,它将重新获得一份最新的cluster map。通过cluster map,客户端知道集群中所有的MON,OSD,MDS。但是,它不知道具体的object存放位置。对象的存储位置是被计算出来的。
- 客户端输入pool id和object id。(eg. pool = “liverpool” object-id = “john”)
- ceph使用object id,使用hash计算出一个值。
- 对计算的hash值,以该pool的PG数量进行取模,得到PG ID。
- ceph根据pool名称得到pool id,查map。
- ceph预先知道pool id和PG id(eg. 4.58 pool_id.pg_id)
计算object的位置要比去查询中心节点的方式要快得多。CRUSH算法允许客户端计算object存储位置,并且使客户端直接与primary OSD通信,存储数据和检索数据。
peering 和 sets
在之前的章节,我们注意到ceph OSD会心跳检测其他的OSD并将检测结果上报到Ceph MON。OSD还会做一件叫做peering的事情,peering就是在同一个PG下所有的OSD的所有的object的状态取得一致性的过程。如果peering失效,Ceph OSD向ceph MON报告。Peering问题通常由OSD自己解决。如果问题一直存在,查看章节Troubleshooting Peering Failure
Note: 状态的一致并不表示PG拥有最新的内容。
ceph存储集群设计成每个object最少有两个备份,这是保证数据安全的最小要求。对于高可用性,ceph存储集群应该设置超过两个备份,这样即使在PG降级状态仍然能够保证数据的安全。
回顾智能守护进程使能超大规模集群章节的图表,我们没有给OSD指定名字(eg. osd.0, osd.1),而是宁愿以Primary,Secondary的方式进行引用。按照惯例,Primary是一组OSD(同一个PG下)的第一个OSD,负责PG的peering过程,也是唯一面向客户端写操作的OSD。
同一个PG下的一组OSD,我们称之为Acting Set。一组Acting Set可能是指当前对该PG负责的这组OSD。Acting Set中的OSD可能不总是up状态。当OSD在一个up状态的Acting Set,它就是up状态Set的一部分。up set是一个重要的分界线,因为但OSD失效时,ceph能够重映射PG到其他的OSD。
Note:一个PG的Acting Set包括了osd.25,osd.32和osd.61。第一个OSD,osd.25作为Primary,如果该OSD失效后,第二个OSD,osd.32成为Primary,并且osd.25将从up set中移除。
重平衡
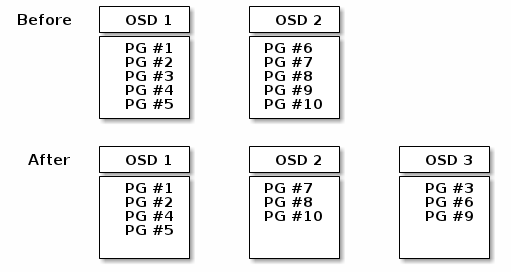
当一个OSD加入ceph存储集群时,cluster map根据该OSD进行更新。回顾计算PG IDS章节,这改变了cluster map。因此,这也改变了object的位置,因为它将改变计算的输入。下面的图表描述的重平衡过程。虽然相当粗鲁,并且实质上对于大的集群会产生更少的影响。不是所有的PG都要从已存在的OSD(OSD 1, OSD 2)迁移到新的OSD(OSD 3)。即使在重平衡的过程中,CRUSH也是稳定的。许多PG依旧保持在原来的配置,每个OSD获得一些附加存储空间,所以对于新加入的OSD没有负载,直到重平衡操作完成。
数据一致性
作为维护数据一致性和数据清洁度的一部分,OSD能够整理(scrub)PG中的object。就是说,OSD能够比较同一个PG下别的OSD一个object多个备份之间的元数据。整理(scrub)通常每天执行一次,将捕获OSD的bugs和文件系统错误。ceph也能执行深度整理(scrub)通过比较object中的每个bit。深度整理(scrub)通常每周执行一次,找到损坏的磁盘扇区。
纠删码
一个纠删码pool存储每个object分成K+M个chunk。它将分成K分数据chunk和M分校验chunk。当一个pool配置成K+M,以至于每个chunk存储在Acting Set的一个OSD中。这些chunk的存储顺序作为该object的一个属性。
举个例子,创建一个纠删码pool使用5个OSD(K+M = 5),能够容忍丢失其中两份chunk(M = 2)。
读写纠删码chunk
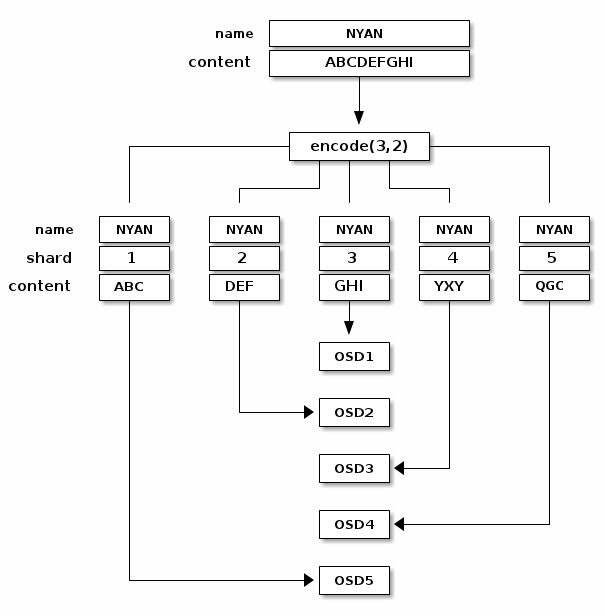
当对象NYAN包含ABCDEFGHI被写入到上面的pool中,纠删码编码函数将数据简单分成3个chunk:第一个chunk包含ABC,第二个包含DEF,第三个包含GHI。如果原数据的长度不是K的整数倍,将会对数据进行填充。纠删码编码函数也会生成两个校验chunk:第四个chunk包含YXY,第五个包含GQC。每个chunk存储在一个Acting Set的不同的OSD中。每个chunk以相同名字(NYAN)的object存储在不同的OSD中。chunk的顺序在创建时必须保存,将其存储在object的属性(shard_t)中, 每个chunk都存储它自己在整个object的序号。chunk 1包含ABC,存储在OSD5,而chunk 4包含YXY存储在OSD3。
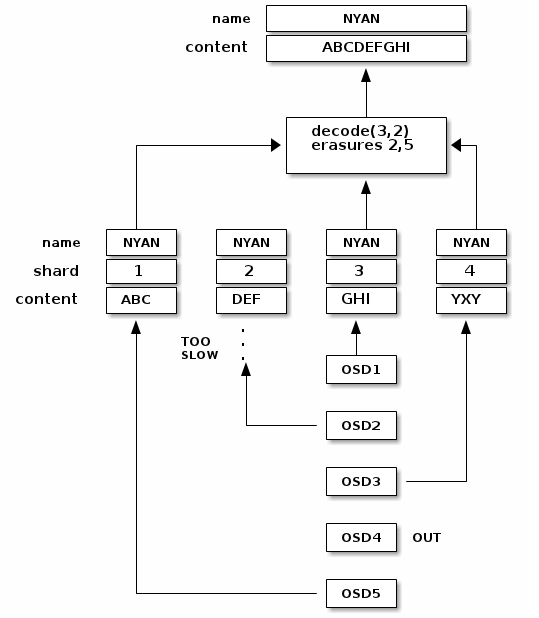
当object NYAN从纠删码池子里读出时,纠删码解码函数将读出3个chunk:chunk 1包含ABC,chunk 3包含GHI,和chunk 4包含YXY。然后,它重建原始数据内容ABCDEFGHI。纠删码解码函数能够在丢失chunk 2和5的时候能正常工作(叫做‘erasures’)。chunk 5不应该去读取因为OSD4是out状态。一旦读取到3个chunk,纠删码解码函数被调用:OSD2是响应最慢的,这个chunk也没有加入进行解码。
被中断的满写
在一个纠删码池子,在up set中的Primary OSD接收所有写操作。它将承担编码K+M个chunk和将这些chunk发送到其他OSD的负载。Primary OSD也将维护权威版本的PG log。
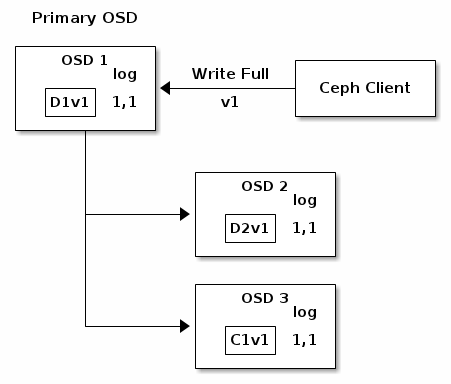
下面一张图中,一个纠删码编码(K = 2, M =1)的PG被创建,由3个OSD提供支撑。该PG的Acting Set由OSD 1,OSD 2和OSD 3组成。一个object被编码和存储在OSD中:chunk D1v1(i.e. Data chunk number 1, version 1)存储在OSD 1中,D2v1在OSD2中,C1v1(i.e. Coding chunk number 1, version 1)在OSD3中。每个OSD上的PG log是相同的(i.e. 1, 1 for epoch 1, version 1)。
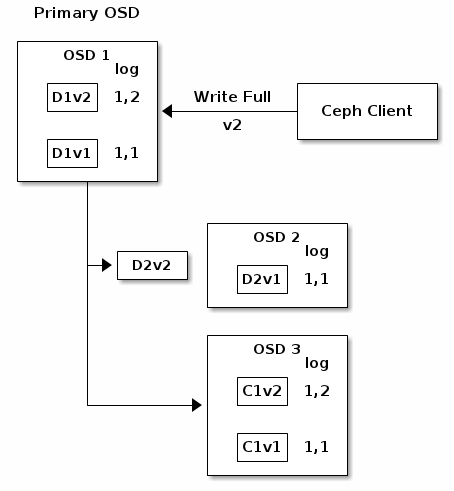
OSD 1是Primary,并从客户端中接受一个WRITE FULL,这意味着需要去替换一个完整的object而不是重写object的一部分。使用 Version 2(v2)的object覆盖Version 1(v1)的object。OSD 1将该object编码成3个chunk:D1v2(i.e Data chunk number 1 version 2)将会存储到OSD 1中,D2v2将被存到OSD 2中,C1v2(i.e. Coding chunk number 1 version 2)存储到OSD3中。每个chunk被传输到目标OSD中,包括接收所有写操作,并且维护权威的PG log的Primary OSD。当一个OSD接收写chunk操作的消息,它将在PG Log创建一条新的记录,来反映这个改变。例如,一旦OSD 3存储C1v2,它将增加记录1, 2(i.e. epoch 1, version 2)到它的PG Log。因为OSD工作是异步的,一些chunk(D2v2)可能还在迁移的过程中,其他(C1v1和D1v1)已经写入磁盘了。
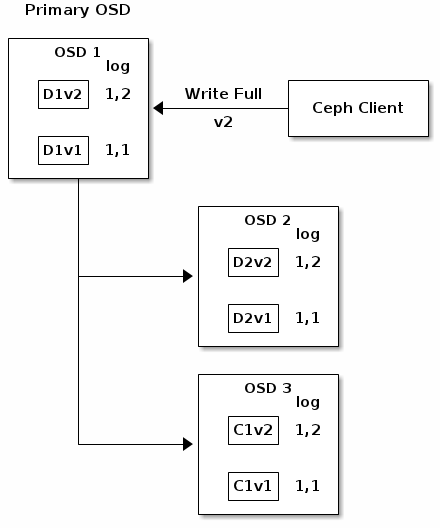
如果进展顺利,Acting Set中的每个OSD的chunk都将被认可,PG log的last_complete从1, 1编程1, 2。
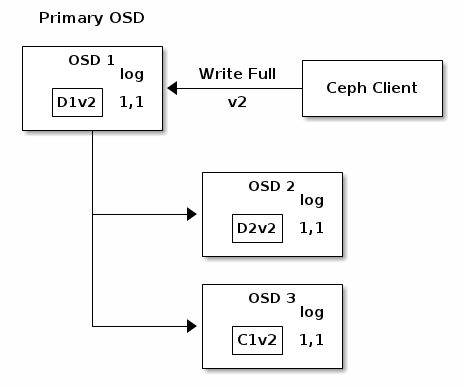
最终,存储之前chunk的文件可以被删除,如存在OSD 1中的D1v1,OSD 2中的D2v1, OSD 3中的C1v1。
但是事故发生,如果OSD 1在与OSD 2正在传输D2v2的过程中崩溃了,version 2的object只写了部分。OSD 3拥有一个chunk但是这并不足以使得object恢复。它失去了两个chunk:D1v2,D2v2,根据纠删码编解码参数K=2,M=1,需要至少两个可用的chunk,来重建第3个chunk。OSD 4成为了新的Primary OSD,它寻找last_complete日志记录(1,1),这条记录将成为权威的PG Log。
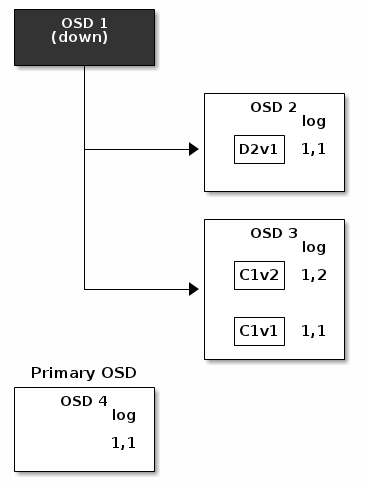
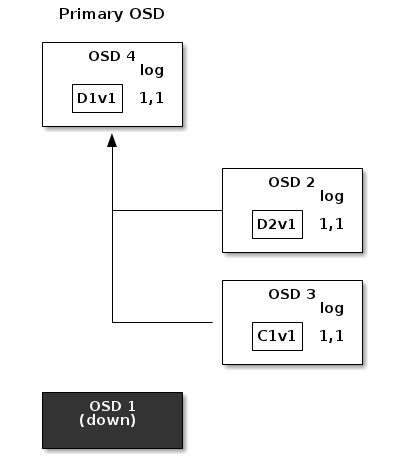
PG Log的日志记录1,2在OSD 3中被发现,这条日志记录与新的权威日志(有OSD 4提供)是不相同的:这条记录将会被丢弃,并且对应C1v2 chunk的文件也将被删除。D1v1chunk将在整理(scrub)期间由纠删码库的decode函数重建,并存储在新的Priamry OSD 4中。
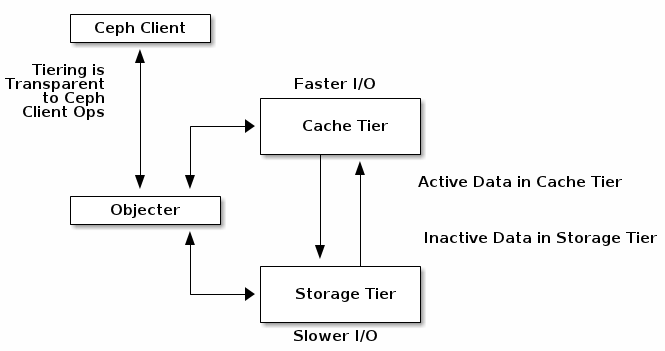
cache层
cache是后端存储的一个子集以提供ceph客户端更好的IO性能。cache层涉及创建pool时指定的相关的更快/更贵的存储设备(如SSD)将其配置成一个cache层,后端的pool使用的是纠删码或更慢/更便宜的存储设备,整体成为一个经济型的存储资源。ceph objecter处理object的存放位置,tiering agent决定将cache中数据flush到后端存储的时机和策略。所以cache层和后端存储对于ceph客户端来说是完全透明的。
扩展ceph
你可以扩展ceph通过创建动态共享库class,叫做’Ceph Classes’。ceph动态装载存储在osd class目录.so的类(i.e. 默认是 $libdir/rados-classes)。当你实现一个类,你可以创建一个新的对象方法以致于可以在ceph存储集群去调用本地方法,或者通过合并库或者自己创建的别的类方法。
对于写操作,ceph classes能够调用本地或者类方法,在写入的数据执行一连串的操作和产生一个ceph能够原子地执行的写事务。
对于读操作,ceph classed能够调用本地或者类方法,在读入的数据执行一连串的操作并将结果返回给客户端。
ceph class例子
一个内容管理系统的ceph class,需要显示特殊尺寸和长宽比的位图图片,此时需要修剪这张图片的长宽比,重新调整其大小,并嵌入版权和水印来保护知识产权。然后保存处理完的位图图片存储到系统中。
参照src/objclass/objclass.h, src/fooclass.cc and src/barclass
总结
ceph存储集群是动态的–就像一个生命体。然而,许多存储应用没有充分利用商用服务器的CPU和RAM,ceph却做到了。从心跳到peering,重平衡集群或者排除错误,ceph从客户端中和也从中央网关(这并不存在于ceph架构)卸载任务,和使用OSD上的计算资源去执行任务。当涉及到 Hardware Recommendations和Network Config Reference时,可以认识到前面所述的概念,以明白ceph是如何利用计算资源的。
Ceph协议
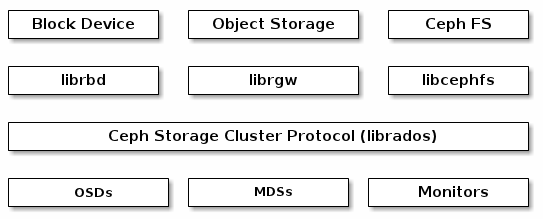
ceph客户端使用本地协议与ceph存储集群交互。ceph封装这些功能到librados库中,所以你可以创建自定义的ceph客户端。下图描绘了这个基本的架构。
本地协议和librados
现代的应用程序需要一个简单的,拥有异步通信能力的对象存储接口,而ceph存储集群就提供一个这样的接口,这组接口提供了直接,并行地访问集群的能力包括如下:
* pool操作
* 快照和写时复制
* 读写object– 创建和删除 – 完整object或字节范围的部分object – 追加或截断
* 创建/设置/获取/删除 XATTRs(属性)
* 创建/设置/获取/删除 键值对
* 合并操作和双重响应语义
* object classes – 对象类?
object watch/notify object 观察/通知
客户端可以注册一个持续关注一个object,和与Primary OSD保持一个session。客户端可以发送一个通知消息和有效负荷到所有观察者(watcher)和在观察者接收到通知的时候收到的通知。这使得客户端可以使用任意的一个object作为一个同步通信的通道。
数据条带化
存储设备有吞吐量的限制,这将影响性能和扩展性。所以存储系统通常支持条带化–在多个存储设备分片存储信息,以提高吞吐量和性能。最常用的数据条带化形式就是RAID。ceph条带化与RAID0最为相似。ceph条带化提供了RAID0的吞吐量,多路RAID镜像的可靠性和快速恢复的能力。
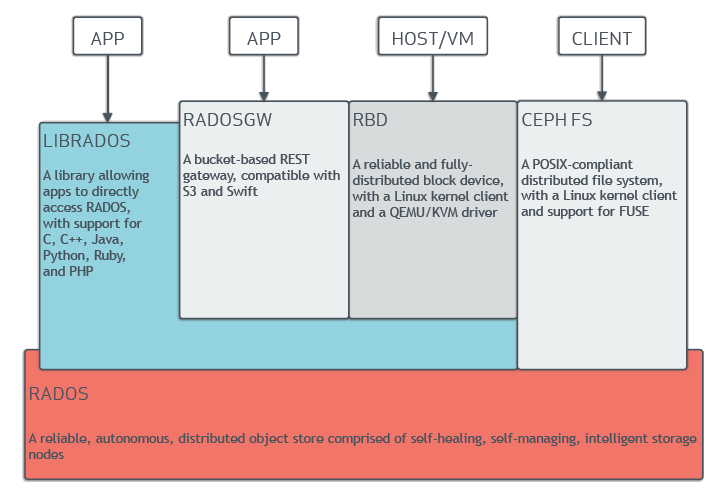
ceph提供3中类型的客户端:块设备、文件系统和对象存储。ceph客户端转换展现的格式,提供用户(块设备镜像、RESTful对象,文件系统目录)以object的方式存储到ceph集群中。
Tip:ceph存储的object不会以条带方式存储。ceph的对象存储、块设备和文件系统将对它们的数据进行切割分条,生成多个object。ceph客户端直接将分割好的object通过librados写入存储集群。所以librados库必须执行条带分割和并行IO,以获得这些优势。
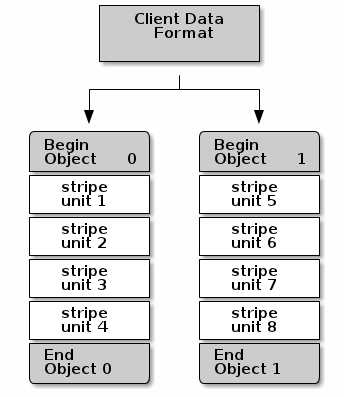
最简单的ceph条带化格式是1个object分成1个条带。ceph客户端写条带单元到ceph存储集群,直到该object达到它的最大存储容量,此时创建一个新的object用来存储剩余的条带单元。最简单的分割条带形式已经能够满足小的块设备镜像,S3或者Swift接口和CephFS文件。然而,这种简单形式不会最大化利用ceph分布数据到多个PG的能力,因此并不能大量提高性能。下图描述了最简单的分条形式:
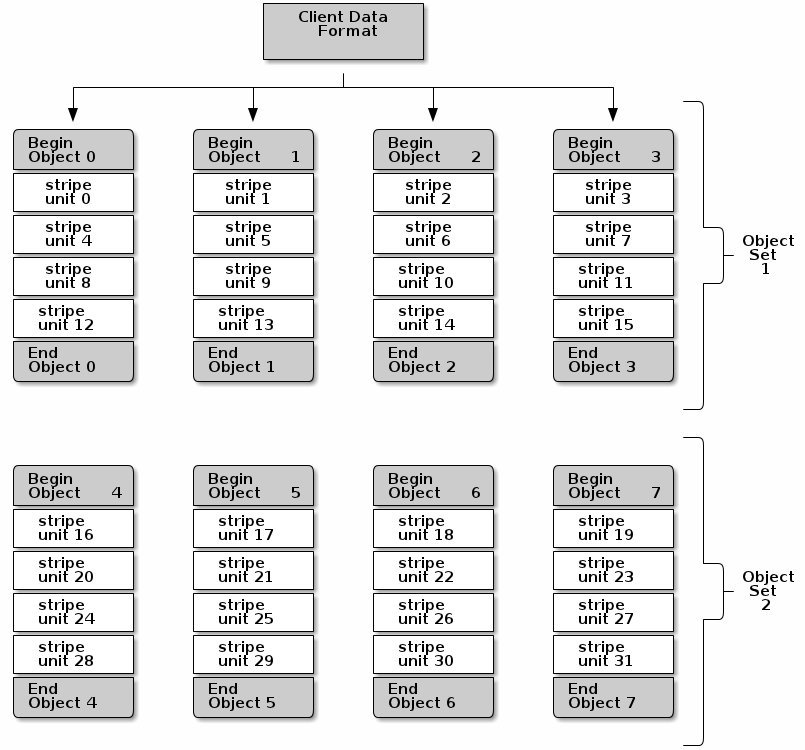
如果你期望一个大的镜像,大的S3或Swift的对象(eg. video), 或者大的CephFS目录结构,你可能会考虑通过将客户端数据分条成多个object以提高读写性能。当客户端通过将条带单元并行写入匹配的object时,写性能将得到显著地提升。由于object会映射到不同的PG,进一步映射到不同的OSD,每个并行写操作都将以最大的写速度进行。每个对单磁盘的写操作可能限制于磁头的移动(eg.每次寻找消耗6ms)和传输带宽。通过将写操作展开到多个object(映射到不同PG和不同OSD),ceph能够减少寻址每个磁盘的次数,和合并多个磁盘的吞吐量,以达到更快的读写速度。
Note:条带不同于备份,因为CRUSH通过OSD备份对象,条带自动获得备份。
下图中,客户端数据获取条带数据通过一个object set(下图中的object set 1),其中包含4个object,第一个条带单元是stripe unit 0存储在object 0中,第四个条带单元是stripe unit 3存储在object 3中。在写第四个条带单元后,客户端判断该object set是否已满。如果object set没满,客户端开始再次写条带到第一个object(下图中的object 0),如果object set已经满了,客户端创建一个新的object set(下图中的object set 2),并开始写一定条带(stripe unit 16)在新的object set中的第一个object(下图中的object 4)。
3个重要的变量决定ceph如何分条数据:
* Object Size:ceph存储集群的object的大小有1个可配置的最大值(eg. 2MB,4MB等)。object size应该足够大,以致于能够适应大多数的条带单元,和应该存储多个条带单元。
* Stripe Width:条带有一个可配置的单元大小(eg. 64KB)。ceph客户端将数据分割成大小相等的分片,它将写入与分条单元大小相同的object,除了最后一个分条单元。条带宽度,可能是object大小的一部分,所以一个object可能包含多个条带单元。
* Stripe Count:ceph客户端在一组object上写一系列的条带单元,该组object的数量由分条数量(stripe count)。这组object叫做object set。在ceph客户端写到object set中的最后一个object时,客户端将从该object set的第一个object覆盖写。
重要:在你投入产品使用之前,测试条带配置的性能。在分割数据并写入到object之后,你将无法改变这些分条带参数。
一旦ceph客户端将数据分割成条带单元并且将条带单元映射到object,ceph的CRUSH算法在object存储到磁盘文件之前,映射object到PG,PG映射到ceph OSD。
ceph客户端
ceph客户端包含了一组服务接口:
- 块设备:ceph块设备RBD服务提供了可变尺寸,自动精简配置,快照和克隆。ceph将一个块设备分割成条带进行存储已达到高性能的目的。ceph支持kernel对象,也支持QEMU虚拟机管理器使用librbd直接访问,以避免内核对象到虚拟系统之间的开销。
- 对象存储:ceph对象存储RGW服务提供RESTful API接口,这与Amazon S3和Openstack Swift保持兼容。
- 文件系统:ceph文件系统服务提供标准的POSIX兼容的文件系统,使用mount直接本地使用或者使用FUSE作为用户空间文件系统。
ceph也能运行额外的OSD,MDS和MON实例已达到扩展性和高可用性。下图描述了高层次的架构:
ceph对象存储
ceph对象存储守护进程radosgw,是一个FastCGI服务,提供了RESTful HTTP API存储对象和元数据。radosgw存在于ceph存储集群的顶层,拥有自己的数据格式,并维护它自己的用户数据库,验证机制和访问控制。radosgw使用一个统一的命名空间,这意味着你可以使用Swift或者S3兼容的API。举个例子,一个应用程序使用S3兼容API写入数据,然后另一个应用程序可以用Swift兼容的API将数据读出。
比较S3/Swift object 和ceph存储集群object
ceph的对象存储使用对象来描述数据的存储。S3和swift对象与ceph写入到ceph存储集群的对象不是同一个含义。ceph对象存储的对象是映射为ceph存储集群的对象。S3和swift对象不能按1:1对应到存储集群存储对象。有可能存储一个S3或Swift对象映射到多个ceph对象。
ceph块设备
一个ceph块设备分拆为一个块设备的镜像,通过多个存储在ceph存储集群中的对象。当每一个对象映射到PG并分布后,PG会使用集群,均匀分散的放置到独立的ceph-osd后台。
重要: 分段允许RBD块设备,与单个服务器相比,可以保持较好的性能。
自动缩容可快照的ceph块设备对虚拟化和云计算来说是有吸引力的选项。在虚拟机器的场景中,用户经常在Qemu/Kvm中,部署一个使用rbd的网络存储驱动ceph的块设备,这些主机可以使用librbd为客户提供块设备服务。多数的云计算栈使用libvirt与虚拟机管理器集成。你可以使用自动缩容的Qemu ceph块设备和libvirt与其他解决方案一起,来支持OpenStack和CloudStack。
当前我们不提供librbd支持其他虚拟机管理器,你可以使用ceph块设备内核对象,来向客户端提供块设备。其他的虚拟化技术像Xen也可以使用ceph块设备内核对象。这些可以使用命令行工具rbd来完成。
ceph文件系统
在基于对象的ceph存储集群的最上层,(CEPH FS)提供了一个兼容POSIX的文件系统服务。ceph文件系统文件映射到ceph存储在其存储集群上的对象。ceph客户端可以挂载ceph文件系统作为内核的对象或作为用户空间的文件系统。

ceph文件系统服务包含了与ceph存储集群一起部署的ceph元数据服务器。MDS用来存储所有的文件系统元数据(目录,文件拥有者,存取模式等)到ceph的元数据服务器的内存中。这是因为,MDS(被称为守护进程的ceph-mds)主要是简单的文件系统操作,比如列出目录,或更改目录(ls,cd)将花费不必要的ceph OSD后台进程。所以,独立的元数据意味着ceph文件系统可以在不消耗ceph存储集群也能提供高性能的服务。
ceph文件系统把元数据独立出来,存储在MDS,并将这些文件数据存储在ceph存储集群的一个或多个对象上。这样ceph文件系统可以达到与POSIX兼容的目标。ceph-mds可以在单进程上运行,也可以分布在多台物理机器上,来实现高性能和扩展性。
- 高可用性:可以有附加的ceph-mds实例作为备份机器,当出现故障时,随时准备接管。这样的实现比较简单,因为所有的数据,包括日志,保存在RADOS上。通过ceph-mon自动触发切换。
- 扩展性:多个ceph-mds实例都可以是活跃的。这些机器将多个目录树分割到子树(包括一个繁忙的目录碎片),有效的平衡所有活跃机器的负载。
将备份机器和活跃机器组合在一起也是可行的,比如,运行3个活跃的ceph-mds实例保证扩展性,和一个备机实例保证高可用性。















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









