






自己实现一个SQL解析引擎
功能:将用户输入的SQL语句序列转换为一个可执行的操作序列,并返回查询的结果集。
SQL的解析引擎包括查询编译与查询优化和查询的运行,主要包括3个步骤:
- 查询分析:
- 制定逻辑查询计划(优化相关)
- 制定物理查询计划(优化相关)
- 查询分析: 将SQL语句表示成某种有用的语法树.
- 制定逻辑查询计划: 把语法树转换成一个关系代数表达式或者类似的结构,这个结构通常称作逻辑计划。
- 制定物理查询计划:把逻辑计划转换成物理查询计划,要求指定操作执行的顺序,每一步使用的算法,操作之间的传递方式等。
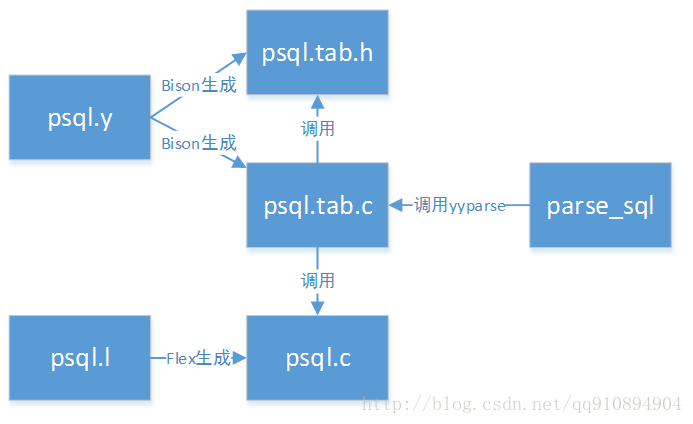
查询分析各模块主要函数间的调用关系:
图1.SQL引擎间模块的调用关系

FLEX简介
flex是一个词法分析工具,其输入为后缀为.l的文件,输出为.c的文件. 示例是一个类似Unix的单词统计程序wc。
.l文件通常分为3部分:
definition部分为定义部分,包括引入头文件,变量声明,函数声明,注释等,这部分会被原样拷贝到输出的.c文件中。
rules部分定义词法规则,使用正则表达式定义词法,后面大括号内则是扫描到对应词法时的动作代码。
code部分为C语言的代码。yylex为flex的函数,使用yylex开始扫描。
%option 指定flex扫描时的一些特性。yywrap通常在多文件扫描时定义使用。常用的一些选项有
noyywrap 不使用yywrap函数
yylineno 使用行号
case-insensitive 正则表达式规则大小写无关
flex文件的编译
Bison简介
Bison作为一个语法分析器,输入为一个.y的文件,输出为一个.h文件和一个.c文件。通常Bison需要使用Flex作为协同的词法分析器来获取记号流。Flex识别正则表达式来获取记号,Bison则分析这些记号基于逻辑规则进行组合。
计算器的示例:calc.y
Bision文件编译
通常,Bison默认是不可重入的,如果希望在yyparse结束后保留解析的语法树,可以采用两种方式,一种是增加一个全局变量,另一种则是设置一个额外参数,其中ParseResult可以是用户自己定义的结构体。
%parse-param {ParseResult *result}
在规则代码中可以引用该参数:
调用yyparse时则为:
ParseResult p;
yyparse(&p);
SQL解析引擎中的数据结构
语法树结构
在实现的时候可以把语法树和逻辑计划都看成是树结构和列表结构,而物理计划更像像是链式结构。树结构要注意区分叶子节点(也叫终止符节点)和非叶子节点(非终止符节点)。同时叶子节点和非叶子节点都可能有多种类型。
语法树的节点:包含两个部分,节点的类型的枚举值kind,表示节点值的联合体u,联合体中包含了各个节点所需的字段。
在语法树中,分析树的叶子节点为数字,字符串,属性等,其他为内部节点。因此有些数据库的实现中将语法树的节点定义为如下的ParseNode结构。
逻辑计划结构
逻辑计划的内部节点是算子,叶子节点是关系.
逻辑计划节点的类型PLANNODEKIND的枚举值如下:
物理计划结构
物理逻辑计划中关系扫描运算符为叶子节点,其他运算符为内部节点。拥有3个迭代器函数open,close,get_next_row。其定义如下:
物理查询计划的节点类型PHYOPNODEKIND枚举如下:
节点内存池
可以看到分析树,逻辑计划树和物理查询树都是以指针为主的结构体,如果每次都动态从申请的话,会比较耗时。需要使用内存池的方式,一次性申请多个节点内存,供以后调用。下面是一种简单的方式,每次创建节点时都使用newnode函数即可。程序结束时再释放内存池即可。
查询分析
查询分析需要对查询语句进行词法分析和语法分析,构建语法树。词法分析是指识别SQL语句中的有意义的逻辑单元,如关键字(SELECT,INSERT等),数字,函数名等。语法分析则是根据语法规则将识别出来的词组合成有意义的语句。 词法分析工具LEX,语法分析工具为Yacc,在GNU的开源软件中对应的是Flex和Bison,通常都是搭配使用。
词法和语法分析
SQL引擎的词法分析和语法分析采用Flex和Bison生成,parse_sql为生成语法树的入口,调用bison的yyparse完成。源文件可以这样表示
| 文件 | 意义 |
|---|---|
| parse_node.h parse_node.cpp | 定义语法树节点结构和方法,入口函数为parse_sql |
| print_node.cpp | 打印节点信息 |
| psql.y | 定义语法结构,由Bison语法书写 |
| psql.l | 定义词法结构,由Flex语法书写 |
SQL查询语句语法规则
熟悉Bison和Flex的用法之后,我们就可以利用Flex获取记号,Bison设计SQL查询语法规则。一个SQL查询的语句序列由多个语句组成,以分号隔开,单条的语句又有DML,DDL,功能语句之分。
stmt_list : stmt ‘;’
| stmt_list stmt ‘;’
;
stmt: ddl
| dml
| unility
| nothing
;
dml: select_stmt
| insert_stmt
| delete_stmt
| update_stmt
| replace_stmt
;
以DELETE 单表语法为例
用Bison可以表示为:
然后在把opt_where,opt_groupby,table_ident等一直递归下去,直到不能在细分为止。
SQL语句分为DDL语句和DML语句和utility语句,其中只有DML语句需要制定执行计划,其他的语句转入功能模块执行。
制定逻辑计划
执行顺序
语法树转为逻辑计划时各算子存在先后顺序。以select语句为例,执行的顺序为:
FROM > WHERE > GROUP BY> HAVING > SELECT > DISTINCT > UNION > ORDER BY > LIMIT。
没有优化的逻辑计划应按照上述顺序逐步生成或者逆向生成。转为逻辑计划算子则对应为:
JOIN –> FILTER -> GROUP -> FILTER(HAVING) -> PROJECTION -> DIST -> UNION -> SORT -> LIMIT。
逻辑计划的优化
逻辑计划的优化需要更细一步的粒度,将FILTER对应的表达式拆分成多个原子表达式。如WHERE t1.a = t2.a AND t2.b = '1990'可以拆分成两个表达式:
1)t1.a = t2.a
2)t2.b = '1990'
不考虑谓词LIKE,IN的情况下,原子表达式实际上就是一个比较关系表达式,其节点为列名,数字,字符串,可以将原子表达式定义为
CompOpType为“>”, ”<” ,”=”等各种比较操作符的枚举值。
如果表达式符合 attr comp value 或者 value comp attr,则可以将该原子表达式下推到对应的叶子节点之上,增加一个Filter。
如果是attr = value类型,且attr是关系的索引的话,则可以采用索引扫描IndexScan。
当计算三个或多个关系的并交时,先对最小的关系进行组合。
还有其他的优化方法可以进一步发掘。内存数据库与存储在磁盘上的数据库的代价估计不一样。根据处理查询时CPU和内存占用的代价,主要考虑以下一些因素:
- 查询读取的记录数;
- 结果是否排序(这可能会导致使用临时表);
- 是否需要访问索引和原表。
制定物理计划
物理查询计划主要是完成一些算法选择的工作。如关系扫描运算符包括:
TableScan(R):按任意顺序读入所以存放在R中的元组。
SortScan(R,L):按顺序读入R的元组,并以列L的属性进行排列
IndexScan(R,C): 按照索引C读入R的元组。
根据不同的情况会选择不同的扫描方式。其他运算符包括投影运算Projection,选择运算Filter,连接运算包括嵌套连接运算NestLoopJoin,散列连接HashJoin,排序运算Sort等。
算法的一般策略包括基于排序的,基于散列的,或者基于索引的。
流水化操作与物化
由于查询的结果集可能会很大,超出缓冲区,同时为了能够提高查询的速度,各运算符都会支持流水化操作。流水化操作要求各运算符都有支持迭代操作,它们之间通过GetNext调用来节点执行的实际顺序。迭代器函数包括open,getnext,close3个函数。
设NestLoopJoin的两个运算符参数为R,S,NestLoopJoin的迭代器函数如下:
如果TableScan,IndexScan,NestLoopJoin 3个运算符都支持迭代器函数。则图5中的连接NestLoopJoin(t1,t2’)可表示为:
phy = Projection(Filter(NestLoopJoin(TableScan(t1),IndexScan(t2’))));
执行物理计划时:
这种方式下,物理计划一次返回一行,执行的顺序由运算符的函数调用序列来确定。程序只需要1个缓冲区就可以向用户返回结果集。
也有些情况需要等待所有结果返回才进行下一步运算的,比如Sort , Dist运算,需要将整个结果集排好序后才能返回,这种情况称作物化,物化操作通常是在open函数中完成的。
一个完整的例子
接下来以一个例子为例表示各部分的结构,SQL命令:
SELECT t1.a,t2.b FROM t1,t2 WHERE t1.a = t2.a AND t2.b = '1990';
其对应的分析树为:
图2. SQL例句对应的分析树
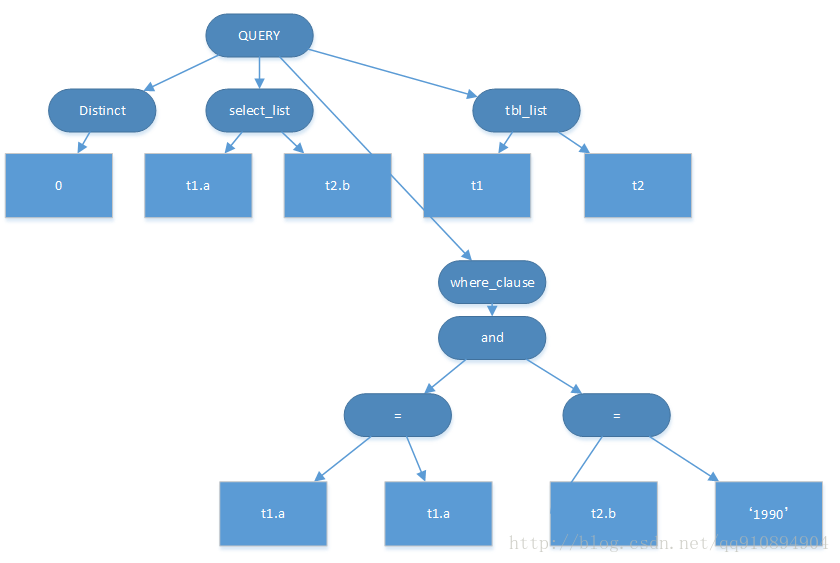
分析树的叶子节点为数字,字符串,属性等,其他为内部节点。
将图2的分析树转化为逻辑计划树,如图3所示。
图3. 图2分析树对应的逻辑计划
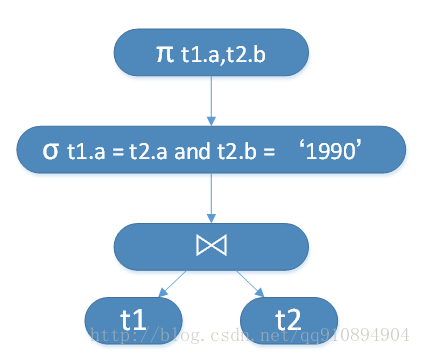
逻辑计划是关系代数的一种体现,关系代数拥有种基本运算符:投影 (π),选择 (σ),自然连接 (⋈),聚集运算(G)等算子。因此逻辑计划也拥有这些类型的节点。
逻辑计划的内部节点是算子,叶子节点是关系,子树是子表达式。各算子中最耗时的为连接运算,因此SQL查询优化的很大一部分工作是减小连接的大小。如图3对应的逻辑计划可优化为图4所示的逻辑计划。
图4. 图3优化后的逻辑计划
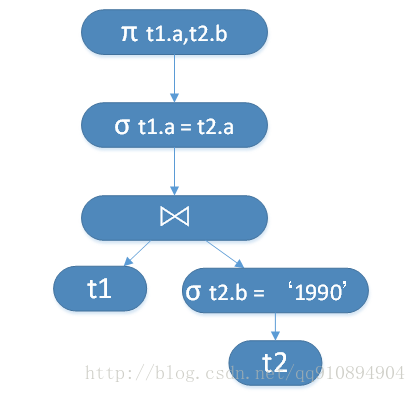
完成逻辑计划的优化后,在将逻辑计划转化为物理查询计划。图4的逻辑计划对应的物理查询计划如下:
图5. 图4对应的物理查询计划
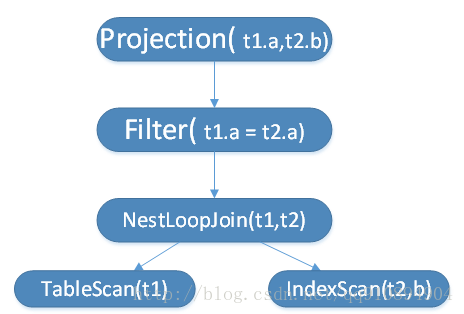
物理查询计划针对逻辑计划中的每一个算子拥有对应的1个或多个运算符,生成物理查询计划是基于不同的策略选择合适的运算符进行运算。其中,关系扫描运算符为叶子节点,其他运算符为内部节点。
后记
开源的数据库代码中可以下载OceanBase或者RedBase。OceanBase 是淘宝的开源数据库,RedBase是斯坦福大学数据库系统实现课程的一个开源项目。后面这两个项目都是较近开始的项目,代码量较少,结构较清晰,相对简单易读,在github上都能找到。但是OceanBase目前SQL解析部分也没有全部完成,只有DML部分完成;RedBase设计更简单,不过没有设计逻辑计划。
本文中就是参考了RedBase的方式进行解析。
参考文献:
《数据库系统实现》
《flex与bison》
欢迎光临我的网站----蝴蝶忽然的博客园----人既无名的专栏。
如果阅读本文过程中有任何问题,请联系作者,转载请注明出处!















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









