







第七章SQL
这一章提供了 Structured Query Language(SQL)的概述,以及Oracle数据库怎样处理SQL语句。
这一章包括如下专题:
·Introduction to SQL
·Overview of SQL Statements
·Overview of the Optimizer
·Overview of SQL Processing
Introduction to SQL(SQL的介绍)
SQL(发音为 sequel) 是基于集合,高级声明计算机,所有的程序和用户通过使用它可以访问Oracle数据库中的数据。虽然一些Oracle工具以及应用掩盖了SQL的使用,但是所有的数据库操作都是通过SQL执行的。任何其他数据访问方法,必须要绕过内置的Oacle数据库安全机制,以及会潜在的损害数据库的安全和完整性。
SQL提供了一个对关系数据库(如Oracle)的接口。SQL以一种一致性的语句统一了如下任务:
·创建,替换,变更以及丢弃 对象。
·插入,更新,删除表中的行
·查询数据
·控制对数据库和它里面对象的访问。
·保证数据库的一致性和完整性
SQL 可以交互地使用,交互指的是 在程序运行时,根据需要手工输入。SQL语句同样可以 嵌入不同语言写成程序(如C 或 Java)
SQL Data Access(SQL数据访问)
有两种大类的计算机语言:declarative languages(声明语言),它是非过程化的,描述什么东西需要完成。Procedural language(过程语言),比如C++ 以及Java,它需要描述 怎样 完成。SQL就是某种意义上的声明,用户指定他们想要的结果,而不必说明怎样去得到它
SQL语言编译器 执行 产生一个过程 以操作数据库,并执行所需的任务。
SQL使你在逻辑级别使用数据。你只有在操作数据的时候才需要关注其实现细节。举个例子,下面的语句查询employees表中谁last name开始字母是K:
SELECT last_name, first_name
FROM hr.employees
WHERE last_name LIKE 'K%'
ORDER BY last_name, first_name;
数据库可以在一个步骤中,将所有符合WHERE条件(同样也称之为predicate 谓词)的行都检索回来。这些行可以作为一个单元传递给用户,传递给其他SQL语句,或传递给一个应用程序。你不需要一行一行的处理,也不需要知道行是怎样物理存储的,或检索回来的。
所有的SQL语句都使用 optimizer(优化器),它是Oracle数据库的一部分,它来确定访问指定数据最有效的方法。Oracle数据库同样只一些技术,你可以使用它来使得optimizer执行它自己的工作时 更加好。
SQL Standards(SQL标准)
Oracle努力紧跟行业普遍接受的标准,以及积极参加SQL标准委员会。Industry-accepted 委员会是 American National StandardsInstitute(ANSI)和International Organization for Standardization(ISO)。ANSI和ISO/IEC都接受SQL作为关系型数据库的标准语言。
最后的SQL标准是2003年7月通过的,经常叫它SQL:2003。SQL标准的第14部分(ISO/IEC 9075-14),在2006年被修订,经常称它为 SQL/XML:2006。
ORACLE SQL包括了很多针对ANSI/ISO标准SQL语句的扩展,而且Oracle数据库工具和应用程序提供了一些额外的语句。SQL*PLUS,SQL Developer,以及OEM都可以对Oracle数据库运行标准SQL中的任何语句,以及这些工具额外的语句或功能。
Overview of SQL Statements
在Oracle数据库中,对信息的任何操作,都是通过使用SQL语句。一个SQL语句是一个计算机程序,或 是包括了标识符,参数,变量,名字,数据类型以及SQL保留字的 一个命令。
注意:SQL保留字在SQL中有特别的含义,它应该用在其他目的。举个例子,SELECT和UPDATE就是保留字,它们不应该用来作为表名。
一个SQL语句必须是一个完整的SQL句子,比如:
SELECT last_name,department_id FROM employees
Oracle数据库只运行完整的SQL语句,像下面这样的片段,会生成一个报错,表明需要更多的内容:
SELECT last_name;
Oracle SQL语句分为下面类型:
·Data Definition Language (DDL) Statements
·Data Manipulation Language (DML) Statements
·Transaction Control Statements
·Session Control Statements
·System Control Statement
·Embedded SQL Statements
Data Definition Language(DDL)statements(数据定义语句)
DDL语句用来定义,结构化改变,以及丢弃 schema objects。举个例子,DDL语句使你可以:
·create ,alert,drop 掉 schema objects以及其他数据库结构,包括数据库自己,以及数据库用户。绝大多数DDL语句开始关键字为 CREATE,ALERT或DROP
·可以不移除表结构,但是将表中的所有数据删除。(TRUNCATE)。
注意:和DELETE不一样,TRUNCATE是不产生undo 数据的,这样导致它比DELETE 要快多了。同样的,TRUNCATE不会触发 delete 触发器。
·授予和收回权限或角色(GRANT,REVOKE)
·开启审核选项或关闭(AUDIT,NOAUDIT)
·添加解释到data dictionary(COMMENT)
DDL使你可以更改一个对象的属性,而不用更改访问这个对象的应用。举个例子,你可以添加一列到一个表,访问这个表的人力资源应用不用重写
你同样可以 有用户在数据库中执行工作时,通过DDL来更改一个对象的结构。
下面例子使用DDL语句创建了一个名为plants的表,以及使用DML插入了两行到表。然后使用DDL去更改这个表的结构,授予和回收 这个表上面的权限 给用户,然后移除了这张表。
CREATE TABLE plants
(plant_id NUMBER PRIMARY KEY,
common_name VARCHAR2(15) );
INSERT INTO plants VALUES (1, 'AfricanViolet'); # DML statement
INSERT INTO plants VALUES (2, 'Amaryllis'); #DML statement
ALTER TABLE plants ADD
(latin_name VARCHAR2(40) );
GRANT SELECT ON plants TO scott;
REVOKE SELECT ON plants FROM scott;
DROP TABLE plants;
当数据库执行DDL语句之前,会隐式发布一个COMMIT。然后在执行完成以后会立即发生一个COMMIT或ROLLBACK。上面例子中,INSERT语句后面跟着ALTER TABLE语句,那么数据库把两条INSERT语句就提交了。如果ALTER TABLE语句成功,那么数据库提交这个语句,否则,数据库rollback这个语句。两种情况 无论哪种情况,前面两个INSERT语句也早已经提交了。
Data ManipulationLanguage(DML) statements(数据库操作语言 语句)
Data manipulationlanguage(DML)语句查询或操作schema objects中的数据库。DDL语句则是使你可以改变数据库的结构,DML语句使你能查询或修改内容。举个例子,ALTER TABLE改变表的结构,而INSERT 添加一行或多行到表中。
DML语句是最频繁使用的SQL语句,它使你可以:
·从一个或多个表(或视图)中检索或取回数据(SELECT)
·添加新的数据行到表或视图中(INSERT),可以指定特定的列,或使用使用子查询来获取以及操作已经存在的数据。
·改变表中已存行上的列值(UPDATE)
·通过条件来更新或插入行到一个表或视图中(MERGE).
·删除表(或视图)中的行(DELETE)
·查看SQL语句的执行计划(EXPLAIN PLAN)。
·将表或视图锁住,临时限制其他用户的访问(LOCK TABLE)。
下面例子使用DML来查询employees表。这个例子还使用DML在employees表中插入一个行,更新这行,然后删除了它:
SELECT * FROM employees;
INSERT INTO employees (employee_id,last_name, email, job_id, hire_date, salary)
VALUES (1234, 'Mascis', 'JMASCIS', 'IT_PROG', '14-FEB-2008', 9000);
UPDATE employees SET salary=9100 WHEREemployee_id=1234;
DELETE FROM employees WHERE employee_id=1234;
一些DML语句组成的一个逻辑工作单元,叫做transaction(事务)。举个例子,一个事务用来将转移一笔钱需要包含三个单独的操作:从存储账户中减少,在支付账户上增加,记录这个转移到账户历史表。和DDL不同,DML语句不会隐式提交当前的事务。
SELECT statements(SELECT 语句)
一个查询(query) 就是一个从表或事务中检索数据的操作。SELECT你唯一可以用来查询数据的语句。通过SELECT 语句检索回来的数据集合 称之为result set(结果集)。
下表显示了SELECT语句中必须的关键字,以及两个最常用的关键字。这个表同样关联了SELECT语句和这些关键字组合在一起时的功能。
Joins(联合)
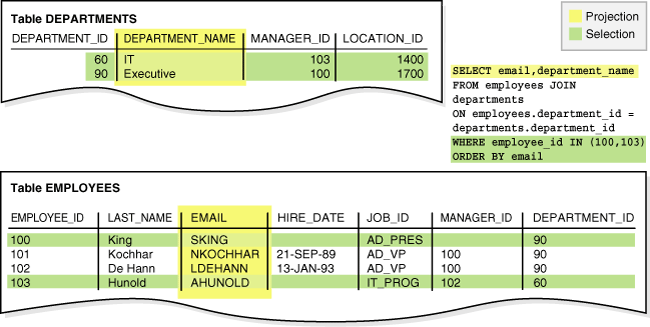
一个join是一个查询 组合 两个或多个表,视图或物化视图 中的行。下面例子就是join了employees和departments表(FROM子句),只选择符合标准的行(WHERE子句),以及使用投影来返回两列的数据(SELECT)。语句后面跟着这个案例的返回数据:
SELECT email, department_name
FROM employees JOIN departments
ON employees.department_id = departments.department_id
WHERE employee_id IN (100,103)
ORDER BY email;
EMAIL DEPARTMENT_NAME
-------------------------------------------------------
AHUNOLD IT
SKING Executive
下图显示了projection以及join的选择 的操作(上面例子)。
绝大部分 join 都有最少一个 join condition(join 条件),要么在FROM 自己,要么在WHERE子句。它比较两个表中的两列。数据库如果join condition求的值等于TRUE,将把两个表中的两行,组合成一行。基于join conditons,索引,以及可用的统计信息,优化器来决定表join时的顺序
Join有以下几种类型:
·Inner joins
一个inner join指两个或多个表join 只返回满足join条件的行。举个例子,如果join条件是employees.department_id=departments.department_id,那么不满足这个条件的行,将不返回。
·Outer joins
一个outer join 返回所有满足join条件的行,以及同样返回 某个表的行,(没有满足条件)。举个例子,employees和departments表的left outer join 将把employees表的行都返回,即使有些行在departments表中没有匹配的。一个right outer join 则会把departments的所有行都返回,即便这些行没有与employees中的匹配。
·Cartesian products(笛卡尔乘积)
如果一个join查询中的两个表,没有join条件,那么数据库将返回它们的笛卡尔乘积。一个表中的每一行都会于另外一表的每行进行组合。举个例子,如果employees表有107行,而departments表有27行,那么笛卡尔乘积将包括107*27行。笛卡尔乘积用处不大
Subqueries and ImplicitQueries(子查询,以及隐式查询)
一个子查询,就是一个嵌套在其他语句当中的SELECT语句。当你需要执行多个查询来解决一个问题时,子查询非常有用。
一个语句中,每个查询部分叫做一个query block。下面例子,括号里的子查询叫inner query block。这个inner SELECT语句会把location id等于1800的所有的部门的ID检索回来。这些ID被 outer query block需要,outer query block 把部门id符合 子查询的 雇员姓名返回。
SELECT first_name, last_name
FROM employees
WHERE department_id
IN (SELECT department_id FROM departments WHERE location_id = 1800);
SQL语句的结构不会强制数据库先执行innert query。举个栗子,数据库可能会将整个语句重写为 employees和departments的join,那么这样的话 这个子查询将永远不会单独执行。另外一个例子,Virtual Private Database(VPD)特性可能会使用一个WHERE来对员工表的访问进行限制,这样,数据库可能决定首先查询employees,然后获取departments ID。优化器来决定获取需要行的最佳步骤
隐式查询(implicit qery)是DML语句的一个组件,帮助DML语句不使用子查询也能检索数据。一个UPDATE,DELETE,或MERGE语句,它们都不会显示包含SELECT语句,它们用隐式查询来检索要修改的行。举个例子,下面语句包含了一个找Baer记录的隐式查询:
UPDATE employees
SETsalary = salary*1.1
WHERElast_name = 'Baer';
唯一一个DML语句 查询组件不是必须的,那就是INSERT语句。举个例子,一个INSERT INTO TABLE mytable VALUES(1) 语句 不需要在插入行之前先检索行
Transaction ControlStatements(事务控制语句)
事务控制语句管理着 事务中DML语句及一组DML语句 造成的修改。这些语句使你可以:
·使事务中做的修改永久成效(COMMIT)
·将一个事务所做的修改回滚,回滚到事务开始之前(ROLLBACK),或回滚到savepoint(ROLLBACK TO SAVEPOINT)。一个savepoint是一个事务内容中用户申明的中间标记
注意:ROLLBACK语句会结束一个事务。但是ROLLBACK TO SAVEPOINT不会。
·设置一个你可以回滚的点(SAVEPOINT)
·设定一个事务的属性(SET TRANSACTION)
·指定一个可延迟的完整性约束,是在每个DML语句后检查,还是当事务提交时再检查(SET CONSTRAINT)。
下面例子开启了一个叫Update salaries的事务,这个例子创建了一个savepoint,更行了一个雇员的工资,然后回滚这个事务到savepoint。这个例子更新工资为一个其他值,然后提交。
SET TRANSACTION NAME 'Update salaries';
SAVEPOINT before_salary_update;
UPDATE employees SET salary=9100 WHEREemployee_id=1234 # DML
ROLLBACK TO SAVEPOINT before_salary_update;
UPDATE employees SET salary=9200 WHEREemployee_id=1234 # DML
COMMIT COMMENT 'Updated salaries';
Session Control Statements(Session控制语句)
Session控制语句动态管理 用户session的属性。像“Connections and Sessions”里解释的一样,一个session是数据库instance中的一个逻辑实体,它表示当前用户登录连接到一个数据库的状态。一个session从一个用户通过数据库的验证,一直持续到用户disconnect或exit。
Session控制语句可以让你:
·通过执行一个特殊的功能,来修改当前会话,比如开启和关闭SQL跟踪(ALTER SESSION)
·开启或关闭属于本用户的roles(角色),角色是一组权限(SET ROLE)
下面的例子,就是开启SQL跟踪,然后开启除了dw_mnager以外,授予当前session的所有角色:
ALTER SESSION SET SQL_TRACE = TRUE;
SET ROLE ALL EXCEPT dw_manager;
会话控制语句不会隐式提交当前会话
System Control Statements(系统控制语句)
系统控制语句更改数据库实例的特性。只有系统控制语句是ALTER SYSEM。它使你可以改变设置,如shared server的最小数量,停止一个session,以及其他系统级别的任务。
下面是系统控制语句的例子:
ALTER SYSTEM SWITCH LOGFILE;
ALTER SYSTEM KILL SESSION '39, 23';
ALTER SYSTEM语句不会隐式提交当前事务。
Embedded SQL Statements(嵌入式SQL语句)
嵌入式SQL语句,将DDL,DML,以及事务控制语句混入过程化语言程序。它们和Oracle预编译器 一起使用。嵌入式SQL是一种在过程化语句中包含SQL的一种方法。其他方法就是用程序化API(应用接口)比如 Open Database Connectivity(ODBC)或 Java Database Connectivity(JDBC)
嵌入式SQL语句可以使你:
·定义,分配,释放cursors(DECLARE CURSOR,OPEN,CLOSE)
·指定一个数据库,然后连接它(DECLARE DATABASE,CONNECT)
·分配变量名称(DECLARE STATEMENT).
·初始化描述符(DESCRIBE)
·指定错误和警告要怎样处理(WHENEVER)
·解析和运行SQL语句(PREPARE,EXECUTE,EXECUTE IMMEDIATE)
·从数据库获取数据(FETCH)
Overview of the Optimizer(优化器概述)
为了理解Oracle数据库是如何处理SQL语句的,那么必须要先理解什么是优化器(同样称之为query optimizer[查询优化器]或cost-based optimizer[基于成本的优化器]).所有的SQL语句都使用优化器来决定访问指定数据时最效率的方法。
Use of the Optimizer(优化器的使用)
为了执行一个DML语句,Oracle数据库可能要执行很多步骤。这些步骤,要么是从database中把物理数据检索出来,要么就是准备好数据为用户执行的语句。
经常会有还能多不同的路线来处理一个DML语句。举个例子,访问这些表,或索引的顺序可以变化。数据库用来执行一个语句的步骤很大程度上影响了这个语句运行有多快。优化器产生一堆执行计划,描述有多少种可能的执行方法。
优化器根据考虑多种信息资源,包括查询条件,可用执行路径,系统状态收集,以及Hints来决定采用哪个最优效率的执行计划。
Oracle处理任何SQL语句,优化器都会执行下面操作:
·表达式和条件的评估
·检查完整性约束来了解数据,以及基于这些元数据的优化
·语句转换
·优化器目标的选择
·访问路径的选择
·join顺序的选择。
优化器处理一个查询会产生非常多的路线,对于产生的每个执行计划中的每一步骤,都会分配一个cost(代价)。 最低成本的执行计划将被选择作为 查询计划,然后执行它。
注意:你可以获取一个执行计划,但不一定需要执行它。只有数据库实际用来执行一个查询的执行计划,才称之为 查询计划(query plan).
你可以通过设置优化器目标和收集统计信息来影响优化器的选择。举个例子,你可能会在下面情况设置优化器目标:
·总的吞吐效率
ALL_ROWS hint 指示优化器获取 返回结果集中的最后一行,越快越好。
·初始响应时间
FIRST_ROWS hint 指示优化器获取 返回结果集中的第一行,越快越好。
一个标准的终端用户,交互应用 将在初始响应时间优化中获益。而 批处理模式,非交互式应用将在 总吞吐效率优化中收益。
Optimizer Components(优化器组件)
优化器包含三个主要组件,如下图显示

输入到优化器的已经是解析之后的查询了,优化器执行下列操作:
1、 优化器接受 解析后的查询,以及基于可用的访问路径和hints 为SQL语句产生一组可能的计划。
2、 优化器基于数据字典中的统计信息,为每个计划评估一个cost(成本)。成本是一个计划预期使用资源的 一个评估值
3、 优化器比较计划的成本,然后选择成本最低的那个,称之为query plan(查询计划),然后传递给 row source generator(行源生成器)
QueryTransformer(查询转换器)
查询转换器来决定改变查询的形状是否对查询有帮助(优化器是否能产生更好的执行计划)。传递到查询转换器的是解析之后的查询,解析后的查询表现为一堆query blocks。
Estimator(估算器)
估算器 来确定每个产生的执行计划的总计cost。估算器为了完成这个目标,生成了三个不同类型的测量值:
·Selectivity(选择性)
这个度量值表现为 一个行集中的一部分行。Selectivity(选择性)和查询谓词是紧密相连的。比如last_name=’Smith’, 或 一堆谓词的组合。
·Cardinality(基数)
这个度量值表现为 一个行集中的行数
·Cost(代价)
这个度量值表现为 工作量或者资源的使用 。查询优化器使用磁盘I/O,CPU使用率,内存使用率 作为 工作量
PlanGenerator(计划生成器)
计划生成器会为提交的查询,产生出一堆不同的计划,然后挑出其中成本最低的。优化器会为嵌套的子查询和 unmerged视图 产生子计划,它表现为不同的query block。计划生成器通过尝试不同的访问路径,join方法,join顺序。而探索出不同的执行计划。
优化器自动管理这些计划 并保证只使用经过验证的计划。SQL Plan Management(SPM)一个新计划,只有它被验证比当前计划更好时,才使用它。通过这样来控制计划的进化。
如EXPLAIN PLAN语句等诊断工具使你可以看到优化器选择的执行计划。EXPLAIN PLAN会显示指定的SQL查询,就好像它已经在当前会话中执行过一样。其他诊断工具还有OEM,以及SQLPLUS的AUTOTRACE命令,当AUTOTRACE 为ON时,执行语句 会在后面跟着显示它的执行计划
AccessPaths(访问路径)
访问路径是数据 从数据库中检索回来的路径。举个例子,一个查询使用索引和不使用索引就是两个不同的访问路径。普遍来说,索引访问路径在检索 表的行中 小的部分是,很快。全表扫描则在访问表中的很大一部分时,要快。
数据库可以使用不同的访问路径从一个表中检索数据。代表名单如下:
·Full table scans(全表扫描)
这种类型的扫描,将把一个表中的所有行都读出来,然后将不符合选择标准的过滤掉。数据库将顺序扫描segment中的高水位下所有数据块
·Rowid scans(rowid 扫描)
Rowed指定了每一行所在的数据文件,块,以及在块中的位置。数据库首先WHERE子句或者通过索引扫描,先获得行的rowid,然后再基于每个rowid找到每个被选择的行。
·Index scans(索引扫描)
这种扫描,在索引中扫描被索引列的值。如果这条语句只访问 索引中的列,那么Oracle数据库会在索引中直接读取 列值。
·Cluster scans
一个cluster scan是在检索 一个存储在 indexed table cluster上的表时使用的,相同cluster key只的所有行,都存在相同的数据块。数据库首先通过扫描 cluster 索引获取被选择行的rowid。Oracle数据库基于这些Rowid找到对应的行。
·hash scans
当扫描的行在 hash cluster中时,则会使用hash scan,这里所有hash后的值相同的行都存在相同的数据块中。数据库对cluster key 值应用hash 函数,获得hash值,然后扫描包含这个hash value的数据块获取相应的行
优化器选择访问路径 是基于对这个语句可用的访问路径,以及根据每个路径(或组合路径)估算的成本。
OptimizerStatistics(优化器统计信息)
优化器的statistics(统计信息)是一些收集好的数据,这些数据描述了数据库和数据库中对象的细节。统计信息提供了数据存储和分布。在优化器估算访问路径的时候会使用。
优化器统计信息包括如下:
·表统计信息
它们包括 行的数量,块的数量,平均行长度
·列统计信息
它们包括distinct 值(唯一值)的数量以及列中有多少null,以及数据的分布情况
·索引统计信息
它们包括叶块的数量,以及索引的高度
·系统统计信息
它们包括CPU和I/O的性能和利用率。
Oracle数据库会通过一个自动维护任务去 自动收集所有数据库对象上的统计信息以及维护它们。你可以通过DBMS_STATS包手动收集统计信息,这个PL/SQL包可以修改,查看,导出,导入以及删除统计信息。
优化器统计信息是为 优化查询而创建的,存在数据字典中。这些统计信息不要和通过动态性能试图看到的performance statistics(优化统计信息)搞混。
OptimizerHints(优化器hints)
Hint是一个SQL语句中的注释(comment),它的作用,类似对于优化器的指令。一些情况下,应用设计人员 ,他比起优化器来说,对应用数据更加清楚,他能选择选择一个更高效的路线来运行一个SQL语句。应用设计人员可以使用在SQL语句中使用hints来指定语句应该怎样运行。
举个例子,假设你的交互式应用 运行一个查询,返回了50行,这个应用程序初始仅仅获取查询的前25行,然后显示给终端用户,你希望优化器产生一个执行计划,这执行计划尽可能快的获取前25行,这样用户就不需要被迫等待了。你可以使用一个hint来发送这个指令给优化器,想下面语句显示的(这里之前使用了AUTOTRACE ON)
SELECT /*+ FIRST_ROWS(25) */ employee_id,department_id
FROM hr.employees
WHERE department_id > 50;
------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes
------------------------------------------------------------------------
| 0 |SELECT STATEMENT | | 26 | 182
| 1| TABLE ACCESS BY INDEX ROWID |EMPLOYEES | 26 | 182
|* 2 | INDEX RANGE SCAN |EMP_DEPARTMENT_IX | |
------------------------------------------------------------------------
上面例子中的执行计划显示了优化器选择了employees.department_id列上面的索引 来寻找employees表中department_id大于50的 的前25行。优化器使用从索引中检索到的rowid,用来到employees表中检索对应的记录,然后返回它们到客户端。第一条记录的几乎瞬间就取回了
下面例子显示了相同的语句,但是没有使用 优化器 hint
SELECT employee_id, department_id
FROM hr.employees
WHERE department_id > 50;
------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cos
------------------------------------------------------------------------
| 0 |SELECT STATEMENT | | 50 | 350 |
|* 1 | VIEW |index$_join$_001 | 50 | 350 |
|* 2 | HASH JOIN | | | |
|* 3 | INDEX RANGE SCAN |EMP_DEPARTMENT_IX | 50 | 350 |
| 4| INDEX FAST FULL SCAN|EMP_EMP_ID_PK | 50 | 350 |
上面例子的执行计划,通过join两个索引,然后尽可能快的返回所请求的记录。而不是重复的从索引到表像上上一个例子所示。优化器选择对EMP_DEPARTMENT_IX进行range scan 找出所有department_id大于50的行,然后把这些行放到 一个hash table。优化器然后选择读EMP_EMP_ID_PX索引,循环这一索引中的每个行,去探测hash table,去找department id
在这个情况下,数据库在索引EMP_DEPATMENT_IX 的range scan完成以前,是没办法将第一行返回给客户端的.因此,这个执行计划获取第一条记录的时间会长于前面的执行计划。前面的执行计划通过索引上的rowid来访问表,而本执行计划则是使用多块I/O,在大量读取中使用,这种读取使的整个结果集的最后一行返回的时间最快。
Overview of SQL processing
这个小节解释了Oracle数据库是如何处理SQL语句的。具体来说,解释了DDL语句创建对象,DML语句修改对象,和查询是检索数据 等在数据库中的处理方式。
Stages of SQL Processing
下图描述了SQL处理的常规阶段:parsing(解析),optimization(优化),row source generation(产生行源),execution(执行)。数据库可能会忽略其中的一些阶段,这取决于具体的语句。

SQL Parsing
如上图所示,SQL处理的第一阶段是parsing(解析)。这个步骤涉及到将SQL语句分片,然后放入到一个数据结构,这样后面的步骤才能对它进行处理。
当一个应用程序发送了一条SQL语句,应用程序产生一个parse call到数据库去做语句执行的预备工作。Parse call打开或创建一个cursor,cursor是 session-specific(具体会话)的private SQL area的句柄,private SQL area持有解析后的SQL语句以及其他的处理信息。Cursor和private SQL area都在PGA中。
在parse call的过程中,数据库执行了以下检查:
·Syntax Check
·Semantic Check
·Shared Pool Check
预先检查将在语句执行以前就识别出错误。有一些错误是没办法在解析阶段捕获的,比如数据库会遇到死锁,或数据转换时的错误,不过它们仅在语句执行过程中发生。
SyntaxCheck(语法检查)
Oracle数据库检查每个SQL语句,保证语法正确。一个语句违犯了 well-formed SQL语法规则,将无法通过检查。举个例子,下面的语句将失败,因为关键字FROM拼写错误为FORM:
SQL> SELECT * FORM employees;
SELECT * FORM employees
*
ERROR at line 1:
ORA-00923: FROM keyword not found whereexpected
SemanticCheck(语义检查)
一个语句的语义,就是它的含义。因此语义检查确定一个语句是否是有意义的,举个例子,语句中的对象和列是否都存在。一个语法正确的语句可能会在语义检查阶段失败,像下面例子显示的,对于一个不存在的表,进行的查询:
SQL> SELECT * FROM nonexistent_table;
SELECT * FROM nonexistent_table
*
ERROR at line 1:
ORA-00942: table or view does not exist
SharedPool Check(共享池检查)
在解析过程中,数据库会执行一个shared pool check来确定它是否可以跳过 语句解析中资源密集的步骤。为此,数据库使用了一个hashing 算法来为每个SQL语句都产生一个hash值。语句的hash值叫 SQL ID,在V$SQL.SQL_ID列显示。
但一个用户提交一个SQL语句,数据库会检索所有的shared SQL area,来查看是否存在相同hash值的已经解析过的语句。一个SQL语句的hash值和下面这些值是有区别的:
·Memory address for the statement(语句的内存地址)
Oracle数据库使用SQL_ID 在一个查阅表中 执行一个带键值的读取。通过这种方式,数据库获取该语句所有可能的内存地址。
·语句一个执行计划的hash 值
一个SQL语句可以在shared pool中有多个计划。每个计划都有一个不同的hash值。如果相同的SQL_ID 有多个计划hash 值,那么数据库则会知道针对这个SQL_ID存在多个计划。
解析操作分为下面类型,依赖于提交的语句类型以及hash检查的结果:
·Hard parse(硬解析)
如果Oracle数据库不能重用已经存在的,那么它必须对语句创建一个新的可执行版本。这个操作称之为硬解析,或一个library cache miss。数据库对于DDL语句 总是执行硬解析。
在硬解析的执行过程中,数据库会访问很多次library cache和data dictionary cache 来检查数据字典。当数据库访问这些区域,它使用了一个串行化的装置,称之为latch 在所请求的对象上。这样它们的定义就不会发生变化。Latch争用会减少并发,以及增加语句的执行时间。
·Soft parse(软解析)
任何不是硬解析的解析,都叫软解析。如果提交的语句 和shared pool中可重用SQL语句一直,那么Oracle数据库会重用已经存在的代码。这个代码的重用,也叫做library cache hit。
软解析们 执行的工作并不是完全相同的。举个例子,配置会话shared SQL area在一些时候可以减少软解析们的latching,使它们更软。
正常情况下,软解析要比硬解析更合适,因为数据库跳过了优化 和行源产生的步骤,直接到执行。
下图是专有服务结构中执行 UPDATE语句时 shared pool check(检查)的简化代表图

如果检查确定语句在shared pool中有相同的hash值,那么数据库执行语义和环境检查来确定语句的意思是否相同。光语法相同是不够的。举个例子,假设两个不同的用户登录到数据库,并发布了下面的SQL语句:
CREATE TABLE my_table ( some_col INTEGER );
SELECT * FROM my_table;
两个用户发布的SELECT语句,语法相同,但my_table表,却是两个不同schema 中的。这个语义是完全不同的,它意味着第二个语句是不能重用第一个语句解析后的代码的。
即使两个语句语义一样,但是环境差异也可能会强制导致硬解析。在这种情况下,环境是指session中会对执行计划产生 造成影响的所有设置的总称,这些设置有work area size或optimizer 设置等。
思考下面 一个单独用户执行的一系列SQL语句:
ALTER SYSTEM FLUSH SHARED_POOL;
SELECT * FROM my_table;
ALTER SESSION SET OPTIMIZER_MODE=FIRST_ROWS;
SELECT * FROM my_table;
ALTER SESSION SET SQL_TRACE=TRUE;
SELECT * FROM my_table;
在前面这案例中,相同的SELECT语句,在三个不同的优化器环境中执行。理论上来说,数据库会为三个语句 分别创建三个Shared SQL area以及强制每个语句进行硬解析。
SQL Optimization(SQL优化)
如Overview of the Optimizer里面介绍的,查询优化是一个处理过程,是选择执行一个SQL语句 最效率的途径的处理过程。数据库基于收集的统计信息来优化查询。优化器会用到 行的数量,数据集的大小,以及其他因素去产生一些可能的执行计划,为每一个计划赋予一个数字化的cost(成本)。数据库将使用成本最低的计划。
数据库必须为每一个第一无二的DML语句执行最少一次的硬解析,以及在解析过程中执行优化。DDL语句永远不优化,除非它包括了一个DML组件,如一个子查询。这个DML组件需要优化。
SQL Row Source Generation(SQL行源产生)
行源产生器是一个软件,它从优化器中 接受优化后的执行计划 然后产生一个称之为query plan(查询计划)的迭代计划,它供数据库的其余部分使用。这个迭代计划是一个二进制程序,由SQL虚拟机执行,产生结果集。
查询计划采用组合多个步骤的形式。每步返回一个row set(行集)。这个里面的行要么是被下一步使用,要么被最后一步使用,然后反馈给执行SQL语句的应用。
一个row source(行源)就是一步中返回的 row set,且带有能够迭代该row set的控制结构。
行源可以是一个表,视图,或一个join或grouping操作的结果。
行源产生器 生成一个 row source tree(行源树),它是行源的一个集合(汇总)。行源树显示了下面信息:
·语句相关的表的顺序
·在语句中提及的每个表的访问方法
·语句中join语句影响的表的 join方法
·如果filter,sort,或aggregation等的数据操作
下面案例显示了当AUTOTRACE 开启时 一个SELECT语句的执行计划。这个语句的执行计划就是row source generator 输出的东西。
Example 7-6 Execution Plan
SELECT e.last_name, j.job_title,d.department_name
FROM hr.employees e, hr.departments d, hr.jobs j
WHERE e.department_id = d.department_id
AND e.job_id = j.job_id
AND e.last_name LIKE 'A%' ;
Execution Plan
----------------------------------------------------------
Plan hash value: 975837011
---------------------------------------------------------------------------------------------
| Id |Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 |SELECT STATEMENT | | 3 | 189 | 7 (15)| 00:00:01 |
|* 1| HASH JOIN | | 3 | 189 | 7 (15)| 00:00:01 |
|* 2| HASH JOIN | | 3 | 141 | 5 (20)| 00:00:01 |
| 3| TABLE ACCESS BY INDEX ROWID|EMPLOYEES | 3 | 60 | 2 (0)| 00:00:01 |
|* 4| INDEX RANGE SCAN | EMP_NAME_IX | 3 | | 1 (0)| 00:00:01 |
| 5| TABLE ACCESS FULL | JOBS | 19 | 513 | 2 (0)| 00:00:01 |
| 6| TABLE ACCESS FULL | DEPARTMENTS | 27 | 432 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified byoperation id):
---------------------------------------------------
1 -access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
2 -access("E"."JOB_ID"="J"."JOB_ID")
4 -access("E"."LAST_NAME" LIKE 'A%')
filter("E"."LAST_NAME" LIKE 'A%')
SQL Execution(SQL执行)
在执行过程中,SQL引擎执行通过 行源产生器产生的树中的每个row source。这一步是唯一一个DML处理过程中的强制步骤。
下图是一个execution tree(执行树),也称之为 parse tree(解析树),它显示了一步的行源流向另外一步。正常情况下,步骤执行的顺序,和计划中顺序相反,所以,你读一个计划要通过从底往上读。Operation列的初始的空格 描述了等级关系。举个例子,如果操作的名字 前面有两个空格,那么这个操作就是 前面有一个空格的操作的子操作。名字前面有一个空格的操作是SELECT语句本身的子操作。

在上面图中,树中的每个点作为一个行源,它的意味着 执行计划中的每一步 要么从数据库中检索行,要么从其他一个或多个行源中接收行。SQL引擎执行每个行源入下列:
·黑色盒子的步骤 从数据库的对象中物理检索行。这些步骤叫 access paths(访问路径),或者叫从数据库中检索数据的技术。
O 步骤6 使用了 full table scan 将departments表中的所有行都检索回来了
O 步骤5 使用了 full table scan 将jobs 表中的所有行都检索回来了
O 步骤4 扫描emp_name_ix索引,顺序的扫描扫描开头是字母A的所有key,然后捡回对应的rowid。举个例子。Atkinson关联的rowid是AAAPzRAAFAAAABSAAe。
O 步骤3 从employees表中检索数据,按照步骤4返回的rowid。举个例子,数据库使用rowid AAAPzRAAFAAAABSAAe 去检索 Atkinson的对应行。
·干净盒子表示 对行源的操作
O 步骤2 执行了一个hash join,接受从步骤3 和5的行源,将从步骤5返回行源的每行 join到 步骤 3 中对应的行,然后返回结果行到 步骤 1
举个例子,雇员Atkinson 的行 和job name Stock Clerk进行关联
O 步骤1 执行了另外一个 hash join,接受 步骤2 和6的行源,join 每行,然后返回结果给客户端
在一些执行计划中,步骤是迭代的,且是其他顺序的。之前7-6显示的计划就是迭代的,因为SQL引擎从index移动到表,然后到客户端,并多次重复这些步骤。
在执行期间,数据库从磁盘将数据读到内存(如果数据没在内存的话)。数据库同样会取得所需要的lock和latch来保证数据完整性 并为SQL执行过程中做的任何改变记录日志。SQL语句处理的最终阶段,就是关闭cursor。
How Oracle Database ProcessesDML(Oracle数据库怎样处理DML
绝大部分DML语句都有一个查询组件,在查询中,游标执行后,会将结果放入称之为result set(结果集)的行集。
结果集中的行 可以每次取回一行或一组。在取回阶段,数据库选择行,如果需要,还会排序行。每次取回后会连续检索结果中另外的行,直到最后一行被取回为止。
正常情况下,数据库在最后一行返回之前 是无法确认要检索行的数目。Oracle数据库检索数据来相应fetch call,因此数据库读取的行越多,工作就越多。有一些查询,数据库要求返回第一行越快越好。而其他一些则是先创建整个结果集,然后再返回第一行。
Read Consistency(读一致性)
正常情况下,一个查询检索数据时会用到Oracle数据库读一致性机制。这个机制,使用了 undo 数据 去显示数据之前的版本,保证了一个查询读取的所有数据块 都在一个时间点是一致的。
举一个读一致性的例子,假设一个查询用full table scan 读了100个数据块。这个查询处理前10个块时,另外一个会话使用DML语句对 块75进行了修改。当第一个会话到达 块75时,它发现了改变,以及通过利用undo数据 取回之前旧的,没被第二个会话修改过的版本,这个会在内存中构建一个 块75的 非当前版本。
Data Changes(数据更改)
DML语句修改数据时,通过使用读一致性来获取在修改开始时满足条件的数据。之后,语句会将检索回 当前状态 的数据库,并对其做 需要的修改。数据库会执行其他与数据修改相关的动作,比如产生redo和undo数据。
How Oracle database ProcessesDDL(Oracle数据库如何处理DDL)
Oracle数据库处理DDL不同于DML。举个例子,当你创建一个表,数据库就不会对CREATE TABLE语句进行优化,而是解析完DDL语句,直接执行它。
数据库处理DDL不同的原因是因为它是一种在数据字典中定义一个对象的方式。正常来说,Oracle数据库必须解析和执行许多的recursive SQL(递归SQL)语句 来完成一个DDL语句。
假设你如下面一样创建了一个表:
CREATE TABLE mytable (mycolumn INTEGER);
正常来说,数据库需要运行很多的递归语句来完成前面这个语句。递归语句会执行如下面这些动作:
·在CREATE TABLE语句执行之前发布一个COMMIT
·验证用户是否有创建表的权限
·确定表要放在哪个表空间
·确保该表空间的quota足够
·确保schema中没有重名对象
·在数据字典中插入定义表的行
·如果DDL语句执行成功,发布commit,如果失败 发布rollback;















 169
169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









