







Autonomous driving - Car detection
Welcome to your week 3 programming assignment. You will learn about object detection using the very powerful YOLO model. Many of the ideas in this notebook are described in the two YOLO papers: Redmon et al., 2016 (https://arxiv.org/abs/1506.02640) and Redmon and Farhadi, 2016 (https://arxiv.org/abs/1612.08242).
You will learn to:
- Use object detection on a car detection dataset
- Deal with bounding boxes
Run the following cell to load the packages and dependencies that are going to be useful for your journey!
import argparse
import os
import keras
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
import scipy.io
import scipy.misc
import numpy as np
import pandas as pd
import PIL
import tensorflow as tf
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras import backend as K
from keras.layers import Input, Lambda, Conv2D
from keras.models import load_model, Model
from yolo_utils import read_classes, read_anchors, generate_colors, preprocess_image, draw_boxes, scale_boxes
from yad2k.models.keras_yolo import yolo_head, yolo_boxes_to_corners, preprocess_true_boxes, yolo_loss, yolo_body
%matplotlib inline
Important Note: As you can see, we import Keras’s backend as K. This means that to use a Keras function in this notebook, you will need to write: K.function(...).
1 - Problem Statement
You are working on a self-driving car. As a critical component of this project, you’d like to first build a car detection system. To collect data, you’ve mounted a camera to the hood (meaning the front) of the car, which takes pictures of the road ahead every few seconds while you drive around.
You’ve gathered all these images into a folder and have labelled them by drawing bounding boxes around every car you found. Here’s an example of what your bounding boxes look like.
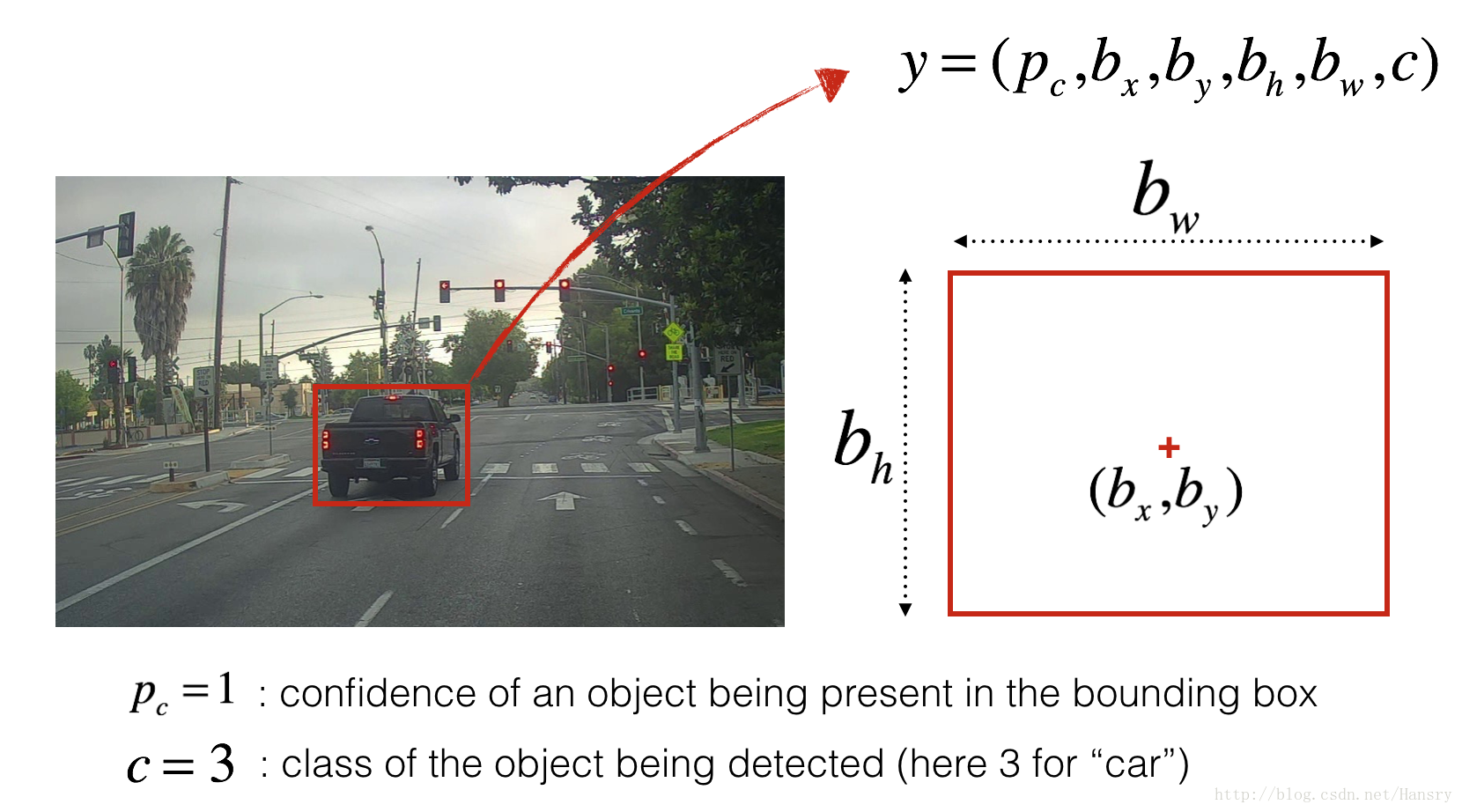
If you have 80 classes that you want YOLO to recognize, you can represent the class label c c c either as an integer from 1 to 80, or as an 80-dimensional vector (with 80 numbers) one component of which is 1 and the rest of which are 0. The video lectures had used the latter representation; in this notebook, we will use both representations, depending on which is more convenient for a particular step.
In this exercise, you will learn how YOLO works, then apply it to car detection. Because the YOLO model is very computationally expensive to train, we will load pre-trained weights for you to use.
2 - YOLO
YOLO (“you only look once”) is a popular algoritm because it achieves high accuracy while also being able to run in real-time. This algorithm “only looks once” at the image in the sense that it requires only one forward propagation pass through the network to make predictions. After non-max suppression, it then outputs recognized objects together with the bounding boxes.
2.1 - Model details
First things to know:
- The input is a batch of images of shape (m, 608, 608, 3)
- The output is a list of bounding boxes along with the recognized classes. Each bounding box is represented by 6 numbers ( p c , b x , b y , b h , b w , c ) (p_c, b_x, b_y, b_h, b_w, c) (pc,bx,by,bh,bw,c) as explained above. If you expand c c c into an 80-dimensional vector, each bounding box is then represented by 85 numbers.
We will use 5 anchor boxes. So you can think of the YOLO architecture as the following: IMAGE (m, 608, 608, 3) -> DEEP CNN -> ENCODING (m, 19, 19, 5, 85).
Lets look in greater detail at what this encoding represents.
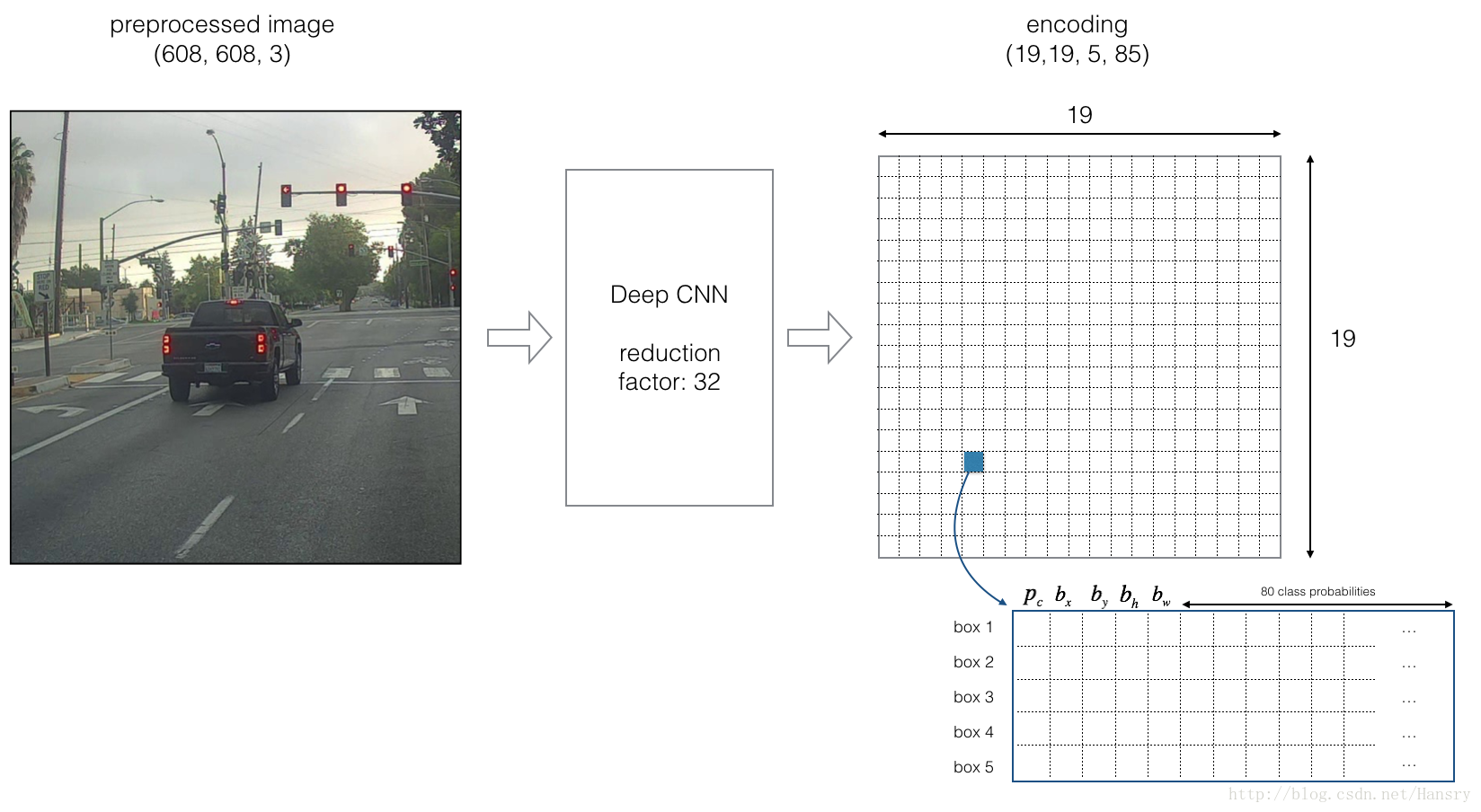
If the center/midpoint of an object falls into a grid cell, that grid cell is responsible for detecting that object.
Since we are using 5 anchor boxes, each of the 19 x19 cells thus encodes information about 5 boxes. Anchor boxes are defined only by their width and height.
For simplicity, we will flatten the last two last dimensions of the shape (19, 19, 5, 85) encoding. So the output of the Deep CNN is (19, 19, 425).
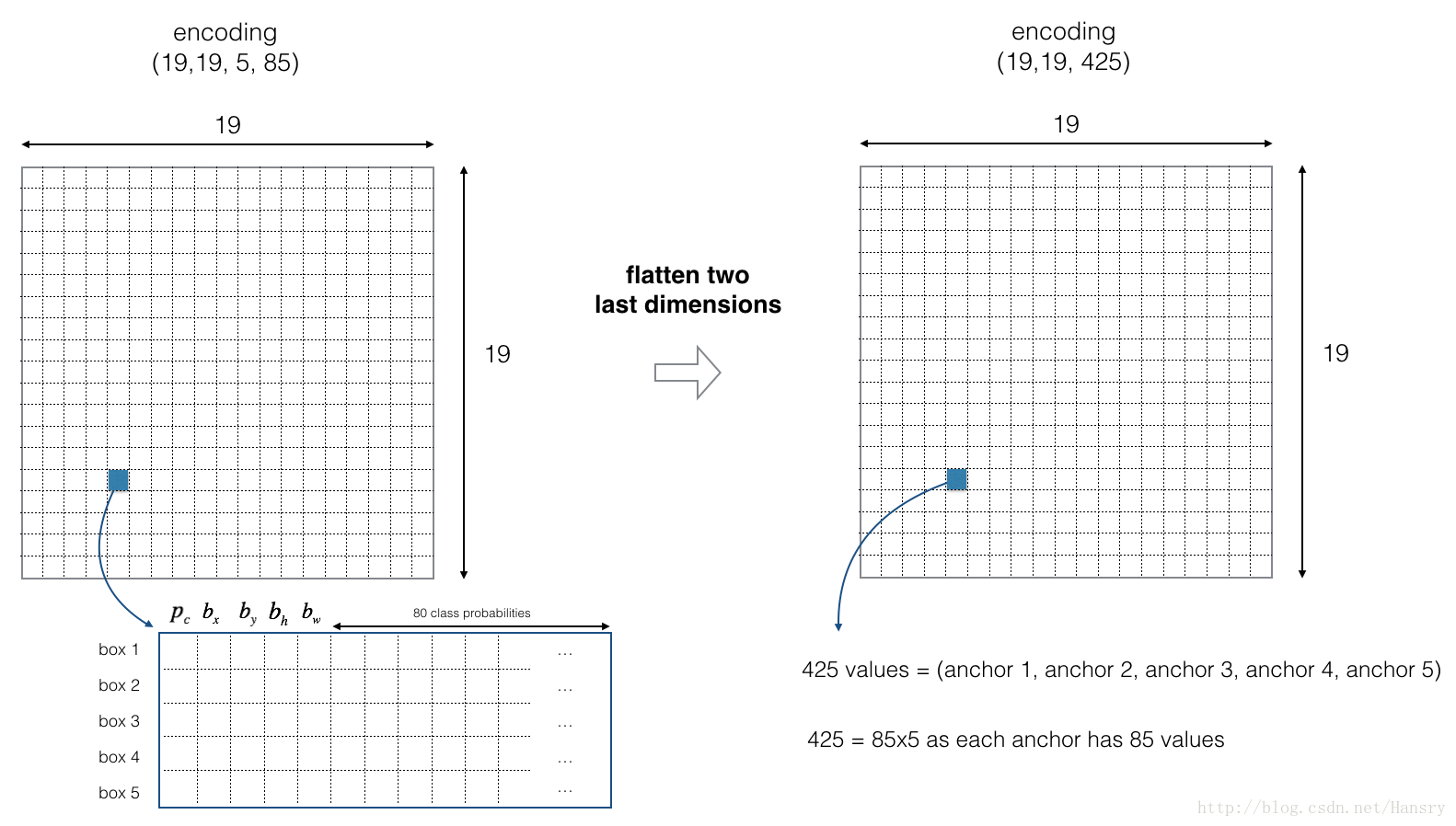
Now, for each box (of each cell) we will compute the following elementwise product and extract a probability that the box contains a certain class.

Here’s one way to visualize what YOLO is predicting on an image:
- For each of the 19x19 grid cells, find the maximum of the probability scores (taking a max across both the 5 anchor boxes and across different classes).
- Color that grid cell according to what object that grid cell considers the most likely.
Doing this results in this picture:
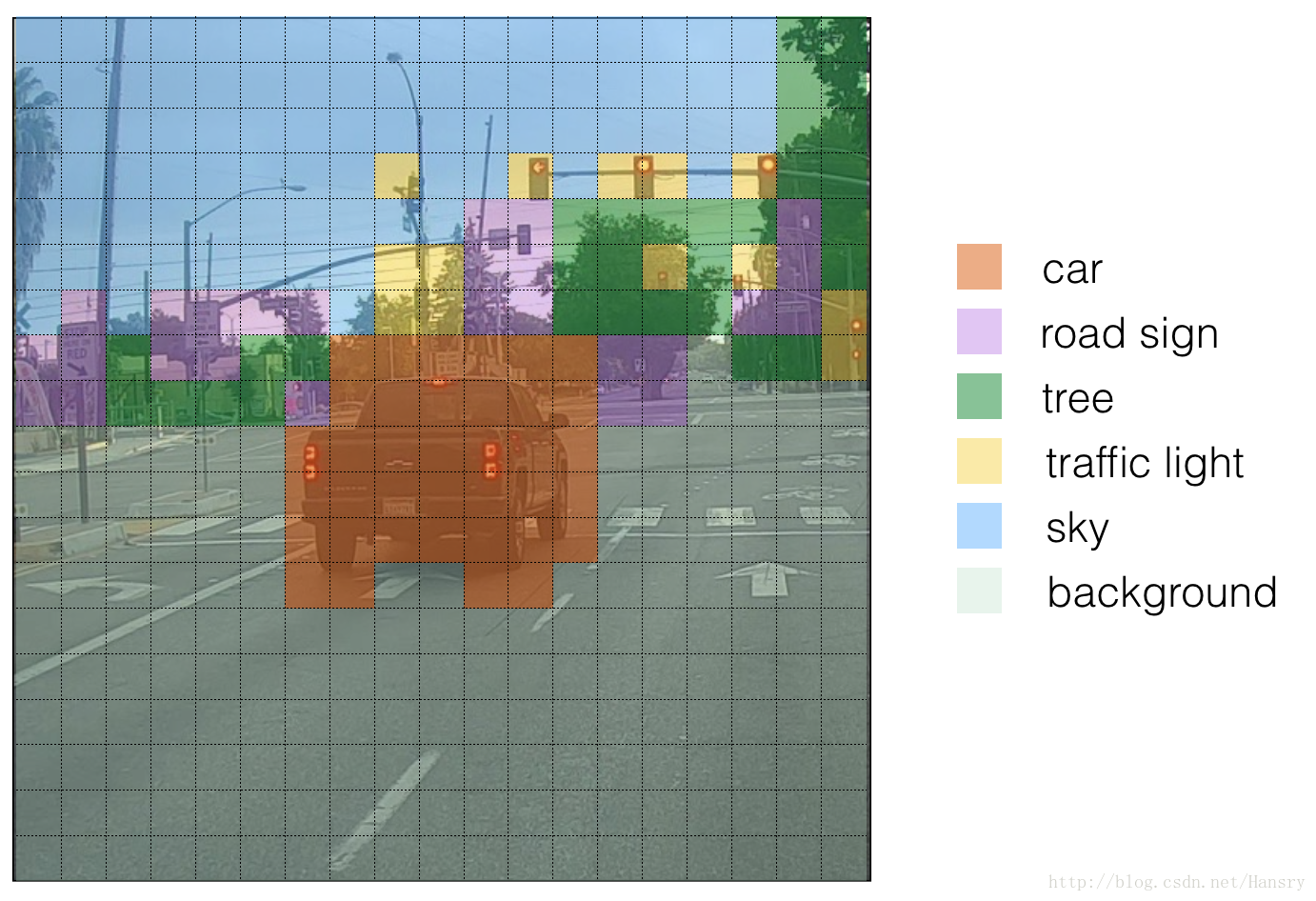
Note that this visualization isn’t a core part of the YOLO algorithm itself for making predictions; it’s just a nice way of visualizing an intermediate resu
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1245
1245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









