







Linux路由表的结构与算法分析
Linux路由表的结构与算法分析
黄一文
路由是网络栈的核心部分。路由表本身的设计很大情度上影响着路由的性能,并且好的设计能减少系统资源的消耗,这两方面尤其体现在路由表的查找上。目前的内核路由存在两种查找算法,一种为HASH算法,另一种为LC-trie算法,前者是目前内核使用的缺省算法,而后者更适用在超大路由表的情况,它在这种情况提高查找效率的同时,大大地增加了算法本身的复杂性和内存的消耗。综上,这两种算法各有其适用的场合,本文分析了基于2.6.18内核路由部分的代码在HASH算法上路由表结构的实现,并且在文章最后给出了一个简单的策略路由的应用。
一、路由表的结构
为了支持策略路由,Linux使用了多个路由表而不是一个,即使不使用策略路由,Linux也使用了两个路由表,一个用于上传给本地上层协议,另一个则用于转发。Linux使用多个路由表而不是一个,使不同策略的路由存放在不同的表中,有效地被免了查找庞大的路由表,在一定情度上提高了查找了效率。
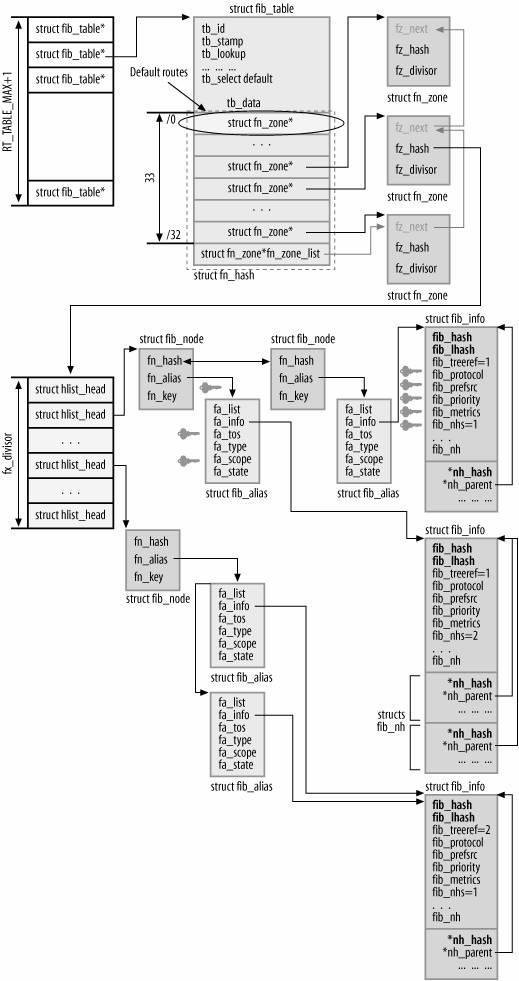
路由表本身不是由一个结构表示,而是由多个结构组合而成。路由表可以说是一个分层的结构组合。在第一层,它先将所有的路由根据子网掩码(netmask)的长度(0~32)分成33个部分(struct fn_zone),然后在同一子网掩码(同一层)中,再根据子网的不同(如10.1.1.0/24和10.1.2.0/24),划分为第二层(struct fib_node),在同一子网中,有可能由于TOS等属性的不同而使用不同的路由,这就是第三层(struct fib_alias),第三层结构表示一个路由表项,而每个路由表项又包括一个相应的参数,如协议,下一跳路由地址等等,这就是第四层(struct fib_info)。分层的好处是显而易见的,它使路由表的更加优化,逻辑上也更加清淅,并且使数据可以共享(如struct fib_info),从而减少了数据的冗余。
|
struct fib_table *fib_tables[RT_TABLE_MAX+1]; // RT_TABLE_MAX 为255
|
|
struct fib_table {
unsigned char tb_id;
unsigned tb_stamp;
int (*tb_lookup)(struct fib_table *tb, const struct flowi *flp, struct fib_result *res);
int (*tb_insert)(struct fib_table *table, struct rtmsg *r,
……
void (*tb_select_default)(struct fib_table *table,
const struct flowi *flp, struct fib_result *res);
unsigned char tb_data[0];
};
|
 +
+
图1(引自[1])
这个结构中包括这个表的ID,以及主要的一些用于操作路由表的函数指针,这里我们只关心最后一个域――tb_data[0],这是一个零长的数组,它在内核中也较为常见,它表示
|
struct fn_hash {
struct fn_zone *fn_zones[33];
struct fn_zone *fn_zone_list;
};
|
|
struct fn_zone {
struct fn_zone *fz_next; /* Next not empty zone */
struct hlist_head *fz_hash; /* Hash table pointer */
int fz_nent; /* Number of entries */
int fz_divisor; /* Hash divisor */
u32 fz_hashmask; /* (fz_divisor - 1) */
#define FZ_HASHMASK(fz) ((fz)->fz_hashmask)
int fz_order; /* Zone order */
u32 fz_mask;
#define FZ_MASK(fz) ((fz)->fz_mask)
};
|
这个fn_zone域就是我们上面提前的结构,用于将路由根据子网掩码的长度分开成33个部分,其中fn_zones[0]用于默认网关。而fn_zone_list域就是将正在使用的fn_zone链成一个链表。接着再深入到struct fn_zone结构中:
这个结构中有两个域比较重要,一个为fz_hash域,它指向一个HASH表的表头,这个HASH的长度是fz_divisor。并且这个HASH表的长度是可变的,当表长达到一个限定值时,将重建这个HASH表,被免出现HASH冲突表过长造成查找效率降低。
为了提高查找的效率,内核使用了大量的HASH表,而路由表就是一个例子。在图1中可以看到,等长子网掩码的路由存放在同一个fn_zone中,而根据到不同子网(fib_node)的路由键值(fn_key),将它HASH到相应的链表中。
|
struct fib_node {
struct hlist_node fn_hash;
struct list_head fn_alias;
u32 fn_key;
};
|
这个键值其实就是这个子网值了(如10.1.1.0/24,则子网值为10.1.1),得到这个键值通过n = fn_hash()函数HASH之后就是这个子网对应的HASH值,然后就可以插入到相应的fz_hash[n]链表中了。冲突的fib_node由fn_hash域相链,而fn_alias则是指向到达这个子网的路由了。
|
struct fib_alias {
struct list_head fa_list;
struct rcu_head rcu;
struct fib_info *fa_info;
u8 fa_tos;
u8 fa_type;
u8 fa_scope;
u8 fa_state;
};
|
当到达这个子网的路由由于TOS等属性的不同可存在着多个路由时,它们就通过fib_alias中fa_list域将这些路由表项链成一个链表。这个结构中的另一个域fa_info指向一个fib_info结构,这个才是存放真正重要路由信息的结构。
|
struct fib_info {
struct hlist_node fib_hash;
struct hlist_node fib_lhash;
……
int fib_dead;
unsigned fib_flags;
int fib_protocol;
u32 fib_prefsrc;
u32 fib_priority;
……
int fib_nhs;
struct fib_nh fib_nh[0];
#define fib_dev fib_nh[0].nh_dev
};
|
这个结构里面是一个用于路由的标志和属性,其中最重要的一个域是fib_nh[0],在这里,我们再次看到了零长数组的应用,它是通过零长来实现变长结构的功能的。因为,我们需要一个定长的fib_info结构,但是在这个结构末尾,我们需要的fib_nh结构的个数是不确定的,它在运行时确定。这样,我们就可以通过这种结构组成,在运行时为fib_info分配空间的时候,同时在其末尾分配所需的若干个fib_nh结构数组,并且这个结构数组可以通过fib_info->fib_nh[n]来访问,在完成fib_info的分配后将fib_nhs域置为这个数组的长度。
另一方面,fib_info也是HASH表的一个应用,结构中存在着两个域,分别是fib_hash 和fib_lhash,它们都用于HASH链表。这个结构在完成分配后,将被用fib_hash域链入fib_info_hash表中,如果这个路由存在首选源地址,这个fib_info将同时被用fib_lhash链入fib_info_laddrhash表中。这样,就可以根据不同目的实现快速查找了。
Struct fib_nh也是一个重要的结构。它存放着下一跳路由的地址(nh_gw)。刚刚已经提到,一个路由(fib_alias)可能有多个fib_nh结构,它表示这个路由有多个下一跳地址,即它是多路径(multipath)的。下一跳地址的选择也有多种算法,这些算法都是基于nh_weight,nh_power域的。nh_hash域则是用于将nh_hash链入HASH表的。
|
struct fib_nh {
struct net_device *nh_dev;
struct hlist_node nh_hash;
struct fib_info *nh_parent;
unsigned nh_flags;
unsigned char nh_scope;
#ifdef CONFIG_IP_ROUTE_MULTIPATH
int nh_weight;
int nh_power;
#endif
#ifdef CONFIG_NET_CLS_ROUTE
__u32 nh_tclassid;
#endif
int nh_oif;
u32 nh_gw;
};
|
二、路由的查找
路由的查找速度直接影响着路由及整个网络栈的性能。路由的查找当然首先发生在路由缓存中,当在缓存中查找失败时,它再转去路由表中查找,这是本文所关注的地方。
上一节已经详细地描述了路由表的组成。当一个主要的IP层将要发送或接收到一个IP数据包时,它就要调用路由子系统完成路由的查找工作。路由表查找就是根据给定的参数,在某一个路由表中找到合适的下一跳路由的地址。
上面已提到过,当一个主机不支持策略路由时,它只使用了两个路由表,一个是ip_fib_local_table,用于本地,另一个是ip_fib_main_table,用于接发。只有在查找ip_fib_local_table表时没有找到匹配的路由(不是发给本地的)它才会去查找ip_fib_main_table。当一个主机支持策略路由时,它就有可能存在着多个路由表,因而路由表的选择也就是查找的一部分。路由表的选择是由策略来确定的,而策略则是由应用(用户)来指定的,如能过ip rule命令:
|
ip rule add from 10.1.1.0/24 table TR1
ip rule add iff eth0 table RT2
|
如上,第一条命令创建了基于源地址路由的一条策略,这个策略使用了RT1这个路由表,第二条命令创建了基于数据包入口的一个策略,这个策略使用了RT2这个路由表。当被指定的路由表不存在时,相应的路由表将被创建。
第二步就是遍历这个路由表的fn_zone,遍历是从最长前缀(子网掩码最长)的fn_zone开始的,直到找到或出错为止。因为最长前缀才是最匹配的。假设有如下一个路由表:
|
dst nexthop dev
10.1.0.0/16 10.1.1.1 eth0
10.1.0.0/24 10.1.0.1 eth1
|
它会先找到第二条路由,然后选择10.1.0.1作为下一跳地址。但是,如果由第二步定位到的子网(fib_node)有多个路由,如下:
|
dst nexthop dev
10.1.0.0/24 10.1.0.1 eth1
10.1.0.0/24 10.1.0.2 eth1
|
到达同一个子网有两个可选的路由,仅凭目的子网无法确定,这时,它就需要更多的信息来确定路由的选择了,这就是用于查找路由的键值(struct flowi)还包括其它信息(如TOS)的原因。这样,它才能定位到对应一个路由的一个fib_alias实例。而它指向的fib_info就是路由所需的信息了。
最后一步,如果内核被编译成支持多路径(multipath)路由,则fib_info中有多个fin_nh,这样,它还要从这个fib_nh数组中选出最合适的一个fib_nh,作为下一跳路由。
三、路由的插入与删除
路由表的插入与删除可以看看是路由查找的一个应用,插入与删除的过程本身也包含一个查找的过程,这两个操作都需要检查被插入或被删除的路由表项是否存在,插入一个已经存在的路由表项要做特殊的处理,而删除一个不存在的路由表项当然会出错。
下面看一个路由表插入的例子:
|
ip route add 10.0.1.0/24 nexthop via 10.0.1.1 weight 1
nexthop via 10.0.1.2 weight 2
table RT3
|
这个命令在内核中建立一条新的路由。它首先查找路由表RT3中的子网掩码长为24的fn_zone,如果找不到,则创建一个fn_zone。接着,继续查找子网为10.0.1的fib_node,同样,如果不存在,创建一个fib_node。然后它会在新建一个fib_info结构,这个结构包含2个fib_nh结构的数组(因为有两个nexthop),并根据用户空间传递过来的信息初始化这个结构,最后内核再创建一个fib_alias结构(如果先前已经存在,则出错),并用fib_nh来创始化相应的域,最后将自己链入fib_node的链中,这样就完成了路由的插入操作。
路由的删除操作是插入操作的逆过程,它包含一系列的查找与内存的释放操作,过程比较简单,这里就不再赘述了。
四、策略路由的一个简单应用
Linux系统在策略路由开启的时候将使用多个路由表,它不同于其它某些系统,在所有情况下都只使用单个路由表。虽然使用单个路由表也可以实现策略路由,但是如本文之前所提到的,使用多个路由表可以得到更好的性能,特别在一个大型的路由系统中。下面只通过简单的情况说明Linux下策略路由的应用。
如图2,有如下一个应用需求,其中网关服务器上有三个网络接口。接口1的IP为172.16.100.1,子网掩码为255.255.255.0,网关gw1为a.b.c.d,172.16.100.0/24这个网段的主机可以通过这个网关上网;接口2的IP是172.16.10.1,子网掩码同接口一,网关gw2为e.f.g.h,172.16.10.0/24这个网段的主机可以通过这个网关上网;接口0的IP为192.168.1.1,这个网段的主机由于网络带宽的需求需要通过e.f.g.h这个更快的网关路由出去。
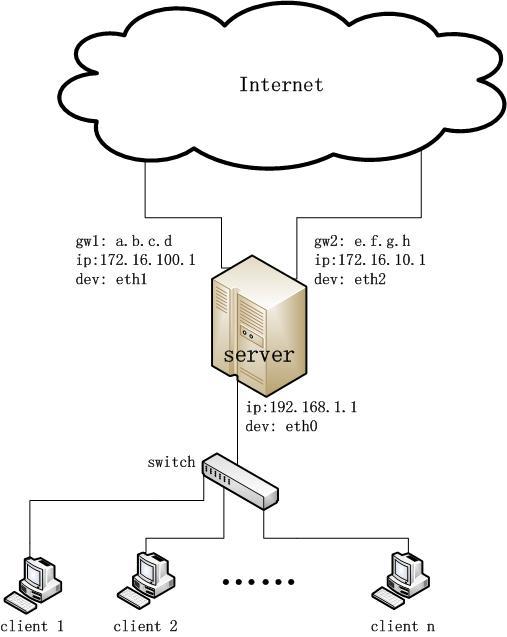
图 2
步骤一:设置各个网络接口的IP,和默认网关:
|
ip addr add 172.16.100.1/24 dev eth1
ip route add default via a.b.c.d dev eth1
|
其它接口IP的设置和第一个接口一样,这时,如果没有其它设置,则所有的数据通过这个默认网关路由出去。
步骤二:使子网172.16.10.0/24可以通过gw2路由出去
|
ip route add 172.16.10.0/24 via e.f.g.h dev eth2
|
步骤三:添加一个路由表
|
echo “250 HS_RT” >> /etc/iproute2/rt_tables
|
步骤四:使用策略路由使192.168.1.0/24网段的主机可以通过e.f.g.h这个网关上网
|
ip rule add from 192.168.1.0/24 dev eth0 table HS_RT pref 32765
ip route add default via e.f.g.h dev eth2
iptables –t nat –A POSTROUTING –s 192.168.1.0/24 –j MASQUERADE
|
步骤五:刷新路由cache,使新的路由表生效
|
ip route flush cache
|
这样就可以实现了以上要求的策略路由了,并且可以通过traceroute工具来检测上面的设置是否能正常工作。
参考资料:
[1] Understanding Linux Network Internals ,Christian Benvenuti
[2] http://www.kernel.org
[3]http://heuristic.kaist.ac.kr/paper/full-paper/24.%20IP%20Lookup%20Table%20Design%20Using%20LC-Trie%20with%20Memory%20Constraint.pdf
[4] iproute2 man page
[5] iptables howto
[6] http://lartc.org,Linux Advanced Routing & Traffic Control















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









