









引言
最近项目有了上线计划,现在面临着日志收集分析的问题,所以让小编来研究一下日志收集分析架构,下面就给大家分享一下小编搭建的第一套日志框架。
环境搭建过程见Linux系统ELK环境搭建手册
架构图如下:
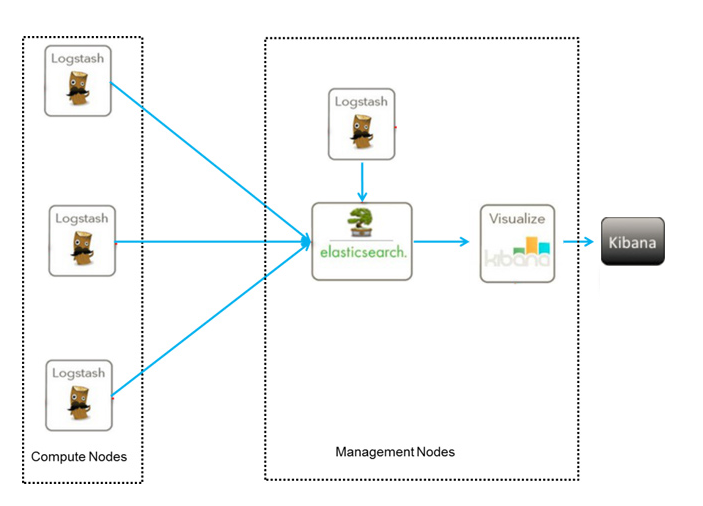
下面说一下这个架构的实现原理,logstash在架构中起到的作用是从每台服务器上的某个路径中的文件中收集数据,并且按照预先编写好的过滤规则来过滤数据,然后按照要求将日志传输到ES集群中,然后通过kibana进行数据的展示.
下面就是比较核心的一步,进行logstash的配置,里面包含对数据输入的配置,数据过滤的配置,数据输出的配置。这三个配置是最重要的。
文件名称为:elasticsearch_output.conf
input {
file {
path => "/var/log/nginx_access.log"
type => "nginx"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
grok {
match => ["message", "%{TIME}\s+(?<Level>(\S+)).*?\((?<http>(\S+))\)\s*%{TIMESTAMP_ISO8601:time}\s+\[(?<uuid>(\S+))\]\s*\[%{IPORHOST:clientip}\].*"]
}
}
output {
elasticsearch {
host => "192.168.22.189"
protocol => "http"
index => "itoo_output-%{type}-%{+YYYY.MM.dd}"
document_type => "nginx"
workers => 5
}
}filter是我们自己编写的过滤规则,这个规则需要我们分析自己的日志,然后利用logsta已经给我编写好的一下正则表达式来完成自己的过滤规则的编写。
下面的地址是已经编写好的正则匹配文档:
https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/grok-patterns
输出我们选择了ES,关于ES的介绍就不在本编博客中介绍,host是我们搭建的ES集群的主节点的ip地址。index就是在es中创建的名称。
然后我们在需要收集日志的服务器上面启动logstash服务运行这个配置文件即可,启动命令为
./logstash -f elasticsearch_output.conf
这样我们就会可以在es中查看已经导入的日志数据,并且当日志文件有更新的时候,logstash会自动将新增加的内容收集并传入到ES中供我们查看。
这个架构已经搭建完成了,但是这存在着几个问题?
第一:编写过滤规则比较费事
第二:如何将一条错误堆栈信息收集成一条信息存储在es库中
这种架构的优缺点
优点:搭建简单,易于上手。
缺点:logstash消耗资源大,运行占用的CPU和内存较高,并且没有消息队列缓存,这样存在数据的丢失的隐患。
架构二:
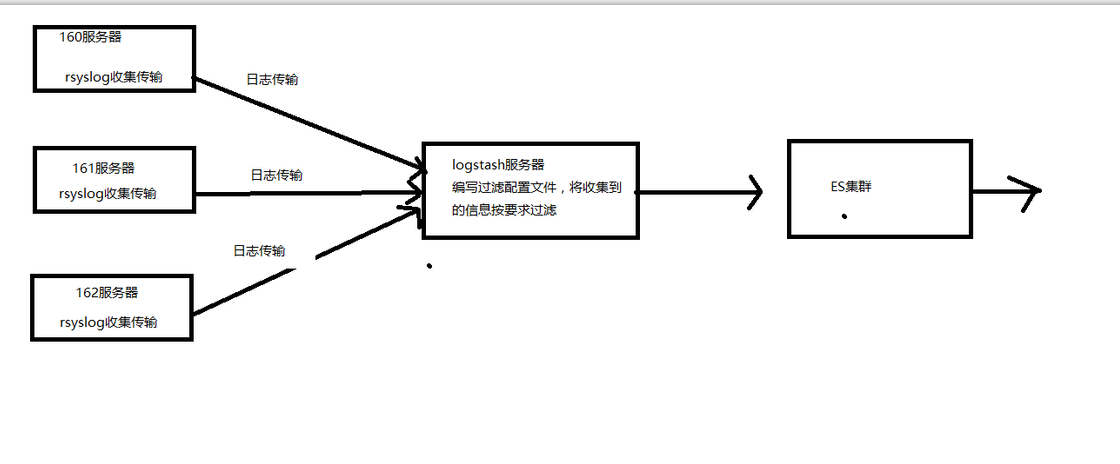
我们选择将Linux自带的rsyslog日志收集系统充当logstash Agent,解决我们日志收集的问题。这样我们将分散每台服务器上面的日志通过rsyslog日志收集到并传输到Logstash服务器上面的某个文件中,然后我们在通过logstash过滤后送到es集群中,在这个架构中,如果日志系统比较大的情况下,我们还可以将logstash做成集群。这样就可以承担更大的日志量了。
这种架构在日志量不是很大的中小型项目中足够使用,这样我们是在一定程度上解决了日志量过大的问题,但是我们并没有解决logstash过滤文件编写的问题,也就说logstash比较难于定义,这是因为logstash是ruby语言编写的,这对于我们java程序员来说不容易。所以我们也没有采用。
对于比较热衷于logstash的 用户,并且数据量比较大的情况下,采用第三种架构
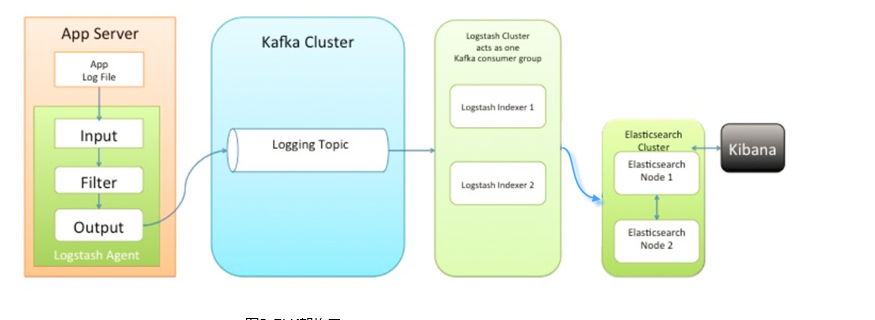
这种架构小编没有搭建,以为我们决定采用EFK架构了,所以对于这种架构,小编知识从理论方面进行了分析,基于上面两种架构的弊端,在架构三中我们引入了kafka消息中间件类似消息队列的功能。并且kafka的集群搭建也是非常容易的,这样如果日志产生量非常大的情况下,我们可以将过剩的日志缓存在kafka集群中,慢慢的提供给logstash集群中进行过滤、传输到ES集群中。这种架构均衡了网络传输、从而降低了网络闭塞尤其是丢失数据的可能性。但是也没有解决logstash占用资源的问题。
通过分析对比我们最终选择flume来代替logstash进行数据的收集和传输。在下面的博客中将分享flume+kafka+ES
框架的学习。















 1516
1516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











