







Recognition. 2015. (Citations: 418).
1 Motivation
All the previous papers used local motion cues to get extra accuracy (e.g. half a second or so). What if the temporal dependencies of interest are much much longer?
2 Recurrent Convolutional Architecture
See Fig. The CNN part is time-invariant and independent at each timestep. In this paper, we focus on three specif tasks, see Fig.
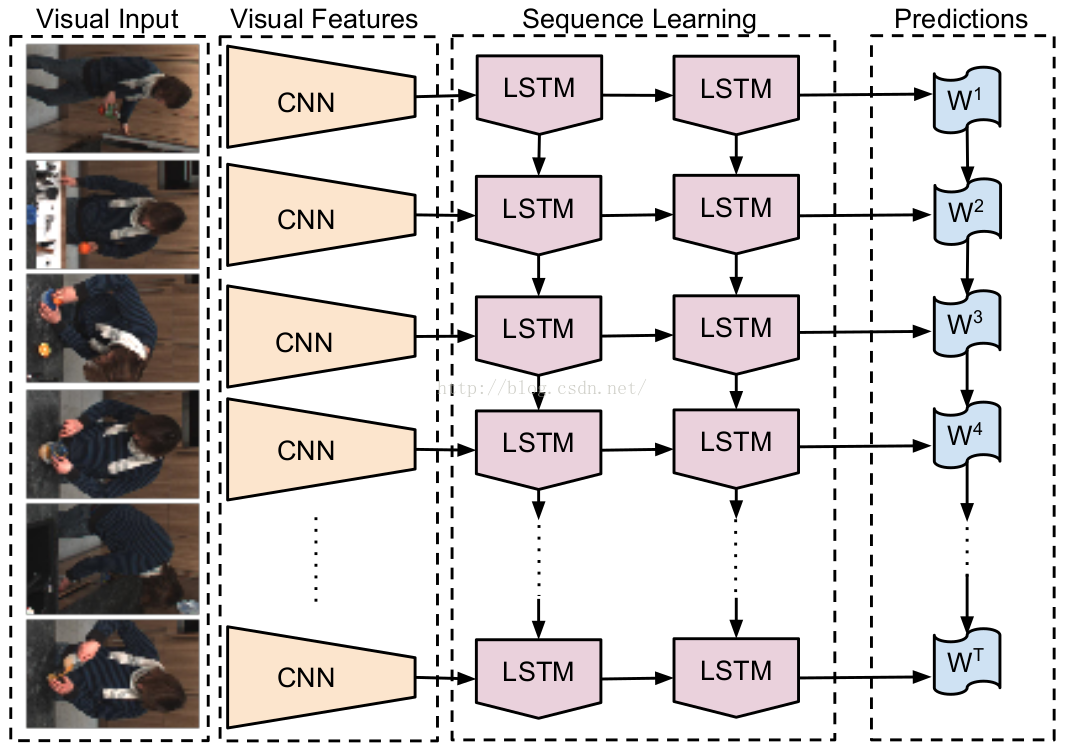
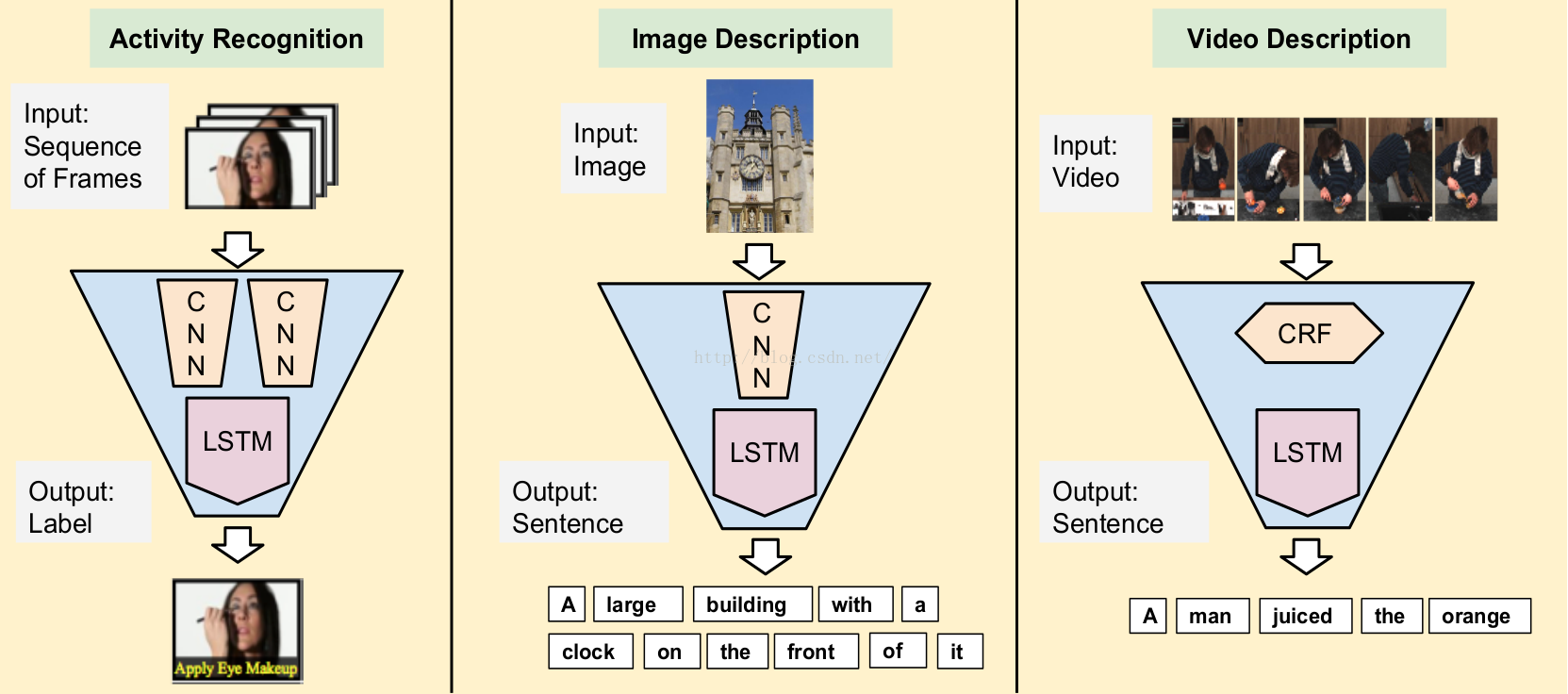
2.1 Video Classification
Sequential input, fixed output. We use late fusion to merge per-timestep predictions. The CNN part can use the ImageNet pre-trained model.
We also consider both RGB and flow inputs. Flow is computed and transformed into a “flow image” by centering x and y flow values around 128 and multiplying by a scalar such
that flow values fall between 0 and 255. A third channel for the flow image is created by calculating the flow magnitude.
2.2 Image Captioning
Fixed input, sequential output. At each timestep, both the image features and the previous word are provided as inputs to the LSTM.
2.3 Video Captioning
Sequential input, sequence output. This is the encoder-decoder style. Input is processed and the decoder outputs are ignored for the first T timesteps, and the predictions are made and “dummy” inputs are ignored for the latter T ′ timesteps.














 7784
7784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









