 深度学习与机器学习实践:神经网络、SVM与无监督学习解析
深度学习与机器学习实践:神经网络、SVM与无监督学习解析





 这篇博客详细介绍了神经网络的学习过程,包括反向传播算法、随机初始化和梯度检查。接着,讨论了在应用机器学习时的策略,如交叉验证和学习曲线,以及如何避免过拟合和欠拟合。文章还涵盖了支持向量机(SVM)的基本概念和优化问题,并讨论了无监督学习中的聚类算法K-means及其挑战。
这篇博客详细介绍了神经网络的学习过程,包括反向传播算法、随机初始化和梯度检查。接着,讨论了在应用机器学习时的策略,如交叉验证和学习曲线,以及如何避免过拟合和欠拟合。文章还涵盖了支持向量机(SVM)的基本概念和优化问题,并讨论了无监督学习中的聚类算法K-means及其挑战。
第五周:
Neural Networks: Learning
关于神经网络的记法:
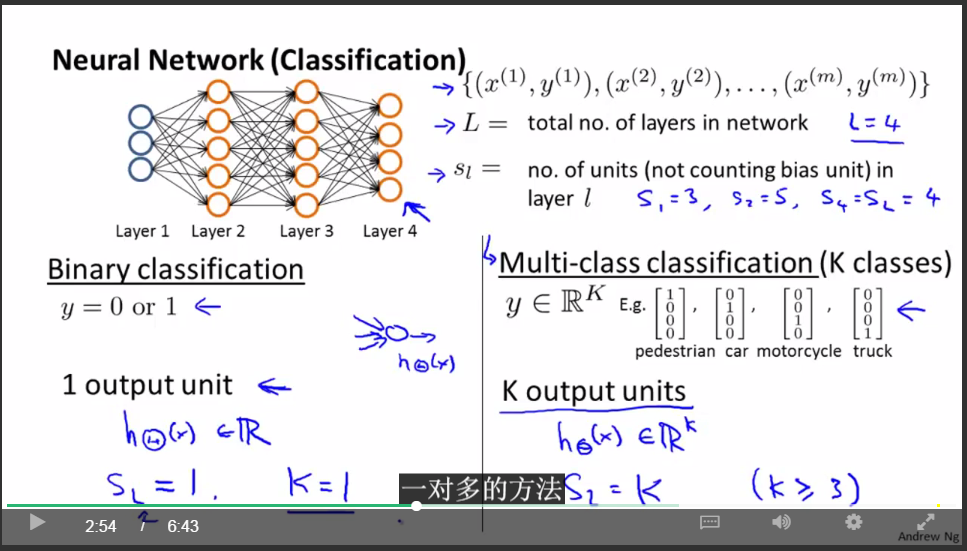
神经网路的代价函数:

直接计算神经网络的各项导数很复杂,为了计算导数,采用反向传播(backpropagation)的算法:


前项传播原理:
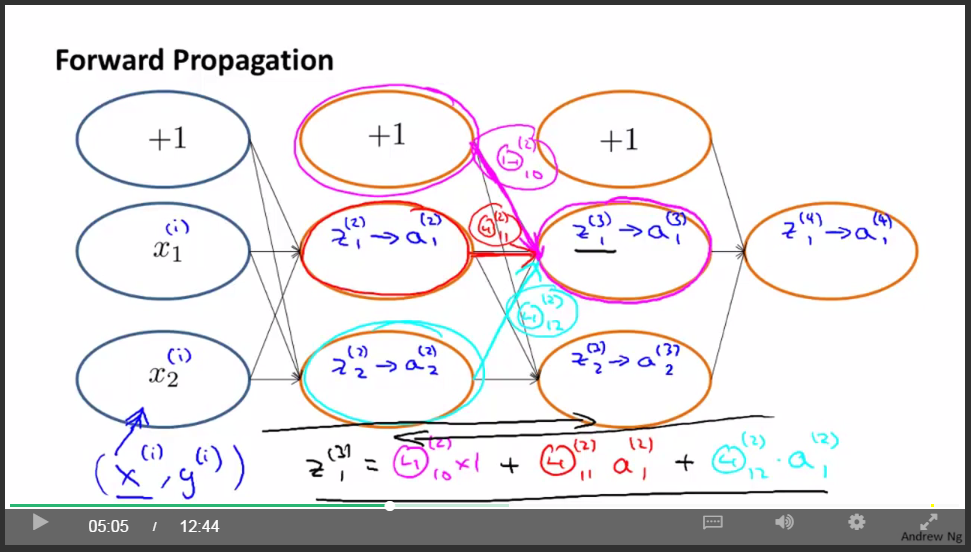
后向传播:

矩阵与向量之间的转换:
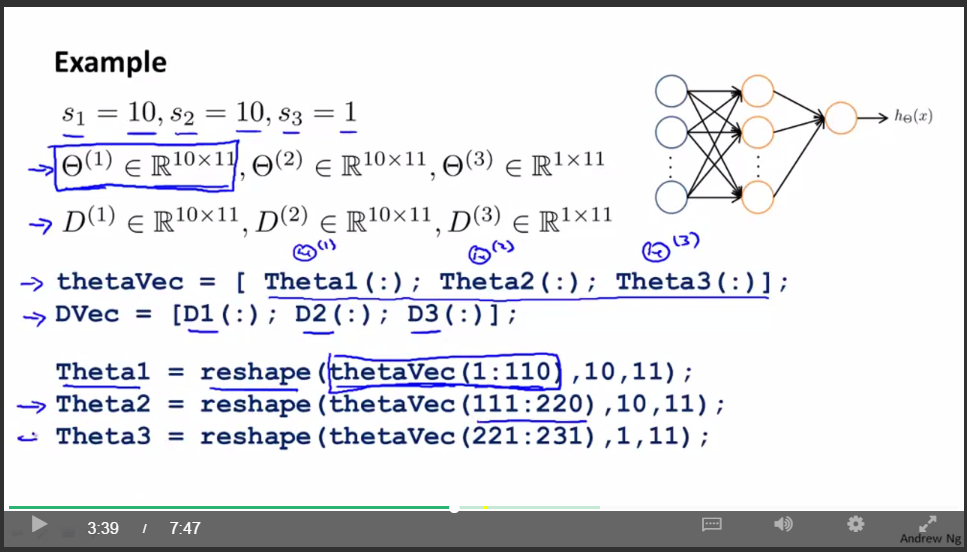

使用矩阵表达式的好处是:当你的参数以矩阵的形式存储时,你在进行正向传播和反向传播时,你会觉得更加方便。
使用向量表达式的好处是:如果你有像thetaVec或者DVec这样的矩阵,当你使用一些高级的优化算法时,这些算法通常要求你所有的参数都要展开成一个长向量的形式。
梯度检查(目的:检查后向传播算法结果跟梯度的数值计算方法结果是不是差不多):

随机初始化:
采用零初始化的问题:

随机初始化(目的:打破对称性):

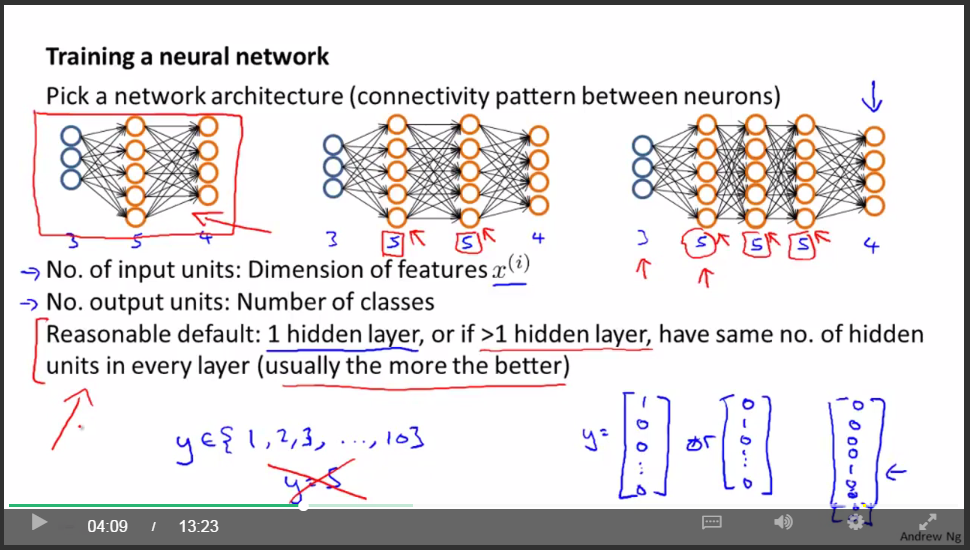
关于神经网络的总结
- 首先选取神经网络模型的结构
- 神经网络训练过程(共6步)
随机初始化权值时,通常设为很小的值,接近于零


第六周:
Advice for Applying Machine Learning
Machine Learning System Design
问题引入:

上面的这几种方法都可以试一试。但是,我们凭感觉试一试之后,有可能是一条不归路。有没有方法能够帮助我们选择呢?
解决方法(”诊断法”):

评估机器学习算法的性能:
用70%作为训练,用30%作为测试,计算测试样本的误差。(注意要shuffle)
另一种更好的评估方法:
用60%作为训练集,用20%作为交叉验证集,用20%作为测试集。
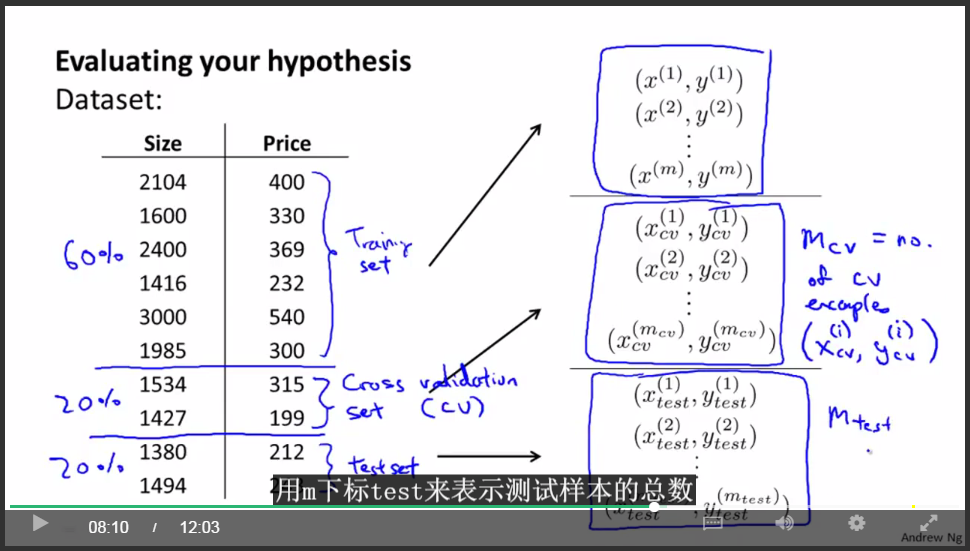
定义误差:

交叉验证集与测试集:

error:
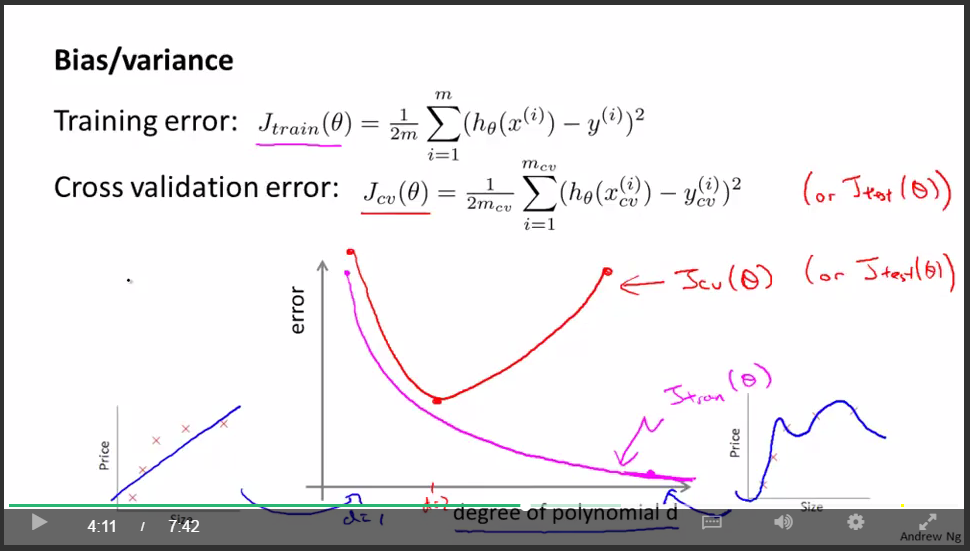
判断underfit or overfit:
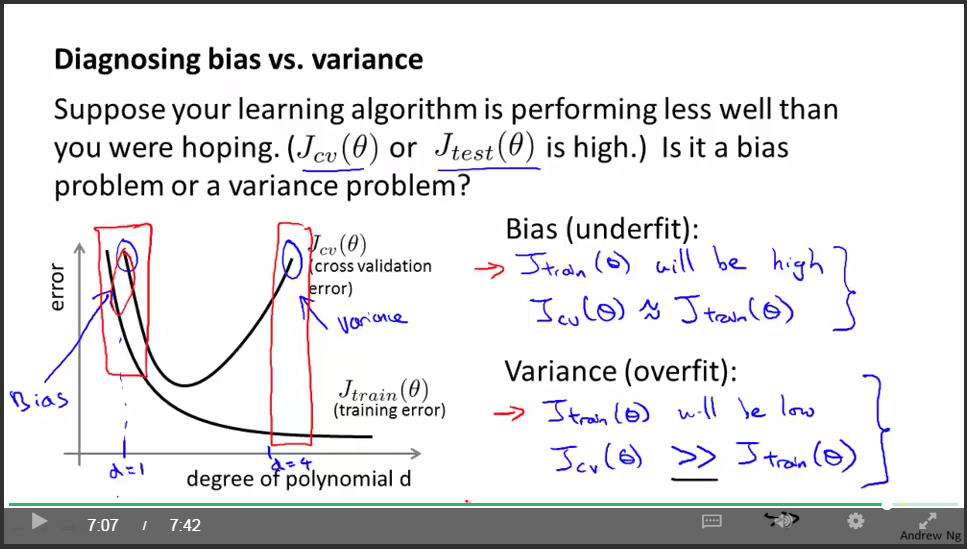
选择theta:


学习曲线:
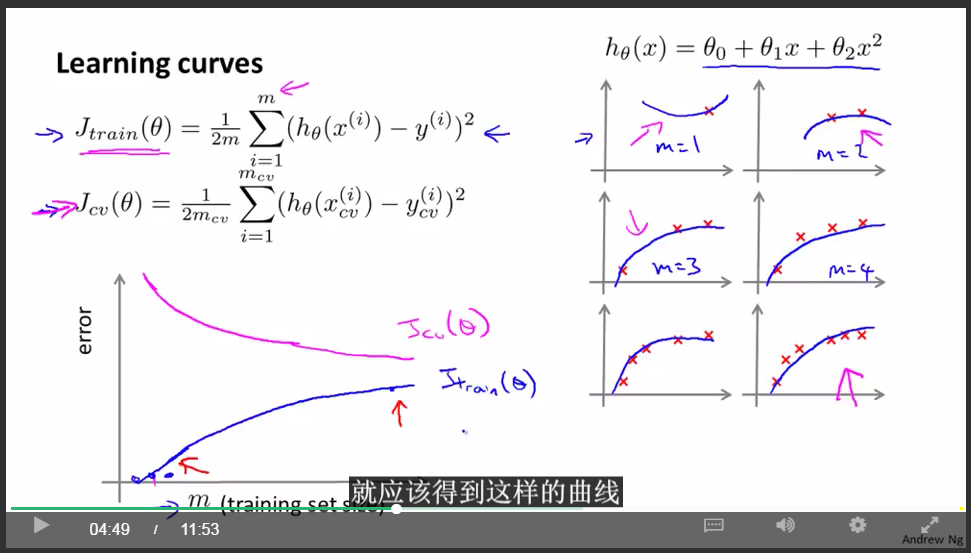
交叉验证集误差是对完全陌生的交叉验证集数据进行预测得到的误差。那么我们知道 当训练集很小的时候,泛化程度不会很好,意思是不能很好地适应新样本,因此这个假设,就不是一个理想的假设。只有当我使用一个更大的训练集时,我才有可能得到一个能够更好拟合数据的可能的假设。因此,你的验证集误差和测试集误差都会随着训练集样本容量m的增加而减小。因为你使用的数据越多,你越能获得更好地泛化表现或者说对新样本的适应能力更强。
underfit(high bias):
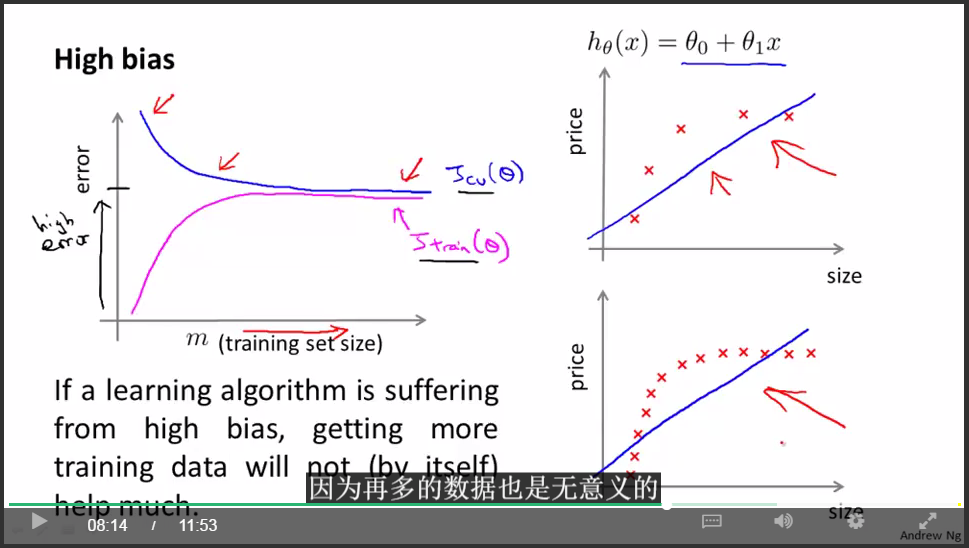
重要结论:
如果学习算法处于underfit状态,那么增加更多的训练数据是没用的。
overfit(high variance):
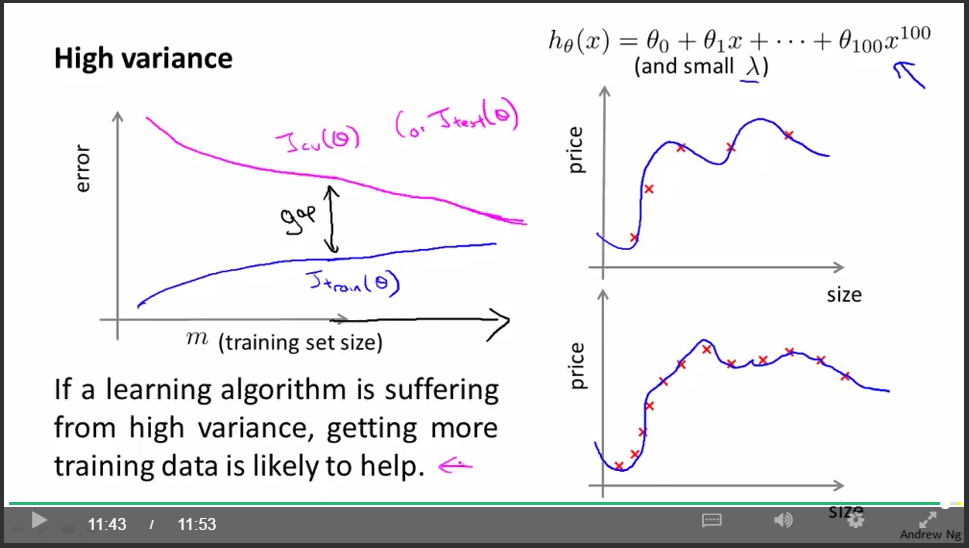
重要结论:
如果学习算法处于overfit状态,那么增加更多的训练数据是有用的。
到现在,我们能够对引入的问题进行回答了。
总结:

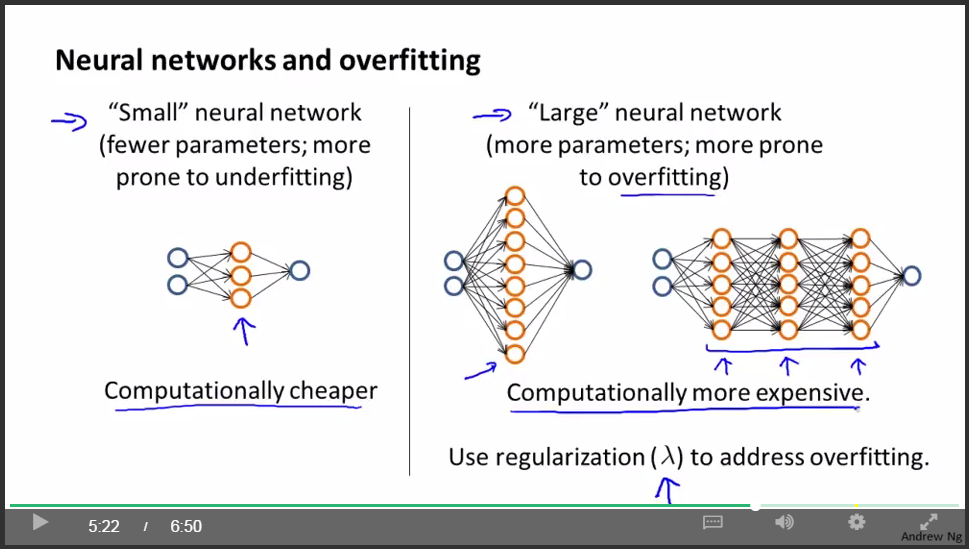
通常来说,正如我在前面的视频中讲过的,默认的情况是,使用一个隐藏层。但是如果你确实想要选择多个隐藏层,你也可以试试把数据分割为训练集,验证集和测试集,然后使用交叉验证的方法比较一个隐藏层的神经网络。然后试试两个,三个隐藏层,以此类推。然后看看哪个神经网络在交叉验证集上表现得最理想。也就是说,你得到了三个神经网络模型,分别有一个,两个,三个隐藏层 然后你对每一个模型都用交叉验证集数据进行测试,算出三种情况下的交叉验证集误差Jcv。然后选出你认为最好的神经网络结构。
机器学习系统设计:
举例:垃圾邮件分类

首先可以”头脑风暴”一下

但是要从中选取比较好的一个方法就需要一个系统性的方法“误差分析”了。
系统设计的通用步骤:

大致步骤:
1.快速实现,然后交叉检验
2.画出学习曲线,看接下来哪些做法是有用的
3.误差分析
误差分析:


偏斜类:
癌症分类样本中,真正得癌症的人的样本非常非常少,大概只有0.5%,非癌症类远大于癌症类。那么这时癌症类就为偏斜类。
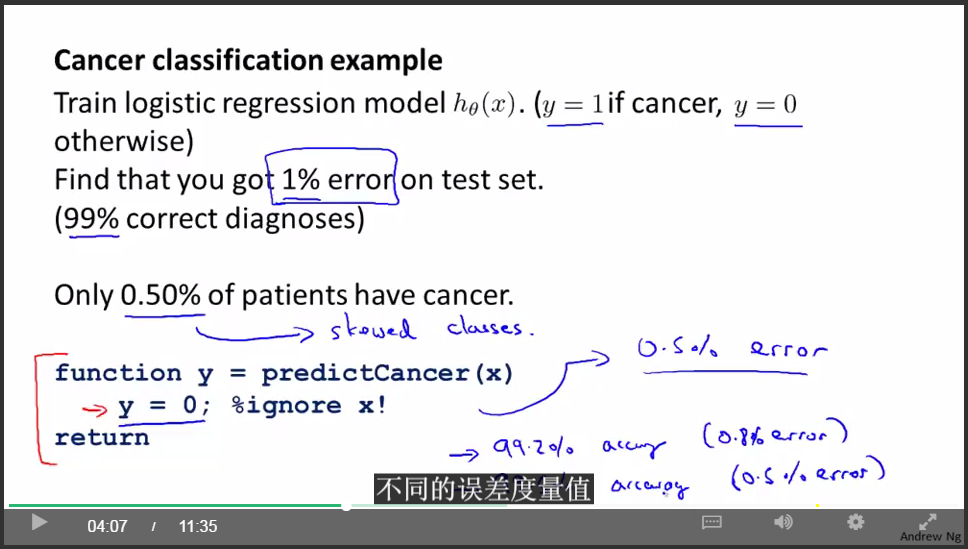
我们不能简单地用分类精确度来衡量分类的好坏。
因为如果我们简单粗暴地忽略输入,直接输出”肺癌症”类,那么我们的分类精确度是99.5%,看起来很高,但是这个策略是完全错误的啊!
引入查准率和召回率:

对于大多数回归模型,得权衡查准率和召回率:
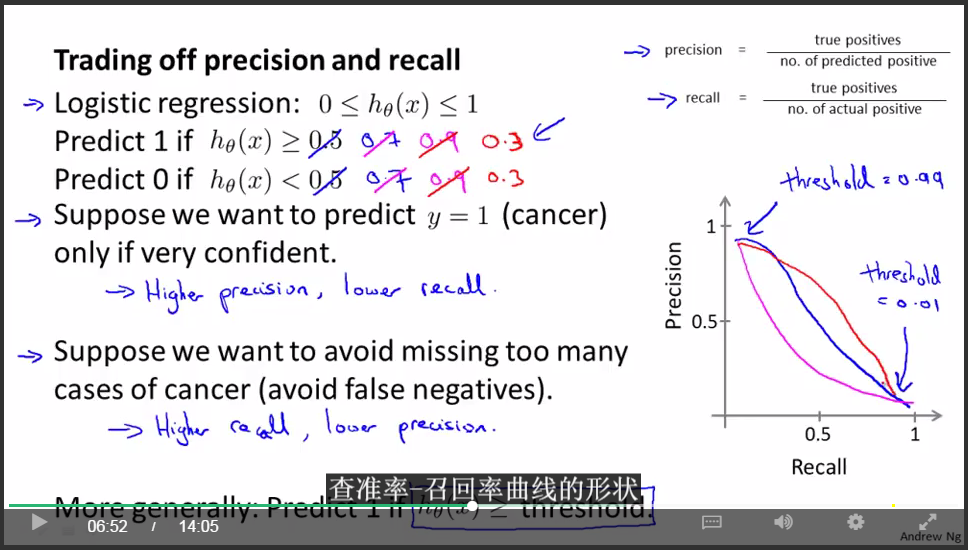
这产生了另一个有趣的问题,有没有办法自动选取临界值?
F值:
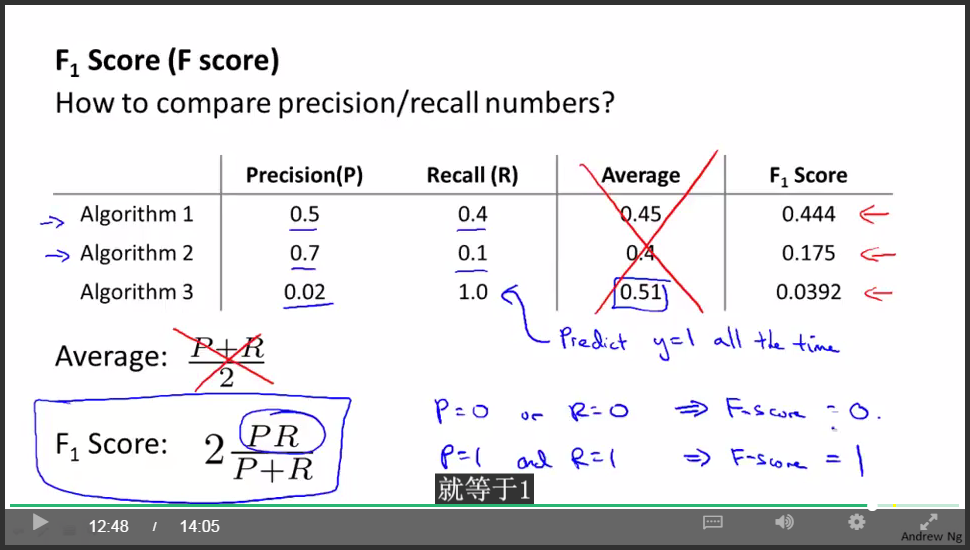
通过最大化F值来选择临界值!
关于机器学习的数据:

多少特征才能够预测呢?


什么时候大数据量不起作用:

总结:
一个高性能的学习算法,我觉得关键的测试,我常常问自己,首先 一个人类专家看到了特征值x能很有信心的预测出 y值吗?因为这可以证明y可以根据特征值x被准确地预测出来(包含足够信息)。其次,我们实际上能得到一组庞大的训练集并且在这个训练集中训练一个有很多参数的学习算法吗?如果你能做到这两者,满足这两个条件,那么你会得到一个性能很好的学习算法。
第七周:
Support Vector Machines
支持向量机:
先来看看逻辑回归的思想:

从逻辑回归的代价函数来推导出支持向量机:

对于逻辑回归,目标函数应该由两部分组成,一部分为训练样本的代价,另一部分为正则化项。
将代价函数前面的常数去掉并不影响取得最小值时的theta值(去掉m),所以SVM的代价函数变为:


人们通常将SVM成为大间距分类器。
下图从SVM目标函数的性质阐述了SVM比通常分类器要严格一些这一特点。

并且还可以通过设置参数C来改变些什么。下面假设C很大:

SVM努力用最大间距将正负样本分开(如下面黑色分界线所示):

因为SVM是基于最大间距分隔的,因此如果C设置很大,那么下图中加入一个异常点,将使原来的黑色分界线变为粉色分界线:

SVM背后的数学知识:
关于内积:


与分界线相交的是theta线:
下图左边将使theta的值变大,而右边使theta值变小,因为右边的投影比较大,就可以使theta的值很小。这就是我们想要的,所以SVM会产生最大间距分隔,通过设置theta0是否为0来表明分界线是否通过原点。

为了构造复杂的非线性分类器,我们引入kernel:
思路一:回顾以前,如果想构造非线性分类器,我们可以选取高阶项的特征向量作为输入,如下:

但问题是,我们有没有比高阶项方法更好的方法呢?因为在高阶项方法中,我们并不清楚哪些项是否是我们需要的,这就带来了巨大的运算量。
有没有更好的选择f1,f2,f3,…的方法呢?通过选择合适的kernel函数?l1,l2,l3是我们随便选取的点。

kernel函数有很多种啦,上述用的是高斯核函数。
kernel和相似度:

从这里,我们可以总结机器学习中关于数值转换的惯用套路,加exp函数,它能够使0映射为1,使负无穷映射为0!
图解举例kernel,以及参数&对其的影响:

再举例,离l1,l2较近的点将被认为是positive,远离的被认为是negative。

在SVM中使用它们,我们通过标记点和相似度函数来定义新的特征向量,从而训练复杂的非线性分类器。
我们还需要解决的问题是:1.怎样正确高效的选择这些点(landmarks),2.其他的相似度方程是怎样的(上面例子中的核函数为高斯核函数嘛)
choose the landmarks:
最简单的就是如下的选取:

下图描述了SVM的细节,注意在具体实施时,第二部分会有一些改变,略微改变了优化目标,主要原因是为了提高运算效率。

为什么我们不将核函数的思想运用到其他的算法中呢?比如逻辑回归上。
答案是:确实可以将核函数这种想法用于定义特征向量,将标记点之类的技术用于逻辑回归算法上,但是用于SVM的计算技巧,不能较好地推广到其他算法上,诸如逻辑回归。还有一些高级的优化技巧,是专门为使用核函数的SVM开发的。总而言之,核函数思想可以用在其他算法上,但效果可能不好。
关于SVM中不同参数带来的结果:

练习:

using an SVM:
SVM算法是一个特定的优化问题,不建议自己写来求解参数theta。那么我们需要自己做哪些事情呢?

上图给出了两种核函数并给出了适用的情况。
当你使用高斯核函数时:

如上图所示,请注意做好归一化!
为了能够快速得到theta,很多优化技巧只对基于下列定理的核函数起作用,因此自定义核函数的时候需要满足下列默赛尔定理:

不过现实中,还是高斯和线性核函数用的比较多。
练习:

更加重视交叉验证!
用SVM怎样处理多分类的问题,1.可以用软件自带,2.可以用one VS all的思想,前面在将逻辑回归的时候已经讲过了。

逻辑回归与SVM的比较:

SVM的优化问题是一种凸优化问题,所以SVM算法总是会找到全局最优值或者接近它的值,而不会陷入局部最优。
总结
当遇到机器学习问题时,有时确实不清楚该使用何种算法,虽然算法很重要,但更重要的是,你有多少数据,你有多熟练,是否擅长做误差分析和调试学习算法,想出如何设计新的特征变量,通常这方面的知识更加重要!
第八周:
Unsupervised Learning
无监督学习:
在无监督学习中,我们面对的是一组无标记的训练数据,数据之间,不具有任何相关联的标记。在该学习中,我们将这种未标记的数据送入特定的算法,然后我们要求算法替我们分析出数据的结构。比如聚类:

K-means算法是比较常用的聚类算法。
K-means算法是一个迭代算法,它主要做两件事情:1.簇分配,2.移动聚类中心。
K-means算法介绍:


如果存在一个没有点分配给它的聚类中心,怎么办?通常做法是直接移除那个聚类中心。
举例:如何设计S,M,L衣服型号

关于K-means的目标函数:

从目标函数优化的角度来看K-means算法:

这个代价函数J也被称作失真函数。
接下来,我们将讨论如何随机初始化,进而讨论如果避免局部最优。被推荐的初始化方法:

但可能陷入局部最优,如下:

为了避免局部最优,使用下列方法:

该算法从100个不同的初始化中选出最好的一个,在K=2-10时效果很明显,如果K很大,效果不是很明显。
如何选择合适的聚类类别个数K?可以看看肘部法则:

如果如左图,那么运用肘部法则取K=3,但大多数情况如右图,所以该法则的应用场景有限。
选择K的值还有一个方法:
通常聚类的应用场景是为了某些后面的用途,进而进行聚类,如果下游的用途能给你一个评价指标,那么更好的方法是,看不同的聚类数量能为后面下游的目标提供多好的结果。
维数约减 (dimensionality reduction) :
主要用途:
1.数据压缩
2.数据可视化
目前这方面最流行的方法是PCA:

最小化投影误差的思想!
PCA试图寻找到一个低维平面,对数据进行投影,以便最小化投影误差的平方,最小化每个点与投影后的对应点之间的距离的平方值。
PCA算法实现:
首先需要在PCA之前进行数据预处理:

先计算出协方差矩阵Sigma,再求奇异值分解,取前K列。


之前讲过PCA可以用做数据压缩,那么一个应用场景就是还原压缩后的数据,即解压缩。


















 586
586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









