







防止新手错误的神级代码
#define ture true
#define flase false
#difine viod void
#define mian main
#define ; ;
以后有新手问题就把这几行代码给他就好啦。
不用额外空间交换两个变量
a = 5
b = 8
#计算a和b两个点到原点的距离之和,并且赋值给a
a = a+b
#使用距离之和减去b到原点的距离
#a-b 其实就是a的原值(a到原点的距离),现在赋值给了b
b = a-b
#再使用距离之和减去b (a到原点的距离)
#得到的是b的原值(b到原点的距离),现在赋值给了a
a = a-b
八皇后问题神操作
是一个以国际象棋为背景的问题:如何能够在 8×8 的国际象棋棋盘上放置八个皇后,使得任何一个皇后都无法直接吃掉其他的皇后?为了达到此目的,任两个皇后都不能处于同一条横行、纵行或斜线上。八皇后问题可以推广为更一般的n皇后摆放问题:这时棋盘的大小变为n1×n1,而皇后个数也变成n2。而且仅当 n2 ≥ 1 或 n1 ≥ 4 时问题有解。
皇后问题是非常著名的问题,作为一个棋盘类问题,毫无疑问,用暴力搜索的方法来做是一定可以得到正确答案的,但在有限的运行时间内,我们很难写出速度可以忍受的搜索,部分棋盘问题的最优解不是搜索,而是动态规划,某些棋盘问题也很适合作为状态压缩思想的解释例题。
进一步说,皇后问题可以用人工智能相关算法和遗传算法求解,可以用多线程技术缩短运行时间。本文不做讨论。
(本文不展开讲状态压缩,以后再说)
一般思路:
N*N的二维数组,在每一个位置进行尝试,在当前位置上判断是否满足放置皇后的条件(这一点的行、列、对角线上,没有皇后)。
优化1:
既然知道多个皇后不能在同一行,我们何必要在同一行的不同位置放多个来尝试呢?
我们生成一维数组record,record[i]表示第i行的皇后放在了第几列。对于每一行,确定当前record值即可,因为每行只能且必须放一个皇后,放了一个就无需继续尝试。那么对于当前的record[i],查看record[0...i-1]的值,是否有j = record[k](同列)、|record[k] - j| = | k-i |(同一斜线)的情况。由于我们的策略,无需检查行(每行只放一个)。
public class NQueens {
public static int num1(int n) {
if (n < 1) {
return 0;
}
int[] record = new int[n];
return process1(0, record, n);
}
public static int process1(int i, int[] record, int n) {
if (i == n) {
return 1;
}
int res = 0;
for (int j = 0; j < n; j++) {
if (isValid(record, i, j)) {
record[i] = j;
res += process1(i + 1, record, n);
}
}//对于当前行,依次尝试每列
return res;
}
//判断当前位置是否可以放置
public static boolean isValid(int[] record, int i, int j) {
for (int k = 0; k < i; k++) {
if (j == record[k] || Math.abs(record[k] - j) == Math.abs(i - k)) {
return false;
}
}
return true;
}
public static void main(String[] args) {
int n = 8;
System.out.println(num1(n));
}
}
位运算优化2:
分析:棋子对后续过程的影响范围:本行、本列、左右斜线。
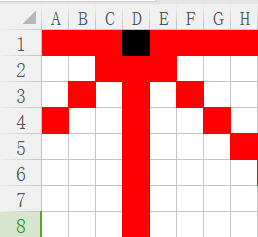
黑色棋子影响区域为红色
1)本行影响不提,根据优化一已经避免
2)本列影响,一直影响D列,直到第一行在D放棋子的所有情况结束。
3)左斜线:每向下一行,实际上对当前行的影响区域就向左移动
比如:
尝试第二行时,黑色棋子影响的是我们的第三列;
尝试第三行时,黑色棋子影响的是我们的第二列;
尝试第四行时,黑色棋子影响的是我们的第一列;
尝试第五行及以后几行,黑色棋子对我们并无影响。
4)右斜线则相反:
随着行序号增加,影响的列序号也增加,直到影响的列序号大于8就不再影响。
我们对于之前棋子影响的区域,可以用二进制数字来表示,比如:
每一位,用01代表是否影响。
比如上图,对于第一行,就是00010000
尝试第二行时,数字变为00100000
第三行:01000000
第四行:10000000
对于右斜线的数字,同理:
第一行00010000,之后向右移:00001000,00000100,00000010,00000001,直到全0不影响。
同理,我们对于多行数据,也同样可以记录了
比如在第一行我们放在了第四列:

第二行放在了G列,这时左斜线记录为00100000(第一个棋子的影响)+00000010(当前棋子的影响)=00100010。
到第三行数字继续左移:01000100,然后继续加上我们的选择,如此反复。
这样,我们对于当前位置的判断,其实可以通过左斜线变量、右斜线变量、列变量,按位或运算求出(每一位中,三个数有一个是1就不能再放)。
具体看代码:
注:怎么排版就炸了呢。。。贴一张图吧
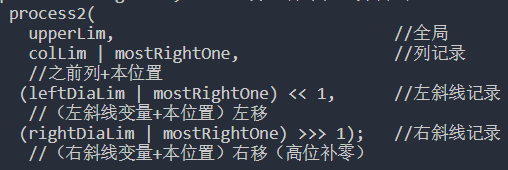
public class NQueens {
public static int num2(int n) {
// 因为本方法中位运算的载体是int型变量,所以该方法只能算1~32皇后问题
// 如果想计算更多的皇后问题,需使用包含更多位的变量
if (n < 1 || n > 32) {
return 0;
}
int upperLim = n == 32 ? -1 : (1 << n) - 1;
//upperLim的作用为棋盘大小,比如8皇后为00000000 00000000 00000000 11111111
//32皇后为11111111 11111111 11111111 11111111
return process2(upperLim, 0, 0, 0);
}
public static int process2(int upperLim, int colLim, int leftDiaLim,
int rightDiaLim) {
if (colLim == upperLim) {
return 1;
}
int pos = 0; //pos:所有的合法位置
int mostRightOne = 0; //所有合法位置的最右位置
//所有记录按位或之后取反,并与全1按位与,得出所有合法位置
pos = upperLim & (~(colLim | leftDiaLim | rightDiaLim));
int res = 0;//计数
while (pos != 0) {
mostRightOne = pos & (~pos + 1);//取最右的合法位置
pos = pos - mostRightOne; //去掉本位置并尝试
res += process2(
upperLim, //全局
colLim | mostRightOne, //列记录
//之前列+本位置
(leftDiaLim | mostRightOne) << 1, //左斜线记录
//(左斜线变量+本位置)左移
(rightDiaLim | mostRightOne) >>> 1); //右斜线记录
//(右斜线变量+本位置)右移(高位补零)
}
return res;
}
public static void main(String[] args) {
int n = 8;
System.out.println(num2(n));
}
}
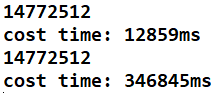
完整测试代码:
32皇后:结果/时间
暴力搜:时间就太长了,懒得测。。。
public class NQueens {
public static int num1(int n) {
if (n < 1) {
return 0;
}
int[] record = new int[n];
return process1(0, record, n);
}
public static int process1(int i, int[] record, int n) {
if (i == n) {
return 1;
}
int res = 0;
for (int j = 0; j < n; j++) {
if (isValid(record, i, j)) {
record[i] = j;
res += process1(i + 1, record, n);
}
}
return res;
}
public static boolean isValid(int[] record, int i, int j) {
for (int k = 0; k < i; k++) {
if (j == record[k] || Math.abs(record[k] - j) == Math.abs(i - k)) {
return false;
}
}
return true;
}
public static int num2(int n) {
if (n < 1 || n > 32) {
return 0;
}
int upperLim = n == 32 ? -1 : (1 << n) - 1;
return process2(upperLim, 0, 0, 0);
}
public static int process2(int upperLim, int colLim, int leftDiaLim,
int rightDiaLim) {
if (colLim == upperLim) {
return 1;
}
int pos = 0;
int mostRightOne = 0;
pos = upperLim & (~(colLim | leftDiaLim | rightDiaLim));
int res = 0;
while (pos != 0) {
mostRightOne = pos & (~pos + 1);
pos = pos - mostRightOne;
res += process2(upperLim, colLim | mostRightOne,
(leftDiaLim | mostRightOne) << 1,
(rightDiaLim | mostRightOne) >>> 1);
}
return res;
}
public static void main(String[] args) {
int n = 32;
long start = System.currentTimeMillis();
System.out.println(num2(n));
long end = System.currentTimeMillis();
System.out.println("cost time: " + (end - start) + "ms");
start = System.currentTimeMillis();
System.out.println(num1(n));
end = System.currentTimeMillis();
System.out.println("cost time: " + (end - start) + "ms");
}
}
马拉车——字符串神级算法
Manacher's Algorithm 马拉车算法操作及原理
package advanced_001;
public class Code_Manacher {
public static char[] manacherString(String str) {
char[] charArr = str.toCharArray();
char[] res = new char[str.length() * 2 + 1];
int index = 0;
for (int i = 0; i != res.length; i++) {
res[i] = (i & 1) == 0 ? '#' : charArr[index++];
}
return res;
}
public static int maxLcpsLength(String str) {
if (str == null || str.length() == 0) {
return 0;
}
char[] charArr = manacherString(str);
int[] pArr = new int[charArr.length];
int C = -1;
int R = -1;
int max = Integer.MIN_VALUE;
for (int i = 0; i != charArr.length; i++) {
pArr[i] = R > i ? Math.min(pArr[2 * C - i], R - i) : 1;
while (i + pArr[i] < charArr.length && i - pArr[i] > -1) {
if (charArr[i + pArr[i]] == charArr[i - pArr[i]])
pArr[i]++;
else {
break;
}
}
if (i + pArr[i] > R) {
R = i + pArr[i];
C = i;
}
max = Math.max(max, pArr[i]);
}
return max - 1;
}
public static void main(String[] args) {
String str1 = "abc1234321ab";
System.out.println(maxLcpsLength(str1));
}
}
问题:查找一个字符串的最长回文子串
首先叙述什么是回文子串:回文:就是对称的字符串,或者说是正反一样的
小问题一:请问,子串和子序列一样么?请思考一下再往下看
当然,不一样。子序列可以不连续,子串必须连续。
举个例子,”123”的子串包括1,2,3,12,23,123(一个字符串本身是自己的最长子串),而它的子序列是任意选出元素组成,他的子序列有1,2,3,12,13,23,123,””,空其实也算,但是本文主要是想叙述回文,没意义。
小问题二:长度为n的字符串有多少个子串?多少个子序列?
子序列,每个元素都可以选或者不选,所以有2的n次方个子序列(包括空)
子串:以一位置开头,有n个子串,以二位置开头,有n-1个子串,以此类推,我们发现,这是一个等差数列,而等差序列求和,有n*(n+1)/2个子串(不包括空)。
(这里有一个思想需要注意,遇到等差数列求和,基本都是o(n^2)级别的)
一、分析枚举的效率
好,我们来分析一下暴力枚举的时间复杂度,上文已经提到过,一个字符串的所有子串,数量是o(n^2)级别,所以光是枚举出所有情况时间就是o(n^2),每一种情况,你要判断他是不是回文的话,还需要o(n),情况数和每种情况的时间,应该乘起来,也就是说,枚举时间要o(n^3),效率太低。
二、初步优化
思路:我们知道,回文全是对称的,每个回文串都会有自己的对称轴,而两边都对称。我们如果从对称轴开始, 向两边阔,如果总相等,就是回文,扩到两边不相等的时候,以这个对称轴向两边扩的最长回文串就找到了。
举例:1 2 1 2 1 2 1 1 1
我们用每一个元素作为对称轴,向两边扩
0位置,左边没东西,只有自己;
1位置,判断左边右边是否相等,1=1所以接着扩,然后左边没了,所以以1位置为对称轴的最长回文长度就是3;
2位置,左右都是2,相等,继续,左右都是1,继续,左边没了,所以最长为5
3位置,左右开始扩,1=1,2=2,1=1,左边没了,所以长度是7
如此把每个对称轴扩一遍,最长的就是答案,对么?
你要是点头了。。。自己扇自己两下。
还有偶回文呢,,比如1221,123321.这是什么情况呢?这个对称轴不是一个具体的数,因为人家是偶回文。
问题三:怎么用对称轴向两边扩的方法找到偶回文?(容易操作的)
我们可以在元素间加上一些符号,比如/1/2/1/2/1/2/1/1/1/,这样我们再以每个元素为对称轴扩就没问题了,每个你加进去的符号都是一个可能的偶数回文对称轴,此题可解。。。因为我们没有错过任何一个可能的对称轴,不管是奇数回文还是偶数回文。
那么请问,加进去的符号,有什么要求么?是不是必须在原字符中没出现过?请思考
其实不需要的,大家想一下,不管怎么扩,原来的永远和原来的比较,加进去的永远和加进去的比较。(不举例子说明了,自己思考一下)
好,分析一波时间效率吧,对称轴数量为o(n)级别,每个对称轴向两边能扩多少?最多也就o(n)级别,一共长度才n; 所以n*n是o(n^2) (最大能扩的位置其实也是两个等差数列,这么理解也是o(n^2),用到刚讲的知识)
小结:
这种方法把原来的暴力枚举o(n^3)变成了o(n^2),大家想一想为什么这样更快呢?
我在kmp一文中就提到过,我们写出暴力枚举方法后应想一想自己做出了哪些重复计算,错过了哪些信息,然后进行优化。
看我们的暴力方法,如果按一般的顺序枚举,012345,012判断完,接着判断0123,我是没想到可以利用前面信息的方法,因为对称轴不一样啊,右边加了一个元素,左边没加。所以刚开始,老是想找一种方法,左右都加一个元素,这样就可以对上一次的信息加以利用了。
暴力为什么效率低?永远是因为重复计算,举个例子:12121211,下标从0开始,判断1212121是否为回文串的时候,其实21212和121等串也就判断出来了,但是我们并没有记下结果,当枚举到21212或者121时,我们依旧是重新尝试了一遍。(假设主串长度为n,对称轴越在中间,长度越小的子串,被重复尝试的越多。中间那些点甚至重复了n次左右,本来一次搞定的事)
还是这个例子,我换一个角度叙述一下,比较直观,如果从3号开始向两边扩,121,21212,最后扩到1212121,时间复杂度o(n),用枚举的方法要多少时间?如果主串长度为n,枚举尝试的子串长度为,3,5,7....n,等差数列,大家读到这里应该都知道了,等差数列求和,o(n^2)。
三、Manacher原理
首先告诉大家,这个算法时间可以做到o(n),空间o(n).
好的,开始讲解这个神奇的算法。
首先明白两个概念:
最右回文边界R:挺好理解,就是目前发现的回文串能延伸到的最右端的位置(一个变量解决)
中心c:第一个取得最右回文边界的那个中心对称轴;举个例子:12121,二号元素可以扩到12121,三号元素 可以扩到121,右边界一样,我们的中心是二号元素,因为它第一个到达最右边界
当然,我们还需要一个数组p来记录每一个可能的对称轴最后扩到了哪里。
有了这么几个东西,我们就可以开始这个神奇的算法了。
为了容易理解,我分了四种情况,依次讲解:
假设遍历到位置i,如何操作呢

1)i>R:也就是说,i以及i右边,我们根本不知道是什么,因为从来没扩到那里。那没有任何优化,直接往右暴力 扩呗。
(下面我们做i关于c的对称点,i’)
2)i<R:,
三种情况:
i’的回文左边界在c回文左边界的里面
i’回文左边界在整体回文的外面
i’左边界和c左边界是一个元素
(怕你忘了概念,c是对称中心,c它当初扩到了R,R是目前扩到的最右的地方,现在咱们想以i为中心,看能扩到哪里。)
按原来o(n^2)的方法,直接向两边暴力扩。好的,魔性的优化来了。咱们为了好理解,分情况说。首先,大家应该知道的是,i’其实有人家自己的回文长度,我们用数组p记录了每个位置的情况,所以我们可以知道以i’为中心的回文串有多长。
2-1)i’的回文左边界在c回文的里面:看图

我用这两个括号括起来的就是这两个点向两边扩到的位置,也就是i和i’的回文串,为什么敢确定i回文只有这么长?和i’一样?我们看c,其实这个图整体是一个回文串啊。
串内完全对称(1是括号左边相邻的元素,2是右括号右边相邻的元素,34同理),
由此得出结论1:
由整体回文可知,点2=点3,点1=点4
当初i’为什么没有继续扩下去?因为点1!=点2。
由此得出结论2:点1!=点2
因为前面两个结论,所以3!=4,所以i也就到这里就扩不动了。而34中间肯定是回文,因为整体回文,和12中间对称。
2-2)i’回文左边界在整体回文的外面了:看图
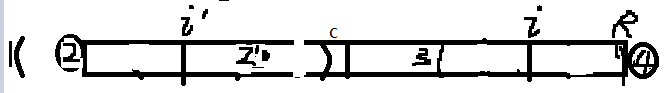
这时,我们也可以直接确定i能扩到哪里,请听分析:
当初c的大回文,扩到R为什么就停了?因为点2!=点4----------结论1;
2’为2关于i’的对称点,当初i’左右为什么能继续扩呢?说明点2=点2’---------结论2;
由c回文可知2’=3,由结论2可知点2=点2’,所以2=3;
但是由结论一可知,点2!=点4,所以推出3!=4,所以i扩到34为止了,34不等。
而34中间那一部分,因为c回文,和i’在内部的部分一样,是回文,所以34中间部分是回文。
2-3)最后一种当然是i’左边界和c左边界是一个元素

点1!=点2,点2=点3,就只能推出这些,只知道34中间肯定是回文,外边的呢?不知道啊,因为不知道3和4相不相等,所以我们得出结论:点3点4内肯定是,继续暴力扩。
原理及操作叙述完毕,不知道我讲没讲明白。。。
四、代码及复杂度分析
看代码大家是不是觉得不像o(n)?其实确实是的,来分析一波。。
首先,我们的i依次往下遍历,而R(最右边界)从来没有回退过吧?其实当我们的R到了最右边,就可以结束了。再不济i自己也能把R一个一个怼到最右
我们看情况一和四,R都是以此判断就向右一个,移动一次需要o(1)
我们看情况二和三,直接确定了p[i],根本不用扩,直接遍历下一个元素去了,每个元素o(1).
综上,由于i依次向右走,而R也没有回退过,最差也就是i和R都到了最右边,而让它们移动一次的代价都是o(1)的,所以总体o(n)
可能大家看代码依旧有点懵,其实就是code整合了一下,我们对于情况23,虽然知道了它肯定扩不动,但是我们还是给它一个起码是回文的范围,反正它扩一下就没扩动,不影响时间效率的。而情况四也一样,给它一个起码是回文,不用验证的区域,然后接着扩,四和二三的区别就是。二三我们已经心中有B树,它肯定扩不动了,而四确实需要接着尝试。
(要是写四种情况当然也可以。。但是我懒的写,太多了。便于理解分了四种情况解释,code整合后就是这样子)
我真的想象不到当初发明这个算法的人是怎么想到的,向他致敬。















 2780
2780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











