







在Docker上运行微服务
在过去的两年里,微服务架构已经成了非常热门的名词,它出现在很多论坛、视频、演讲中。作为一种更灵活、可靠、开放的架构,其应用实践也越来越多。近日,来自七牛云存储、DaoCloud、京东、ThoughtWorks的架构师们分别就微服务架构实践、容器技术带来的技术价值、微服务面临的挑战和解决目标等方面的经验做了交流分享。
微服务大探险
软件架构是在考虑业务、技术能力、团队、可维护性、安全性、可靠性及可持续性等多重因素下对软件内部进行的划分。通过划分,让软件内部不同的部分之间能够相互独立,又能够相互协作,同时给用户提供最终的价值。但什么是微服务架构呢?ThoughtWorks首席咨询师王磊通过一个互联网门户案例为大家解释了微服务架构的概念,以及它如何影响传统的软件架构设计。
一年前,该门户每签一个10万的合同所耗费的成本是3.5天。他们当时的CRM结构是典型的三层架构,整个应用程序由一个40万行的代码库组成,后端有一个主动的数据库。虽然使用三层架构的成本比较小,但随着代码和功能的增加,代码库不断膨胀,修改代码存在的风险很大,整个维护成本也变得越来越高。
每当开发人员提交代码后,所需的数据集成和构建需要50分钟,意味着每天8小时工作时间最多能有9次代码提交。但为了系统的稳定性,持续集成过程中要尽量避免提交代码,因此,整个团队的交付能力受到了限制。此外,从准备部署包到上线需要3天,3天后才能让用户真正用到部署包,才能实现价值。而如果增加新人,要开发新的环境,包括测试和产品环境,培养周期会很长。针对以上难题,必须制定如何在团队中对系统进行改造从而满足业务需求的策略。
- 将现有的系统保护起来,把所有开发新功能的优先级都降下来,只对系统做最紧急的修改,其他和部门进行协商,让团队保持新的精力和时间在重要的业务上。
- 功能剥离。通过定义新服务,在前端用一些代码的机制让用户逐渐访问新服务,可以达到从原有系统抽出小功能,让客户访问小功能。
- 数据解耦。对于庞大的系统,因为无法很快将所有系统换掉,所以为了保证系统仍然可用,要启用数据同步机制,让服务里的数据同步到原有数据库。
- 渐进替换。通过不断地运行以上策略,将原有系统的复杂功能抽离出来用新的方式来做。
目前,每签一个10万的合同所耗费的成本由3.5天变为1天,持续集成构建从50钟降低到18分钟,团队成员从10人降到7人,部署周期由3天降到2小时。
对于每个应用程序,可能有一组小的服务组成,每个服务运行在自己的进程中,服务与服务之间通过轻量级的机制进行交互。那么,如何使用微服务做系统改造呢?
- 为每个服务建立独立的环境,包括基础设施、持续集成环境、运维、监控、日志聚合、报警。
- 不断演进的微服务开发模板,发现问题及时修改,让模板更高效。
- 轻量级的通信协议。
- 消费者的契约测试,解决随着服务增多带来集成测试效率低的问题。
- 基础设施自管理,帮助管理自己需要的资源。
Container为微服务带来了什么?
七牛云CTO韩拓从服务端的架构和运维两个方面介绍了Container和微服务带来的价值。他认为Container是基于内核的空间。一个操作系统的内核主要管理资源,把服务器交给操作系统的内核,它把内存、CPU和硬盘等资源管理起来。Container进一步做隔离,这个隔离以进程为单位,让一个进程只能看到这个网卡收发的数据,但是看不到其他的网卡。
Container有以下几个名字空间。
- 网络的空间,它隔离了和网络相关的资源,如服务器上的网卡、IP地址、服务表等,之后这个进程在某个网络的空间内运行就看不到其他空间相关的网络资源。
- 文件系统,这个名字空间把这类资源也进行了隔离。一个进程运行时看到的根目录可能不是操作系统原生的根目录,看到的块设备也不是原来的块设备。
- PID,每运行一个进程都有一个PID,现在内核里的名字空间,PID的资源也被隔离起来。
Container对系统调用做了权限的控制。例如一个进程启动的时候限制它的权限,让很多系统调用做不了。Container的作用包括镜像管理和运行实例的管理,还有输入输出的管理。
那么,Container对服务端架构有什么影响呢?韩拓认为不管做什么架构,很重要的工作是模块化,去定义这个模块的边界,怎么工作、怎么测试及在生产环境如何部署。因此,从组件的角度看微服务化主要有以下三点。
- 组件划分的方式,Container以功能为单位来划分组件的边界。
- 组件物理边界,以前的边界有静态或动态的库,模块间的边界通常是函数调用。而微服务组件的物理边界是网络,这些组件都是独立的、可编译的进程(即每个单独的服务实例),这些服务实例之间通过网络来沟通。
- 组件的依赖方式,以前是在编译期考虑怎么才能把可执行程序编译出来,只要编译出来,就能肯定依赖关系肯定被解决了。当微服务化之后,依赖方式的处理被延后了,延后到运行的时候,因此错误被延后了,组件间的依赖方式变复杂了。Container中组件间的依赖可通过渲染文件和环境变量等实现。
关于Container对运维的影响,主要是告别DevOps。作为DevOps实践者,韩拓认为,DevOps的核心是试图寻找一个合理的开发和运维的边界。有很多方法论寻找这个边界,DevOps是其中一种,主要将运维平台化,做监控平台、日志平台等。
在持续集成方面,以前的任何一行代码做了更变都要把整个业务重新做一遍,需要很长时间。微服务化之后,每个模块独立编译、独立打包、独立测试,其边界也很明确,代码的变更影响的是一个组件和服务,单独进行编译和测试的动作会很快。
部署和升级方面变得简单,可以独立地部署和升级。
资源规划方面,按峰值申请资源会存在资源浪费。微服务化后,可以按模块去扩容。对资源的规划更灵活和合理。尤其再结合Container,因为Container以进程为单位,它对资源的使用是竞争的,不需要提前规划。
网络方面,Container一般通过端口映射的方式做网络。
监控方面,业务的运行状态对运维来讲更透明,小的服务可以单独监控,一些问题出来之后可以做报警。但监控变多了,需要监控系统更智能。
最后在高可用方面,传统的架构会做成透明的。现在,高可用由外部的框架完成,例如在做服务间依赖时就可以做高可用,不仅屏蔽了服务在哪里,服务了多少人,而且还可以把服务是死是活的细节屏蔽掉。
Micro Service,Continuous Delivery and Docker
DaoCloud联合创始人&研发副总裁郭峰认为容器技术解决了原来PaaS技术不能解决的问题。于是他给大家展示了微服务带来的挑战,即如果将一个应用微服务化,那么很容易导致一台机器上跑很多程序。因为服务纠缠在一起,所以微服务需要运用自包含。DaoCloud的容器技术是把最古老的几个技术融合在一起,用了一个很方便的脚本化的工具,让大家都可以用起来。它提供了标准化的镜像,不仅方便地用容器,而且可以方便地发布容器。
容器和虚拟机是什么关系呢?虚拟机有物理环境、有操作系统,但容器下面是server,上面跑应用程序和库,这样的架构使得容器的性能比虚拟机好很多。首先没有虚拟机的虚拟化过程,直接把跑内核的进程跑到OS上。别人想发一个微服务,可以利用在镜像上面加一层,即使有很多镜像,有时多个镜像会一起依赖,会省资源和容量。那么,为什么容器是轻量级的?因为它只有应用和应用的依赖所打成的包,如果应用做了一点点修改,不需要完全打一个,在原有的应用上打一个补丁,把修改记下来即可。

上图是Docker的流程图, Dockerfile这个镜像可以运行在本机。在上面运行容器,等容器开发好并且测试通过了再把这个容器push到镜像仓库上。任何一个人都可以从镜像仓库上下载,下载后,Docker运行一套命令让行为一致。重要的是,Docker官方维护了DockerHA,所以Docker允许以镜像的方式发布Container,发布的Container像未来的VM,这个VM很轻量,大家可以把它pull下来,不管用什么物理硬件资源,都可以让Docker运行起来,而且运行结果和其他没有差别。Docker是如何做到自包含的呢? Docker的自包含是它容器的本身包括了OS的版本,以及依赖的环境和客户,所有的都描述成Dockerfile。Docker可以帮助两类人——开发人员和运维人员,它跨越了开发和运维间的那道鸿沟。
仅仅自包含就做微服务是不够的,微服务要求把之前大系统的问题分解为很多简单的小问题,然后将每个简单的小问题用最合适的技术实现。但这导致现在有很多小应用,原来靠人工可以解决的事现在解决不了,比如做CI(持续集成)/CD(持续交付)。微服务化以后,会导致一个企业的应用CI很难做。
此外,他还向大家介绍了Docker的三件法宝。第一个是Docker Compose,如果应用不是单应用可以用同一方法描述应用和应用的依赖,然后上线。第二个是Volumes,可以共享文件。最后一个是环境变量,不管是微服务和微服务之间的依赖以及微服务运行时的依赖的环境变量也好,还是端口也好,都描述清楚,定义好后给运维人员。这是可复制的迭加过程,不仅把代码和运行做自包含变成一个镜像,而且镜像用运行的方式提供出来。运维人员不需要关心应用内部的逻辑,只需要关心模块的镜像以及如何将镜像运行起来,这样可以大大地减少运维成本。
Docker的应用与实践
来自京东的资深架构师季锡强分享了Docker的应用与实践。主要讲了Docker的系统整体架构及其技术实现、镜像存储部分、Container启动流程,还介绍了制作镜像命令的原理以及volume挂载的原理。
他为大家介绍了Docker的组件,Docker真正的实现主要是几个组件组成,第一层是镜像存储的模块,实现有很多种,比如device mapper、aufs以及btrfs。第二层是exec driver,主要是libcontainer及lxc。第三层是network driver,主要是主机以及网络命名空间,而Namespace支持ipc、mnt、pid、net、uts及user。组件CGroup主要做资源控制,涉及的方面有CPU、IO,IO可以不依赖于Namespace单独使用,和操作文件一样改一下值就可以。CGroup的限制主要是通过子系统来实现,相应的模块有IO、CPU等。而组件Device Mapper的实现有DM - thin provision。

上图是启动容器的流程。启动的命令请求首先会把设备mount到指定的挂载点上访问。启动go monitor会带着参数启动里面的命令,接下来会用Dockerinit做初始化,最终命令会进行系统调用,再exec执行。停止容器则比较粗暴,相当于Docker根据PID直接将容器中的进程杀掉,再做一些资源的释放,这样就完成了停止容器的流程。Docker启动的时候,如果Docker是意外死掉的(人为或者程序的破坏),那么之前的程序不会消失,这时候Docker会把所有的容器kill掉,会把之前容器创建的操作信息保存在Docker的目录下。Docker将所有的容器都kill掉后,资源会被释放,这个时候就会触发一个永久性的bug。因为当容器重启的时候,会检查mount count,这个初始化的值是0,而Docker死掉后重启则会发现mount count不为0,所以会导致mount失败,导致出错;这个时候我们想启动容器的话,关键的动作是把设备释放并重新挂载到mount下。因此,告诫大家,如果Docker异常死掉了,要及时清理资源。
关于制作镜像的原理,你可以建立一个镜像生成一个容器,这个镜像可以分到某一个文件目录下,可以做一些直接的操作。首先mount上去,镜像原来的版本也会mount上去,遍历所有的文件看两者之间的状态是否有变化,然后打包,产生diff。这时要创建新的容器,因为已经获得了diff,接下来要创建一个新的镜像。创建新的镜像之前要拿到Container的基本镜像,这时要把这个镜像mount,就可以看到所有的文件。最后的操作是解压一个文件到一个新的snapshot,就相当于有一个新的镜像了。
最后,他对Docker做了一些总结,Docker主要用到CGroup的一部分子系统;Docker启动和停止之间有一个大Bug需要及时关注;commit要打包、解压文件,机器磁盘很高的时候commit会相当耗时。
来源: http://www.infoq.com/cn/news/2015/06/qiniu-best531?utm_campaign=infoq_content&
什么是微服务
微服务应用的一个最大的优点是,它们往往比传统的应用程序更有效地利用计算资源。这是因为它们通过扩展组件来处理功能瓶颈问题。这样一来,开发人员只需要为额外的组件部署计算资源,而不需要部署一个完整的应用程序的全新迭代。最终的结果是有更多的资源可以提供给其它任务。• 一种软件架构模式
• 复杂应用解耦为小而众的服务
• 各服务精而专
• 服务间通信通过API完成

微服务应用程序的另一个好处是,它们更快且更容易更新。当开发者对一个传统的单体应用程序进行变更时,他们必须做详细的QA测试,以确保变更不会影响其他特性或功能。但有了微服务,开发者可以更新应用程序的单个组件,而不会影响其他的部分。测试微服务应用程序仍然是必需的,但它更容易识别和隔离问题,从而加快开发速度并支持DevOps和持续应用程序开发。
第三个好处是,微服务架构有助于新兴的云服务,如事件驱动计算。类似AWS Lambda这样的功能让开发人员能够编写代码处于休眠状态,直到应用程序事件触发。事件处理时才需要使用计算资源,而企业只需要为每次事件,而不是固定数目的计算实例支付。
扩展立方模型(Scale Cube)

Y轴 功能解耦 通过分解 不同模块扩展
X轴 水平副本 通过副本扩展
Z轴 数据分区 通过分解 相似内容扩展
Docker是什么
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app)。几乎没有性能开销,可以很容易地在机器和数据中心中运行。最重要的是,他们不依赖于任何语言、框架包括系统。

Docker包含两方面技术
-镜像技术
打破“代码即应用”的观念
从系统环境开始,自底至上打包应用


微服务和Docker
Dev
开发简单有效的模块
配置是一个运行时的限制
不再是异常复杂的应用
new WebServer().start(8080);
Ops
管理硬件设施
监控&反馈
不是应用的执行细节
结合扩展立方(Scale Cube)

Docker化实践
本质:进程隔离,资源管理
• App-Centric的体现
• Single-Process的真实含义

Docker化实践——进程隔离

Dockerfile、Docker镜像与Docker容器

容器内技术栈:
1.单进程理念
2.不存在传统的init进程(全局PID=1)
——dockerinit与init进程的区别
3.缺少基本的服务进程
——cron
——rsyslogd等
4.与内核进程通信能力薄弱(ipc命名空间隔离)
导致遗留系统Docker化存在压力。 重构?非重构下的最佳实践?
Docker化实践——日志管理
原理:stdout&stderr
传统模式:
-stdout&stderr
-磁盘日志文件
-日志服务器
日志持久化磁盘的弊端
-移植性
-部署复杂度
日志Docker层面管理
-json-file
-syslog(并非应用调用syslog)
-fluetd

以syslog为例 
Docker化实践——日志管理

Docker化实践——配置管理
传统方式:配置文件
• Docker容器的无状态
• 配置文件的状态性
• Docker容器依赖配置文件
• 额外的配置管理需求
• 非自动化
• 非标准化
• 沿用传统模式——配置文件
——使用挂载volume的方式
——配置文件与宿主机耦合
• 采用环境变量方式
——打包配置进入Docker镜像
——打包配置进入Docker容器
——完美支持编排工具compose
• 环境变量与配置文件共存
——修改Docker镜像执行入口
——使用环境变量替换配置文件
来源:http://www.cnblogs.com/wintersun/archive/2016/01/16/5136385.html
如果你正在寻找练手机会以便深入学习Docker,那么本文就是你最好的选择。在本文中,我将展示docker是如何工作的,以及应用Docker完成构建一个基本的微服务开发任务。
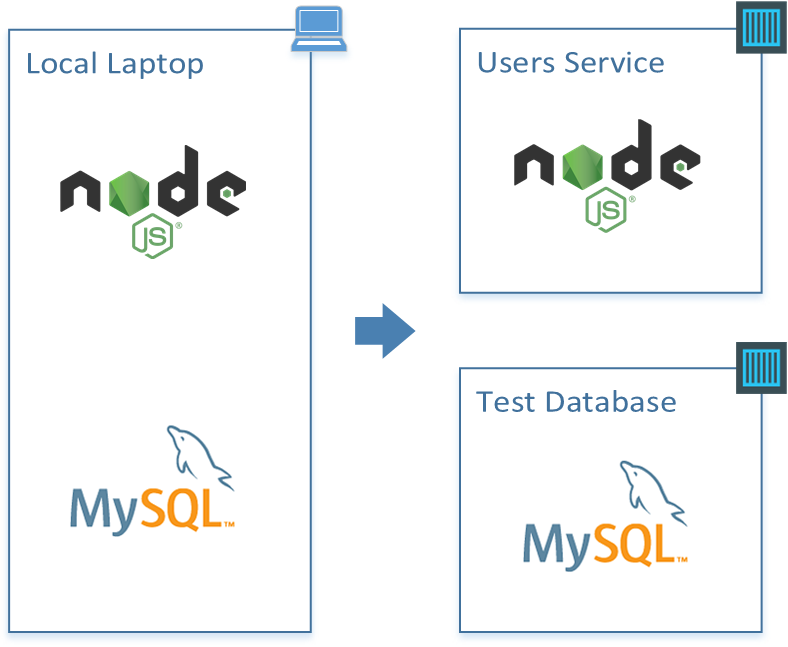
我们将使用一个简单的Node.js服务与一个MySQL后端为例,实现从本地运行的代码迁移到容器化运行的微服务和数据库。
什么是Docker?
它的核心就是:Docker是一个允许你创建镜像(这包含了很多步骤,就像在虚拟机的模板一样)并且让这个镜像的实例运行在容器中的软件。
Docker维护着一个巨大的镜像资源库,我们称之为Docker Hub,我们可以使用它作为我们自己镜像存储的出发点。可以按照Docker,选择任意我们希望使用的镜像,然后在一个容器中执行这个镜像的实例。
安装Docker
为了继续学习和使用本文章的以下内容,第一步你需要安装Docker。
以下是基于你的平台的安装指南docs.docker.com/engine/installation.
假如是在使用Mac或者Windows,那么你可以考虑使用虚拟机。在Mac OS X上用的是Parallels来运行Ubuntu以支持大多数的开发活动。这种方式对于在各种实验中拍摄快照,中断以及恢复时是非常方便的。
试验开始
输入以下命令:
docker run -it ubuntu 很快你就将会看到以下的命令提示符:
root@719059da250d:/# 下面再测试几条命令然后终结这个容器:
root@719059da250d:/# lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 14.04.4 LTS
Release: 14.04
Codename: trusty
root@719059da250d:/# exit 这看起来好像并没有什么,但是实际上背后发生了很多。你们看到的是Ubuntu的一个bash shell,它运行于在你的机器上隔离的容器中。在这里,你可以安装任何东西,运行任何软件,或者其他任何你想要做的。以下是上述动作的流程分解图(该图表来自于Docker文档库的“理解架构”,非常值得推荐)
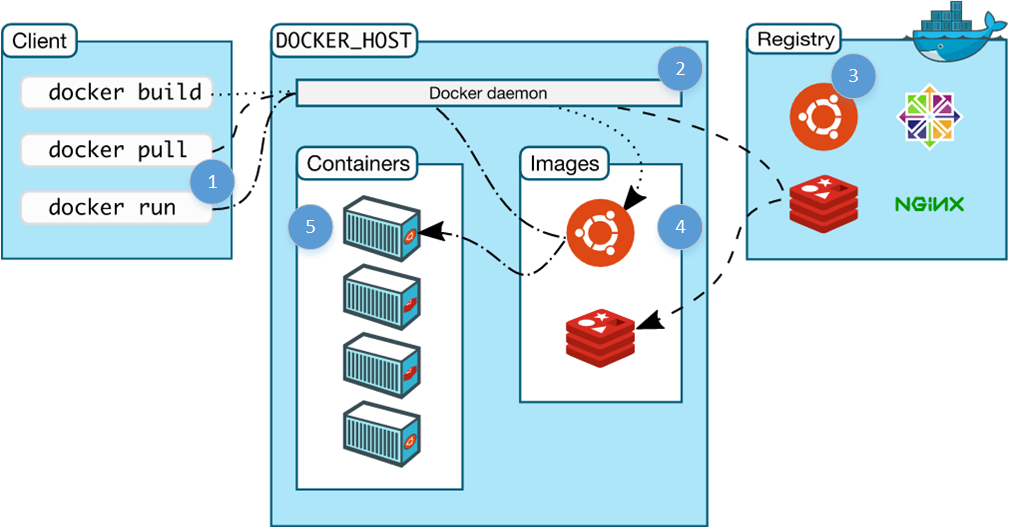
1.输入一条Docker命令:
odocker: 运行docker客户端
orun: 该命令启动一个新的容器
o-it: 是否启动交互式终端模式的可选项
oubuntu: 容器启动所基于的镜像名
2.在主机上运行的Docker的服务首先检查本地是否有所请求的镜像拷贝,没有的话则执行下一步。
3.Docker服务检查公共的版本库(Docker Hub)是否有名字为ubuntu 的镜像存在,找到然后执行下一步。
4.Docker服务下载镜像并存储于本地缓存中,以备下次使用。
5.Docker服务基于该镜像ubuntu 创建新的容器。
尝试更多命令如下:
docker run -it haskell
docker run -it java
docker run -it python 我们使用Haskell ,但是就像你所看到的那样,配置运行这个环境也是非常容易的。
这个范例描述了如何创建自己的镜像,并包含我们的服务程序、数据库以及其他一切所需的。我们可以在任何安装有Docker的机器上运行它们,这些镜像都会以同样的、可预测的方式执行。因此我们可以非常方便的构建软件以及编码和部署用于软件运行所需的环境。接下来让我们来看一个简单的微服务范例。
概述
以下将要建立一个微服务,它可以让我们通过使用使用node.js和mysql来管理电子邮件目录中的电话号码。
启程
为了开始本地开发,我们需要安装MySQL以及创建一个测试数据库… …
创建一个本地数据库并执行脚本是一个简单的开端,但也可能是一团混乱。很多不可控的事情会发生。它可能会正常工作,我们甚至可以执行一些脚本来检查我们的版本库,但是假如已经有其他开发人员在机器上安装了MySQL呢?并且假设他们所使用的数据库已经占用了我们想要使用的数据库名‘users’?
第一步:在Docker上创建测试数据库服务器
这是一个非常好的Docker用户案例。或许我们不会把生产数据库跑在Docker上,但是可以在任何时间为开发人员快速部署一个基于Docker容器的纯净MySQL数据库,保持我们干净的开发机器环境并且一切都是可控且可重复的。
执行以下命令:
docker run --name db -d -e MYSQL_ROOT_PASSWORD=123 -p 3306:3306 mysql:latest 该命令启动一个MySQL数据库实例,并且允许root用户以及123的密码通过3306端口访问它.
- docker run 这里我们告诉Docker引擎我们需要加载一个镜像(这个镜像名在命令最后:mysql:vlatest)。
- –name db 这里给容器命名db。
- -d (or –detach) 分离,即在后台运行的容器。
- -e MYSQL_ROOT_PASSWORD=123 (or –env) 环境变量-告诉Docker我们需要提供的环境变量,随后的这个变量就是MySQL镜像需要检查配置的root默认密码。
- -p 3306:3306 (或者 –publish 告诉Docker引擎我们需要映射容器内部的3306端口到外部的3306端口。
这个命令的返回值就是容器的id,它是容器的引用代码可以用来针对具体容器停止、重启、执行命令等等。接下来就让我们来看看哪些容器当前正在运行:
$ docker ps
CONTAINER ID IMAGE ... NAMES
36e68b966fd0 mysql:latest ... db 这里的关键信息就是容器ID,镜像以及容器名。下面让我们连接上这个镜像并且看看上面到底有什么:
$ docker exec -it db /bin/bash
root@36e68b966fd0:/# mysql -uroot -p123
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
+--------------------+
1 rows in set (0.01 sec)
mysql> exit
Bye
root@36e68b966fd0:/# exit 这里的实现也是相当的巧妙:
- docker exec -it db 这里告诉Docker,我们要在容器名为db(这里我们也可以使用容器id,或者是id头上的部分缩写)内执行一条命令。
- mysql -uroot -p123 这条是真正在容器内运行具体进程的命令,在本例中就是启动了mysql的客户端。
至此,我们已经可以创建数据库、表、用户以及其他一切所需。
测试数据库总结
上述文章中介绍了一些在容器中运行MySQL的Docker技巧,不过暂停一下,转移到服务上。现在,我们将要创建一个test-database 文件夹以及使用脚本来启动数据库,停止数据库和设置测试数据:
test-database\setup.sql
test-database\start.sh
test-database\stop.sh 启动命令非常简单:
#!/bin/sh
# Run the MySQL container, with a database named 'users' and credentials
# for a users-service user which can access it.
echo "Starting DB..."
docker run --name db -d \
-e MYSQL_ROOT_PASSWORD=123 \
-e MYSQL_DATABASE=users -e MYSQL_USER=users_service -e MYSQL_PASSWORD=123 \
-p 3306:3306 \
mysql:latest
# Wait for the database service to start up.
echo "Waiting for DB to start up..."
docker exec db mysqladmin --silent --wait=30 -uusers_service -p123 ping || exit 1
# Run the setup script.
echo "Setting up initial data..."
docker exec -i db mysql -uusers_service -p123 users < setup.sql 这个脚本在一个分离式的容器(即后台运行的容器)上运行数据库镜像,同时用户设置访问users 数据库,然后等待数据库服务器启动,最后执行setup.sql脚本设置初始数据。
setup.sql 的内容如下:
create table directory (user_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY, email TEXT, phone_number TEXT);
insert into directory (email, phone_number) values ('homer@thesimpsons.com', '+1 888 123 1111');
insert into directory (email, phone_number) values ('marge@thesimpsons.com', '+1 888 123 1112');
insert into directory (email, phone_number) values ('maggie@thesimpsons.com', '+1 888 123 1113');
insert into directory (email, phone_number) values ('lisa@thesimpsons.com', '+1 888 123 1114');
insert into directory (email, phone_number) values ('bart@thesimpsons.com', '+1 888 123 1115'); stop.sh 脚本将会停止容器并删除它(默认情况下容器并不会被Docker立即删除,从而它们可以在需要时被快速恢复,在本例中我们并不需要这个功能):
#!/bin/sh
# Stop the db and remove the container.
docker stop db && docker rm db 接下来将要让这些步骤更加平滑和简洁,具体可以查看在这个阶段的第一步的版本库分支代码。
第二步:创建一个Node.js的微服务
由于本文的主要关注点在于学习Docker,所以我将不会在Node.js如何实现微服务上花费太多笔墨,相反,我将重点关注Docker的领域和结论。
test-database/ # contains the code seen in Step 1
users-service/ # root of our node.js microservice
- package.json # dependencies, metadata
- index.js # main entrypoint of the app
- api/ # our apis and api tests
- config/ # config for the app
- repository/ # abstraction over our db
- server/ # server setup code首先来看repository。它是对于封装你的数据库访问类和抽象非常有用的方式,并且允许模拟它作为测试目的:
// repository.js
//
// Exposes a single function - 'connect', which returns
// a connected repository. Call 'disconnect' on this object when you're done.
'use strict';
var mysql = require('mysql');
// Class which holds an open connection to a repository
// and exposes some simple functions for accessing data.
class Repository {
constructor(connection) {
this.connection = connection;
}
getUsers() {
return new Promise((resolve, reject) => {
this.connection.query('SELECT email, phone_number FROM directory', (err, results) => {
if(err) {
return reject(new Error("An error occured getting the users: " + err));
}
resolve((results || []).map((user) => {
return {
email: user.email,
phone_number: user.phone_number
};
}));
});
});
}
getUserByEmail(email) {
return new Promise((resolve, reject) => {
// Fetch the customer.
this.connection.query('SELECT email, phone_number FROM directory WHERE email = ?', [email], (err, results) => {
if(err) {
return reject(new Error("An error occured getting the user: " + err));
}
if(results.length === 0) {
resolve(undefined);
} else {
resolve({
email: results[0].email,
phone_number: results[0].phone_number
});
}
});
});
}
disconnect() {
this.connection.end();
}
}
// One and only exported function, returns a connected repo.
module.exports.connect = (connectionSettings) => {
return new Promise((resolve, reject) => {
if(!connectionSettings.host) throw new Error("A host must be specified.");
if(!connectionSettings.user) throw new Error("A user must be specified.");
if(!connectionSettings.password) throw new Error("A password must be specified.");
if(!connectionSettings.port) throw new Error("A port must be specified.");
resolve(new Repository(mysql.createConnection(connectionSettings)));
});
};这里或许有很多种更好的方式来实现,但是基本上我们可以用以下方式来创建Repository 对象:
repository.connect({
host: "127.0.0.1",
database: "users",
user: "users_service",
password: "123",
port: 3306
}).then((repo) => {
repo.getUsers().then(users) => {
console.log(users);
});
repo.getUserByEmail('homer@thesimpsons.com').then((user) => {
console.log(user);
})
// ...when you are done...
repo.disconnect();
});在repository/repository.spec.js文件中也包含了一系列的单元测试。现在我们已经得到了一个仓库,可以在这个仓库中创建一个服务器。代码见如下文件
server/server.js:
// server.js
var express = require('express');
var morgan = require('morgan');
module.exports.start = (options) => {
return new Promise((resolve, reject) => {
// Make sure we have a repository and port provided.
if(!options.repository) throw new Error("A server must be started with a connected repository.");
if(!options.port) throw new Error("A server must be started with a port.");
// Create the app, add some logging.
var app = express();
app.use(morgan('dev'));
// Add the APIs to the app.
require('../api/users')(app, options);
// Start the app, creating a running server which we return.
var server = app.listen(options.port, () => {
resolve(server);
});
});
};这个模块暴露了一个start 函数接口,我们可以以如下方式使用它:
var server = require('./server/server);
server.start({port: 8080, repo: repository}).then((svr) => {
// we've got a running http server :)
});请注意这里这里使用的 server.js 是在 api/users/js 下,具体如下:
// users.js
//
// Defines the users api. Add to a server by calling:
// require('./users')
'use strict';
// Only export - adds the API to the app with the given options.
module.exports = (app, options) => {
app.get('/users', (req, res, next) => {
options.repository.getUsers().then((users) => {
res.status(200).send(users.map((user) => { return {
email: user.email,
phoneNumber: user.phone_number
};
}));
})
.catch(next);
});
app.get('/search', (req, res) => {
// Get the email.
var email = req.query.email;
if (!email) {
throw new Error("When searching for a user, the email must be specified, e.g: '/search?email=homer@thesimpsons.com'.");
}
// Get the user from the repo.
options.repository.getUserByEmail(email).then((user) => {
if(!user) {
res.status(404).send('User not found.');
} else {
res.status(200).send({
email: user.email,
phoneNumber: user.phone_number
});
}
})
.catch(next);
});
};上述这些文件都有相应的单元测试覆盖源代码。需要做一些配置,而不是使用一个定制化的库,一个简单的文件即可实现这个技巧,如- config/config.js:
// config.js
//
// Simple application configuration. Extend as needed.
module.exports = {
port: process.env.PORT || 8123,
db: {
host: process.env.DATABASE_HOST || '127.0.0.1',
database: 'users',
user: 'users_service',
password: '123',
port: 3306
}
};下面代码的require 可以按需配置。当前绝大多数的配置都是硬编码的,但是你可以port 为例它可以非常方便的增加环境变量作为可选模式的。最终,把这一切字符串组合在一起写在 index.js 文件中:
// index.js
//
// Entrypoint to the application. Opens a repository to the MySQL
// server and starts the server.
var server = require('./server/server');
var repository = require('./repository/repository');
var config = require('./config/config');
// Lots of verbose logging when we're starting up...
console.log("--- Customer Service---");
console.log("Connecting to customer repository...");
// Log unhandled exceptions.
process.on('uncaughtException', function(err) {
console.error('Unhandled Exception', err);
});
process.on('unhandledRejection', function(err, promise){
console.error('Unhandled Rejection', err);
});
repository.connect({
host: config.db.host,
database: config.db.database,
user: config.db.user,
password: config.db.password,
port: config.db.port
}).then((repo) => {
console.log("Connected. Starting server...");
return server.start({
port: config.port,
repository: repo
});
}).then((app) => {
console.log("Server started successfully, running on port " + config.port + ".");
app.on('close', () => {
repository.disconnect();
});
});我们会有一些小的错误需要处理,除此之外我们需要做的仅仅是加载config,创建仓库以及启动服务器。
这就是一个微服务。它允许我们获得所有的用户,以及搜索任一用户:
HTTP GET /users # gets all users
HTTP GET /search?email=homer@thesimpons.com # searches by email 假如你checkout代码,你可以看到这里有一些可用的命令如下:
cd ./users-service
npm install # setup everything
npm test # unit test - no need for a test database running
npm start # run the server - you must have a test database running
npm run debug # run the server in debug mode, opens a browser with the inspector
npm run lint # check to see if the code is beautiful 除了代码之外你可以看到我们还有如下内容:
- Node Inspector用于调试
- Mocha/shoud/supertest提供单元测试
- ESLint 代码检查
就这些,下面跑一个测试数据库试试:
cd test-database/
./start.sh然后可以看到我们的服务:
cd ../users-service/
npm start 现在你可以在浏览器中访问 localhost:8123/users 并看到相应回应。假如你正在使用Docker机器(例如:你跑着Mac或者Windows上),那么localhost 不会工作,你需要使用Docker机器的IP来替代上述的localhost。你可以使用命令docker-machine ip 来获取docker IP。
上面我们已经快速简略的描述了如何构建一个微服务。
第三步: Dockerising(Docker化)我们的微服务
接下来让我们享受一下docker的乐趣!这里我们已经有了一个可以跑在开发盒子里的微服务,只要有任一兼容的Node.js已经安装。接下来我们要做的就是设置我们的服务从而可以基于它创建Docker镜像,允许把服务部署到任何支持docker的地方。
这里的实现方式是通过创建一个Dockerfile。Dockerfile告诉Docker引擎应该如何创建你的镜像。我们将会在users-service 目录下创建一个简单的Dockerfile并且开始探讨如何使之适应我们的需要。
创建Dockerfile
创建一个新的文本文件名为 Dockerfile 在 users-service/ 目录下,内容如下:
# Use Node v4 as the base image.
FROM node:4
# Run node
CMD ["node"]然后执行下列命令创建镜像以及运行基于这个镜像的一个容器:
docker build -t node4 . # Builds a new image
docker run -it node4 # Run a container with this image, interactive 先来看看build命令。
- docker build 这里告诉docker引擎我们需要创建一个新镜像
- -t node4 命名镜像标签为node4。然后我们可以通过该标签引用这个镜像。
- 使用当前目录作为Dockerfile文件目录
当这些命令台输出完毕之后,我们就可以看到一个新镜像创建完毕。你可以通过命令docker images查看当前系统的所有镜像。下一步的命令基于之前所做的练习你应该已经相当熟悉了:
- docker run 基于一个镜像运行一个新的容器run a new container from an image。
- -it 使用交互式终端模式。
- node4 我们所希望在容器中使用的镜像标签。
当我们的镜像运行起来之后,我们就得到了一个Node repl,可以通过如下命令检查版本号:
> process.version
'v4.4.0'
> process.exit(0)这里有潜在的可能性,docker上的node版本和你本地机器的node版本并不一致。
检查Dockerfile
纵览dockerfile我们可以很容易了解它具体在做什么:
- FROM node:4 在dockerfile中指定的第一件就是基本镜像。通过google的node organisation page on the docker hub可以快速检索出所有可用的镜像。这也是已经安装node.js的ubuntu的基本骨架。
- CMD [“node”] CMD 命令告诉docker这个镜像是支持node可执行的。当node执行终止时,容器也应该被关闭。
通过以下额外的几条命令,可以更新dockerfile来执行我们的服务:
# Use Node v4 as the base image.
FROM node:4
# Add everything in the current directory to our image, in the 'app' folder.
ADD . /app
# Install dependencies
RUN cd /app; \
npm install --production
# Expose our server port.
EXPOSE 8123
# Run our app.
CMD ["node", "/app/index.js"] 这里唯一增加的内容就是会使用ADD 命令来拷贝当前目录下的所有文件到容器中的app/目录下。然后可以使用RUN 来执行镜像中的一个命令,从而安装我们的模块。最终,我们暴露服务器端口,告诉docker我们需要在端口8123上支持入向连接,之后启动我们的服务代码。
以下命令用来检查确认测试数据库服务运行,服务的运行,然后创建和再次运行镜像:
docker build -t users-service .
docker run -it -p 8123:8123 users-service 这里假如你在浏览器中直接访问 localhost:8123/users 将会看到错误,检查控制台终端你将会看到容器报告了一些问题:
--- Customer Service---
Connecting to customer repository...
Connected. Starting server...
Server started successfully, running on port 8123.
GET /users 500 23.958 ms - 582
Error: An error occured getting the users: Error: connect ECONNREFUSED 127.0.0.1:3306
at Query._callback (/app/repository/repository.js:21:25)
at Query.Sequence.end (/app/node_modules/mysql/lib/protocol/sequences/Sequence.js:96:24)
at /app/node_modules/mysql/lib/protocol/Protocol.js:399:18
at Array.forEach (native)
at /app/node_modules/mysql/lib/protocol/Protocol.js:398:13
at nextTickCallbackWith0Args (node.js:420:9)
at process._tickCallback (node.js:349:13)因此,可以看出所有从我们的users-service容器到test-database容器的连接请求都被拒绝了。我们可以试着运行docker ps看看所有正在运行的容器:
CONTAINER ID IMAGE PORTS NAMES
a97958850c66 users-service 0.0.0.0:8123->8123/tcp kickass_perlman
47f91343db01 mysql:latest 0.0.0.0:3306->3306/tcp db很显然,它们都在,那么是怎么回事呢?
连接容器
其实我们看到的这个问题是预期的,Docker容器都应该是彼此隔离的,所以创建容器之间的连接本来就是不合理的,除非我们有显式的允许它们这么做。
是的,我们可以连接我们的主机和容器,因为我们已经对此开放了端口(例如通过-p 8123:8123)。假设我们允许容器之间也能同样交流,那么在同一个主机上的两个容器能够相互沟通,甚至开发者完全没有计划这么做,那这将是一个彻底的灾难,特别是当我们在一个集群的大量机器上运行基于容器的各种不同应用程序时。
假如我们需要连接不同的容器时,我们需要连接(link)它们,它的目的在于显式的告诉docker我们允许它们相互通讯。这里有两种方式可以实现,第一种是老的模式,但是毕竟简单,第二种我们将在稍后介绍。
通过’link’ 参数连接容器
当我们在运行容器时,可以通过link 参数告诉docker我们计划连接到另一个容器。在我们的例子中,我们可以通过如下命令来正确运行我们的服务:
docker run -it -p 8123:8123 --link db:db -e DATABASE_HOST=DB users-service - docker run -it 该命令以交互式终端模式基于docker镜像启动一个容器。
- -p 8123:8123 映射主机8123端口到容器的8123端口。
- link db:db 连接名为 db 的容器并且称之为 db。
- -e DATABASE_HOST=db 设置环境变量DATABASE_HOST 值为 db.
- users-service 容器运行的镜像名。
现在我们可以访问localhost:8123/users 并测试,一切都应该工作正常了。
它是如何工作的
还记得我们的服务配置文件?它使我们能够使用环境变量指定的数据库主机:
// config.js
//
// Simple application configuration. Extend as needed.
module.exports = {
port: process.env.PORT || 8123,
db: {
host: process.env.DATABASE_HOST || '127.0.0.1',
database: 'users',
user: 'users_service',
password: '123',
port: 3306
}
};当运行容器时,我们设置了环境变量DB ,这意味着我们要连接到一个叫做DB的主机。 这是连接到容器时由docker引擎自动设置的。
要看到这个动作,可以尝试运行docker ps列出所有正在运行的容器。 查找运行的容器镜像名称users-service ,然后可以得到一个随机的名字,如下例trusting_jang :
docker ps
CONTAINER ID IMAGE ... NAMES
ac9449d3d552 users-service ... trusting_jang
47f91343db01 mysql:latest ... db 现在可以看一下我们的容器上可用的主机:
docker exec trusting_jang cat /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.17.0.2 db 47f91343db01 # linking magic!!
172.17.0.3 ac9449d3d552 还记得docker exec是工作的吗?首先选择容器名称,然后跟随的命令就是无论任何你想要在容器中执行的,在本例中 cat /etc/hosts 。
很明显hosts文件并没有什么linking魔法。所有这里你可以看到docker已经把 db加到了我们的hosts文件中,这样我们就可以通过主机名链接到容器。这就是linking的其中一个结果。以下是其他更多详细内容:
docker exec trusting_jang printenv | grep DB
DB_PORT=tcp://172.17.0.2:3306
DB_PORT_3306_TCP=tcp://172.17.0.2:3306
DB_PORT_3306_TCP_ADDR=172.17.0.2
DB_PORT_3306_TCP_PORT=3306
DB_PORT_3306_TCP_PROTO=tcp
DB_NAME=/trusting_jang/db 从上述命令我们可以看到当docker连接容器时,它同样提供了一系列的环境变量以及一些非常有用的信息。我们可以知道host,tcp端口以及容器名。
至此第三步就结束了。我们已经有了一个在容器上顺利运行的MySQL数据库,也有一个既可以在本地也可以在容器上运行的node.js微服务,并且知道如何把这两个容器连接在一起。
你可以学习了解更多本阶段的代码细节,具体见step3。
第四步:集成测试环境
现在,我们可以调用实际的服务器写一个集成测试,以docker的容器模式运行,调用容器化的测试数据库。
在合理范围内,我们可以使用任何一种语言或者平台来编写集成测试,但为了简便,这里我使用Node.js,就像在我们的项目中已经看到的Mocha和Supertest一样。
建立一个新的目录,命名为 integration-tests 并创建一个 index.js文件如下:
var supertest = require('supertest');
var should = require('should');
describe('users-service', () => {
var api = supertest('http://localhost:8123');
it('returns a 200 for a known user', (done) => {
api.get('/search?email=homer@thesimpsons.com')
.expect(200, done);
});
});这将检查API调用并显示测试结果。只要你的users-service和test-database都在运行,测试就会通过。 然而,到了这个阶段,服务将会越来越难处理:
- 我们必须使用一个shell脚本来启动和停止数据库
- 我们必须记住针对数据库的用户服务启动命令序列
- 我们必须使用node直接运行集成测试
现在我们已经对docker有了更多了解,我们可以用docker解决这些问题。
简化测试数据库
当前,对于测试数据库我们有如下文件:
/test-database/start.sh
/test-database/stop.sh
/test-database/setup.sql现在我们对docker有了更多了解,我们可以来着手改善这个。在Docker Hub的mysql image documentation 有一个提示告诉我们所有被添加到镜像/docker-entrypoint-initdb.d 目录的.sql 或 .sh 文件在配置数据库时都会被自动执行。
这就意味这我们可以用dockerfile来替代start.sh 和 stop.sh脚本。
FROM mysql:5
ENV MYSQL_ROOT_PASSWORD 123
ENV MYSQL_DATABASE users
ENV MYSQL_USER users_service
ENV MYSQL_PASSWORD 123
ADD setup.sql /docker-entrypoint-initdb.d 现在运行我们的测试数据库只需要如下命令:
docker build -t test-database .
docker run --name db test-database 编排(Composing)
至此,构建和运行每个容器仍然需要消耗一定时间。我们可以采用Docker Compose工具来更进一步提高。
Docker Compose可以让你创建一个文件定义系统中的每个容器,它们之间的关系,并建立或运行它们。
首先,我们需要安装 Docker Compose。然后在根目录下创建如下新文件命名为 docker-compose.yml:
version: '2'
services:
users-service:
build: ./users-service
ports:
- "8123:8123"
depends_on:
- db
environment:
- DATABASE_HOST=db
db:
build: ./test-database然后检查运行结果:
docker-compose build
docker-compose up Docker Compose已经创建了我们应用程序所需的所有镜像,基于它们创建了相应容器,并以正确的序列执行它们从来启动完整的技术栈。
docker-compose build 命令负责创建在文件docker-compose.yml中列出的所有镜像。
version: '2'
services:
users-service:
build: ./users-service
ports:
- "8123:8123"
depends_on:
- db
environment:
- DATABASE_HOST=db
db:
build: ./test-database这里的 build 值是我们的每个服务告诉docker到哪里可以找到相应的Dockerfile。当执行 docker-compose up时,docker启动所有的服务。请注意,从Dockerfile 我们可以指定端口和依赖关系。事实上,这里有大量的配置是我们可以改变的。在另一个终端执行 docker compose down 正常关闭所有的容器。
总结
在本文中我们已经看了大量docker的介绍,但是这远远不够。我希望这些能够带你发现一些感兴趣和实用的东西,从而帮助你在实际的工作中应用docker。
像往常一样,非常欢迎给我问题和建议。同时我也强烈推荐阅读下列文档: Understanding Docker 从而得到对docker工作机制更深的理解。
你也可以访问以下链接得到本文中项目最终的所有源代码:
github.com/dwmkerr/node-docker-mircroservice
提示
- 拷贝一切是个坏主意,因为我们会同时拷贝node_modules目录。通常,你最好是显式的列出需要拷贝的文件和目录,或者使用一个.dockerignore,就像使用.gitignore一样。
- 假如服务器并没有按预期运行,这可能并不是真正麻烦的异常,而可能是supertest的一个bug。具体见github.com/visionmedia/supertest/issues/314
原文链接: http://www.dwmkerr.com/learn-docker-by-building-a-microservice/















 772
772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









