






仿基因编程要点及其
C++
实现
作者
:
关文林
MSN:guanwl2000@hotmail.com
QQ
号
:707351736
1. 程序员的梦(为什么要进行仿基因编程)
1.1.自由的双向的功能扩充的梦(程序员之盼)
需求的变化在编程工作中非常常见。程序员常常被这样的变化搞的顾此失彼
,
加班加点。“要是我的程序能够适应这种经常的变化就好了”,程序员们常常这样想。
在编程工作中常有这样的情况,要把两个或多个功能组合,以实现更为强大的功能。也会有这样的情况出现,一些功能需要组合,但怎样组合却不是在程序发布时所能确定,而要在程序的使用中确定。怎样让这样的组合能够安全,快捷,直观,易用。是一个很有挑战性的工作。“不就是把已有的功能合并一下吗,怎么就这么不顺利呢?”程序员常常会这样问。
传统的错误处理采用这样的方式:对于每一种错误定义一个错误
ID
,并再对应每一个错误
ID
做一个文本描述。这样的错误管理是繁琐而枯燥的。这样的错误处理模式对于客户程序员来说更是索然无味,他们需要一个一个的记这些错误
ID
。“这个错误提示怎么就这么不清楚呢!”程序员常常这样叹。
要是做到以上这三点,而且还能安全,高效,简单就好了。本文所讲的仿基因编程就是这样的一个安全,高效,简单的方法。下面我分几个小的片断来为大家说明仿基因编程的实现方法。
(
原谅我用华丽的词做标题吧
)
通过对编程工作进行抽象化,我们可以找到两个必不可少的概念,数据和数据处理。再把编程工作的范围扩大到单个公司之外,那么我们发现公司这个概念也是必不可少的。因为同一个数据处理在不同的公司会有不同的处理过程或不同的处理结果。
现在我们来概括一下,公司、数据处理、数据这三者之间的关系。同一个数据,对于不同的数据处理,它会有不同的侧重面,甚至不同的意义。同一个数据处理,在不同的公司会有不同的实现。
这就有了一个这样的有趣的关系。数据与数据处理相关,数据处理和公司相关。这个时候我们惊讶地发现。这三个概念与接口的三个要素一一对应。公司对应接口名,数据处理对应接口方法,数据对应接口方法的参数。
说实话当我发现这个对应时,我也曾一度沮丧,不知道是不是还要把“仿基因编程“继续做下去。但细一想,发现公司、数据处理、数据这三个概念之间的关联要比接口、接口方法、方法参数这三个之间的关联要松散的多。前者只是意义上的相关,后者语法上就是相关的。有了这种仅在意义上的相关,我们的自由组合就有了一个好的基础。(注:用数据处理机来替换数据处理会给我们的表达带一来些方便,所下面的叙述中我可能会用‘数据处理机’或‘处理机’来表示数据处理这个概念。)
经过对编程工作的高度抽象我们得出三个不可或缺的概念,公司,处理机和数据。如果我们再进一步对这三个概念进行抽象化,我们可以抽象出一个编程元素来概括这三个概念。于是我们得到一个这样结构。如图
3-1
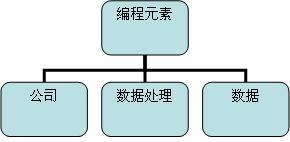
图
3-1
前面我们从编程工作中提取出四个要素。但这些要素现在只有一个名字。我们需要为它们定义一些职责。
编程元素应该有什么职责呢?能被程序处理应该是它的适当的职责,不是吗?它的另一个职责就是:能被别的类继承。于是我们定义编程元素如下:
class
Element
{
public
:
virtual ~Element(){}
};
现在我们有了一个
Element
的类,这个类除了能被程序处理外,还真看不出它有什么其它用途。至于它那个虚析构函数,表明它可以被别的类安全地继承。
(
这是
C++
语言本身的原因
)
公司应该有什么职责呢?公司应该有一个名字,对吧?就象接口有一个名字一样。于是我们定义公司如下:
class
Company:public Element{};
数据应该有什么职责呢?数据应该能被处理机所处理,对吧?于是我们定义数据如下:
class
Data:public Element{};
数据处理机应该有什么职责呢?数据处理机应该能够处理数据,对吧?于是我们定义数据处理如下:
class
Processor:public Element
{
public
:
virtual void Set(Data& data){}
virtual void Get(Data& data){}
};
还记得前面说的公司,数据处理,数据之间的松散的关系吗?我们这里的定义把这三者的关系表述清楚了吗?没有表述清楚。我们把没表述清楚的那部分留到分门别类那一小节来讲。现在我们先把这四个要素的
UML
类图给大家展示一下,用以加深映像。如图
4-1
。
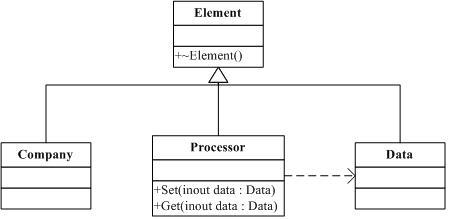
图
4-1
这时我们有了无限多种可以接受无限多种数据的处理机了。不是吗?从
Processor
派生而来的任意的处理机可以接受从
Data
派生而来的任意数据。
梆,梆,梆(敲门声)
谁?(门里)
我。(门外)
接下来发生了
…..
的事情。这是日常生活中常见的情景。
在仿基因编程中也有相类似的事情。比如处理机拿到一个数据,它如果不问一下
,
那么它就只能知道这是一个数据。而我们对数据的定义却是一个什么也没有的空壳。能对一个空壳能进行什么处理呢?
所以一定是要处理从
Data
派生而来的数据。可是由于子类型向上转型的过程中,子类型的信息丢失了。(
Get
和
Set
只接受
Data
类型的数据)所以处理机需要问一下数据‘你到底是什么样的具体数据?’。然后再依据具体的数据类型进行
……
的处理。
对于公司和处理机也是同样存在这个一问一答事情。你有必要知道和你做生意的是哪家公司,而不是仅知道你在和一些公司做生意,不是吗?
于是我们修改
Element
的定义让它多一个职责,那就是如果问它“你是谁?”,它能回答。
class
Element
{
public
:
virtual ~Element(){}
virtual void Who()= 0; //
注意这是一个纯虚函数
};
怎么回答这个“你是谁?”的问题呢?说难也难,《C++设计新思维》中列出了三种回答方法,有兴趣的朋友可以去看一看(或复习一下)。说容易也容易,直接回答“我”就行了。于是我们让那些要具体化的元素,在实现Who这个虚函数时这样做:把自身的指针作为一个异常抛出。如下:
virtual void Who(){throw this;}
是不是很简单?这个
Who
用到的地方太多了,而且还是这样的死板。用一个宏把它写好是一个不错的主意。不是吗?于是我们写下这样的一个宏。
#define
WHO virtual void Who(){throw this;}
不过
,
现在发问的一方就要按这样的方式来处理这个回答了:
try
{
data.Who();
}catch(
这种* pdata){.....}
catch
(
那种* pdata){.....}
可以很轻松地写好这个try,catch对吧?不过我的经验是:这个try,catch很容易认人眼花缭乱。让一个宏来做这个事吧。于是再写这样一个宏:
#define
DATA_HANDLE(TARGETTYPE, FUNCTION) catch(TARGETTYPE* exdata){return FUNCTION((TARGETTYPE&)*exdata);}
这下我们可以干巴利落脆地解决“谁?”,“我。“这个事情了。
|
编程元素
|
是对编程中所能遇到的所有概念的高度抽象。它被抽象的只剩下了一个特性:能被鉴别身份。
|
|
公司
|
是对编程工作中的参与者的抽象,它被抽象得只剩下一个名字。它的唯一的功能就是:表示出‘我参与了
……
的编程’。
|
|
处理机
|
是对数据加工的抽象。它被抽象得只剩下能处理数据这个特性了。
|
|
数据
|
是对数据的抽象。它被抽象得只剩下一个数据的空名。它的唯一的功能就是:能被处理机处理。
|
现在我们的仿基因编程已经初具规模了。任意的处理机可以处理任意的数据。并且这些处理机和数据可以任意的增长。这就象是地球上刚有了生命,这些生命虽然低级,但它可以进化,直到有了人这样的高级生命。
要是你问李连杰“你是谁?”,你猜他会怎么回答。我想李的回答应该是这样的:有时他会说‘我是黄飞鸿’:有时他会说‘我是方世玉’:有时
……
。对于做演员他这样回答,我们能拿他怎么办呢。只能是:他演‘黄飞鸿’的时候我们把他当‘黄飞鸿’看待,他演‘方世玉’的时候我们把他当‘方世玉’看待。
除了演员这种情况外,‘蛹和蝶’这种现象也有这种冒名顶替的情况。
在仿基因编程的世界里也有这样的情况。数据
A
可以随时对询问它的人说‘我是数据
B
’,或者说‘我是数据
C
’。这种情况在仿基因编程中是允许的。这是也我采用了上面的方法来回答“你是谁?”这样的问题,而没有采用《
C++
设计新思维》中所列出的哪几种。因为它们不允许冒名顶替。
有了冒名顶替这个机制,我们可以做好多大事了。就好比一个演员可以扮演一代英豪。不是这样吗?让我们记住冒名顶替这个机制,它还会在以后的小节中登场,做出更为精彩的表演。
上面说在仿基因编程模式下,处理机和数据可以自由地增长。我们可以想象一下,在这种情况下,数据类型的增长将会非常的快。用不了多久我们就会得到一个不可计数的“数据类型集”。对这个“数据类型集”进行分类是必要的。这里有两个天然的分类标准:公司和处理机。好,我们就用这两个标准来对数据分类。于是我们定义这样一个模板:
template
<class PROCESSOR = Processor, class COMPANY = Company>
class
LocalData:public Data
{
public
:
typedef LocalData
localType;
};
有了这个LocalData模板,我们再也不用为飞速增长的数据类型发愁了。让每一个新增的数据类型从一个LocaData派生。这个数据是哪家公司的哪一个处理机所要处理的数据就一目了然了。
同样我们也可以对处理机依据公司来做分类。但我认为这是一个画蛇添足的功能了。请看‘走自己的路’那一节。
现在让我们来为错误处理做一些安排。还记得
Processor
的
Get
和
Set
两个方法吧。它们的返回类型为
void
。要是在
Get
和
Set
过程中发生了错误怎么办呀?这个
void
型的返回,对此无能为力。把它们改成
int
型的返回吗?不
,
让它们抛出一个异常。让这个抛出的异常来说明到底发生了什么错误。
于是我们定义一个
ErrorInfo
的类,当有错误时我们把这个类的一个对象抛出。它的定义如下:
class
ErrorInfo:public Data
{
public
:
unsigned int id; //
一个标号
string info; //
错误的详细说明
WHO
};
有了这个
ErrorInfo
,在有错误的时候,我们就可以指定一个
id
和对应的
info
并把这个当作异常抛出。
我们可以定义一在堆的特定的
id
,让每一个
id
表示一个特定的意义。可是我们定义多少个这样的
id
才合适呢?要知道我们的整个系统可以不停地增长,那些新长出来的部分会发生什么错误是不能预知的。所以定义特定的
id
是行不通的。
怎么办?要是能为每一个公司的每一个处理机的每一种数据都定义一个
ErrorInfo
就好了。于是我们定义一个模板如下:
template
<class PROCESSOR = Processor, class DATA = Data, class HISTICYTE = Histicyte>
class
LocalError:public ErrorInfo{
WHO
};
这下当有一个错误抛出时,只要问它‘你是谁?’,这个错误就会回答说‘我是某某公司的某某处理机在处理某某数据时发生的一个编号为这个
id
的,详细信息是这样的一个错误’。哈哈,直捣黄龙。
这样我们就可以只为那些可预知的
id
编号就行了。
如果给牛端上一份香喷喷的烤鸭做午餐,会有什么事发生呢?首先牛会挨饿,其次烤鸭会被浪费。我们应试给牛青草才对。
如果把处理机
A
不能处理的数据交给它进行处理,会有什么事发生呢?首先和牛挨饿没关系,其次发生了浪费,再次‘天,怎么会发生这种事呢’
,
再其次‘得想个办法杜绝这种事’。
在牛旁边放一个告示,写上:‘牛不吃烤鸭’,会有一些效果。但可能会发生把清炖甲鱼给牛做午餐的事,或其它的更严重的午餐事件。最好的办法是让一个了解牛的人来为牛的午餐把关。
好,让我们来为处理机找一个把关的人吧。于是我们定义一个这样的模板
template
<class PROCESSOR, class COMAPNY = Company>
class
ProcMatch
{
public
:
typedef LocalData
datatype;
//
所能处理的数据类型
void Get(datatype& data){m_proc->Get(data);}
void Set(datatype& data){m_proc->Set(data);}
private
:
PROCESSOR *m_proc;
};
这下当把处理机
A
不能处理的数据传过来的时候,编译器就会站出来说:‘嗨,牛不吃烤鸭’。
我们把这个为处理机把关的
ProcMatch
叫做“处理机匹配器“,简称匹配器,好吗?
让那个只管牛午餐的人多做点事吧!他怎么就不能把早餐和晚餐也管起来呢?
让
匹配器
多做点事吧!
匹配器还能做点什么呢?让它的构造函数负责创建一个新的处理机,让它的析构函数负责消毁这个处理机。应该是个好主意吧?必竟,如果没有牛,还要牛的午餐负责人做什么呢?
下面我们让匹配器再来做一个更精彩的表演,链式调用。
现在更改
ProcMatch
的定义看起来象这样:
template
<class PROCESSOR, class COMAPNY = Company>
class
ProcMatch
{
public
:
typedef LocalData
datatype;
//
所能处理的数据类型
typedef ProcMatch
MatchType;
//
自己的类型
MatchType& operator >>(datatype& data){m_proc->Get(data); return *this;}
MatchType& operator <<(datatype& data){m_proc->Set(data); return *this;}
ProcMatch(){ //m_proc = new.....;
}
~ProcMatch(){delete m_proc;}
private
:
PROCESSOR *m_proc;
};
这下,就可以象使用输入输出流那样使用匹配器了。连贯地<
<或>
>是不是比断断续续地Set,Get舒服多了?
同一个处理机在不同的公司会有不同的表现。同一个公司的同一个处理机也会有不同的版本。匹配器要怎样才能构建出这些外表一样,实现却不一样的处理机呢?
这个问题有点儿绕,下面我用一段代码来先把这个问题说清楚,然后再说它的解决办法。请看下面这段代码:
class
procA:public Processor{}; //
定义一个处理机procA
class
implA_a:public procA{}; //
处理机procA的第一种实现implA_a
class
implA_b:public procA{}; //
处理机procA的第二种实现implA_b
现在,如果要建立
procA
的匹配器,那么匹配器到底该用
implA_a
呢,还是用
implA_b
呢?显然匹配器没有足够的信息来让它做出这个决策。再给匹配器添加一个模板参数,来携带这些信息好不好?不好。因为在大多数情况下处理机的真正实现是不宜公开源码的。对于
implA_a
或
implA_b
,你也许只能得到一个
lib
或
dll
文件(
windows
下)。放弃添加模板参数的想法吧。
虽然‘处理机的真正实现’的源码不宜公开,但是建立一个‘处理机的真正实现’的方法却是要必需公开的。好,我们就从这个必需公开的地方下手。我们来规定,在仿基因编程中凡是要建立处理机的真正实现的地方,公开类似这样的一个函数定义:
Processor * Create(Processor& proc)
。其中参数
proc
是一个没有被真正实现的处理机,返回的是一个处理机的真正实现的指针。
这时在哪儿可以找到这个
Create
函数就成了焦点了。我们把这个位置传给匹配器的构造函数,匹配器就可以正确的建立处理机的真正实现了。
如果你有一个非常特殊的建立处理机的方法,你可以特化匹配器。但更好的做法是:给匹配器加一个模板参数,让这个模板参数作为“构建处理机的真正实现”的
policy
。(关于
policy
,请大家参考(或复习)《
C++
设计新思维》)
匹配器还可以做更多的事,但这些与“仿基因编程“关系不大,就不在这篇文章中啰嗦了。
在实际环境中,数据很少单独存在,它们之间常常有着各种各样的关系,而且这些关系大部分不是数据提供方所能预先知道的,而是要由数据的使用方在使用过程中决定的。我们就把这样的应用叫它‘数据群落’吧。数据群落可以更好地体现数据的价值,理应在程序中得到好的支持。
想一想我们的处理机和数据的关系,不论是
Get
还是
Set
一次只能处理一个数据。那么是不是让这单个的数据包含很丰富的内容是一个好主意呢?不是。好主意应该是这样的:把数据尽可能的分散,然后由使用方来自由组合这些分散的数据。
那么,使用方该如何组合这些数据呢?一个最直接的办法是:使用方生成新的数据类型作为一个数据群落,让新群落包含那些分散的数据。最后把这个新的群落传给处理机。但是这样做有一个问题,那就是处理机不能识别出这个新群落。在这种情况下,使用方只能让提供方升级处理机来处理这个新群落。
如果按照上面的方法来对付数据群落,时间成本是相当大的。此外还有一个问题就是,过了一段时间后,使用方发现这样的新群落不再需要了,停止了这个新群落的使用。那么对于处理机,就多了个没有必要的群落处理。这是很不合理的。同样要是这个群落发生了一些变化呢?要知道群落会经常变化。
怎样才能让群落的产生、变化和消亡都不影响处理机呢?让群落自身来负责它所包含的数据的
Get
和
Set
动作是一个好主意。必竟只有群落自己最清楚这些数据之间的关系。那么群落就需要一个处理机名柄,把匹配器作为这样的句柄交给群落是个好主意。
数据群落就如同为处理机提供了一个脚本编程的空间,使我们的程序的灵活性大大的提升。
后面的几个小节我觉得不用再写了。先放出来大家看看。还有没有必要再写了。














 92
92











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









