







从一个问题说起
五年前在tx的时候,发现分页场景下,mysql请求速度非常慢。数据量只有10w的情况下,select xx from 单机大概2,3秒。我就问我导师为什么,他反问“索引场景,mysql中获得第n大的数,时间复杂度是多少?”
答案的追寻
确认场景
假设status上面有索引。select * from table where status = xx limit 10 offset 10000。会非常慢。数据量不大的情况就有几秒延迟。
小白作答
瞎猜了个log(N),心想找一个节点不就是log(N)。自然而然,导师让我自己去研究。
这一阶段,用了10分钟。
继续解答
仔细分析一下,会发现通过索引去找很别扭。因为你不知道前100个数在左子树和右子数的分布情况,所以其是无法利用二叉树的查找特性。通过学习,了解到mysql的索引是b+树。
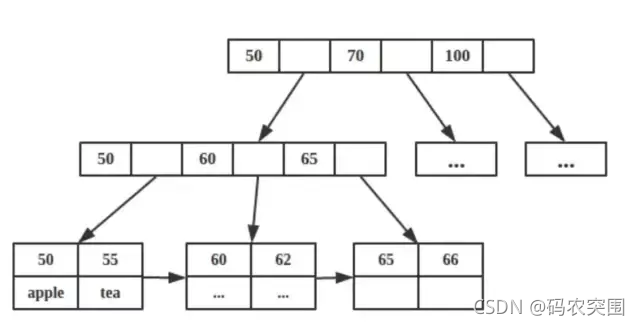
看了这个图,就豁然开朗了。可以直接通过叶子节点组成的链表,以o(n)的复杂度找到第100大的树。但是即使是o(n),也不至于慢得令人发指,是否还有原因。
这一阶段,主要是通过网上查资料,断断续续用了10天。
系统学习
这里推荐两本书,一本《MySQL技术内幕 InnoDB存储引擎》,通过他可以对InnoDB的实现机制,如mvcc,索引实现,文件存储会有更深理解。
第二本是《高性能MySQL》,这本书从着手使用层面,但讲得比较深入,而且提到了很多设计的思路。
两本书相结合,反复领会,mysql就勉强能登堂入室了。
这里有两个关键概念:
- 聚簇索引:包含主键索引和对应的实际数据,索引的叶子节点就是数据节点
- 辅助索引:可以理解为二级节点,其叶子节点还是索引节点,包含了主键id。
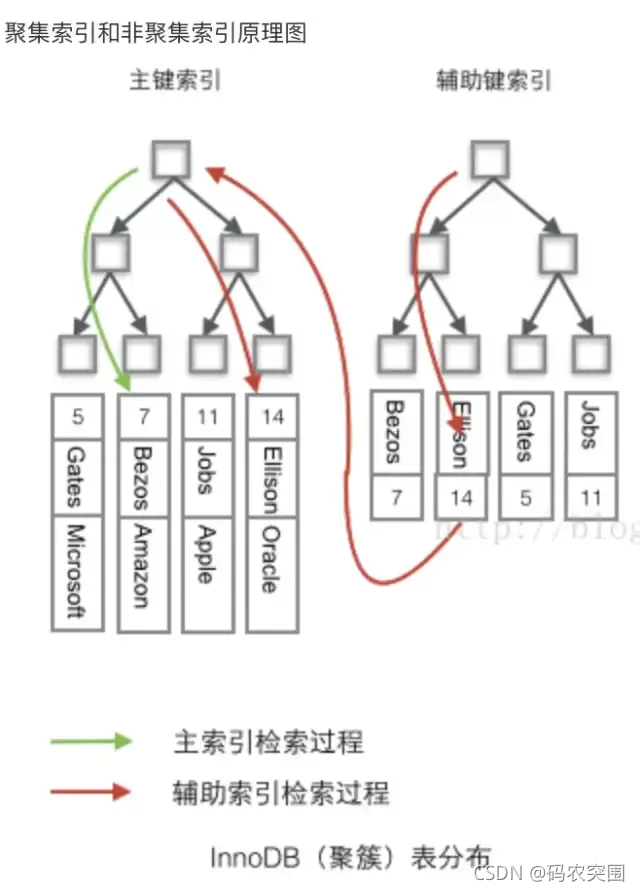
即使前10000个会扔掉,mysql也会通过二级索引上的主键id,去聚簇索引上查一遍数据,这可是10000次随机io,自然慢成哈士奇。这里可能会提出疑问,为什么会有这种行为,这是和mysql的分层有关系,limit offset 只能作用于引擎层返回的结果集。换句话说,引擎层也很无辜,他并不知道这10000个是要扔掉的。以下是mysql分层示意图,可以看到,引擎层和server层,实际是分开的。
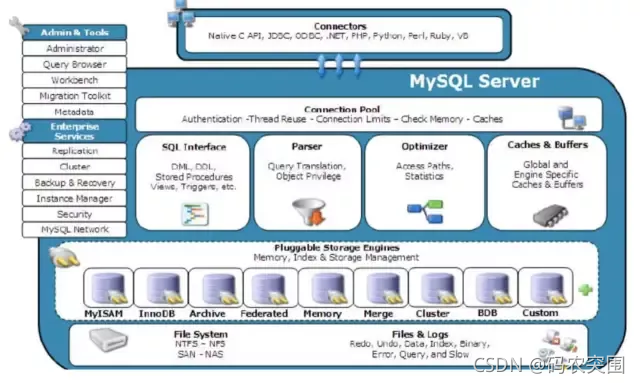
直到此时,大概明白了慢的原因。这一阶段,用了一年。
触类旁通
此时工作已经3年了,也开始看一些源码。在看完etcd之后,看了些tidb的源码。无论哪种数据库,其实一条语句的查询,是由逻辑算子组成。
逻辑算子介绍 在写具体的优化规则之前,先简单介绍查询计划里面的一些逻辑算子。
- DataSource 这个就是数据源,也就是表,select * from t 里面的 t。
- Selection 选择,例如 select xxx from t where xx = 5 里面的 where 过滤条件。
- Projection 投影, select c from t 里面的取 c 列是投影操作。
- Join 连接, select xx from t1, t2 where t1.c = t2.c 就是把 t1 t2 两个表做 Join。
选择,投影,连接(简称 SPJ) 是最基本的算子。其中 Join 有内连接,左外右外连接等多种连接方式。
select b from t1, t2 where t1.c = t2.c and t1.a > 5 变成逻辑查询计划之后,t1 t2 对应的 DataSource,负责将数据捞上来。上面接个 Join 算子,将两个表的结果按 t1.c = t2.c连接,再按 t1.a > 5 做一个 Selection 过滤,最后将 b 列投影。下图是未经优化的表示:
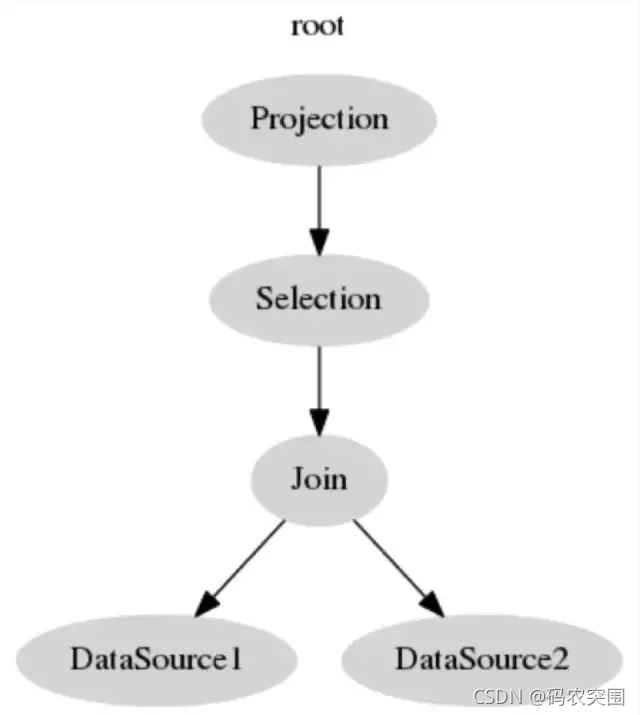
所以说不是mysql不想把limit, offset传递给引擎层,而是因为划分了逻辑算子,所以导致无法直到具体算子包含了多少符合条件的数据。
怎么解决
《高性能MySQL》提到了两种方案
方案一
根据业务实际需求,看能否替换为下一页,上一页的功能,特别在ios, android端,以前那种完全的分页是不常见的。这里是说,把limit, offset,替换为>辅助索引(即搜索条件)id的方式。该id再调用时,需要返回给前端。
方案二
正面刚。这里介绍一个概念:索引覆盖:当辅助索引查询的数据,只有id和辅助索引本身,那么就不必再去查聚簇索引。
思路如下:`select xxx,xxx from in (select id from table where second_index = xxx limit 10 offset 10000)`` 这句话是说,先从条件查询中,查找数据对应的数据库唯一id值,因为主键在辅助索引上就有,所以不用回归到聚簇索引的磁盘去拉取。再通过这些已经被limit出来的10个主键id,去查询聚簇索引。这样只会十次随机io。在业务确实需要用分页的情况下,使用该方案可以大幅度提高性能。通常能满足性能要求。
来源 | https://juejin.cn/post/6844903939247177741














 956
956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









