







参考文章:http://www.cnblogs.com/likehua/p/3796802.html
分布式缓存
在分布式缓存(图1.12)中,每个节点都会缓存一部分数据。如果把冰箱看作食杂店的缓存的话,那么分布式缓存就象是把你的食物分别放到多个地方 —— 你的冰箱、柜橱以及便 当盒 ——放到这些便于随时取用的地方就无需一趟趟跑去食杂店了。缓存一般使用一个具有一致性的哈希函数进行分割,如此便可在某请求节点寻找某数据时,能够迅速 知道要到分布式缓存中的哪个地方去找它,以确定改数据是否从缓存中可得。在这种情况下,每个节点都有一个小型缓存,在直接到原数据所作处找数据之前就可以 向别的节点发出寻找数据的请求。由此可得,分布式缓存的一个优势就是,仅仅通过向请求池中添加新的节点便可以拥有更多的缓存空间。分布式缓存的一个缺点是修复缺失的节点。一些分布式缓存系统通过在不同节点做多个备份绕过了这个问题;然而,你可以想象这个逻辑迅速变复杂了,尤其是当你 在请求层添加或者删除节点时。即便是一个节点消失和部分缓存数据丢失了,我们还可以在源数据存储地址获取-因此这不一定是灾难性的!
代理
简单来说,代理服务器是一种处于客户端和服务器中间的硬件或软件,它从客户端接收请求,并将它们转交给服务器。代理一般用于过滤请求、记录日志或对请求进行转换(增加/删除头部、加密/解密、压缩,等等)。

假设,有几个节点都希望请求同一份数据,而且它并不在缓存中。在这些请求经过代理时,代理可以通过压缩转发技术将它们合并成为一个请求,这样一来,数据只 需要从磁盘上读取一次即可(见图1.14)。这种技术也有一些缺点,由于每个请求都会有一些时延,有些请求会由于等待与其它请求合并而有所延迟。不管怎么 样,这种技术在高负载环境中是可以帮助提升性能的,特别是在同一份数据被反复访问的情况下。压缩转发有点类似缓存技术,只不过它并不对数据进行存储,而是 充当客户端的代理人,对它们的请求进行某种程度的优化。
在一个LAN代理服务器中,客户端不需要通过自己的IP连接到Internet,而代理会将请求相同内容的请求合并起来。这里比较容易搞混,因为许多代理同时也充当缓存(这里也确实是一个很适合放缓存的地方),但缓存却不一定能当代理。

1.14
另一个使用代理的方式不只是合并相同数据的请求,同时也可以用来合并靠近存储源(一般是磁盘)的数据请求。采用这种策略可以让请求最大化使用本地数据,这 样可以减少请求的数据延迟。比如,一群节点请求B部分信息:partB1,partB2等,我们可以设置代理来识别各个请求的空间区域,然后把它们合并为 一个请求并返回一个bigB,大大减少了读取的数据来源(查看图Figure 1.15)。当你随机访问上TB数据时这个请求时间上的差异就非常明显了!代理在高负载情况下,或者限制使用缓存时特别有用,因为它基本上可以批量的把多 个请求合并为一个。
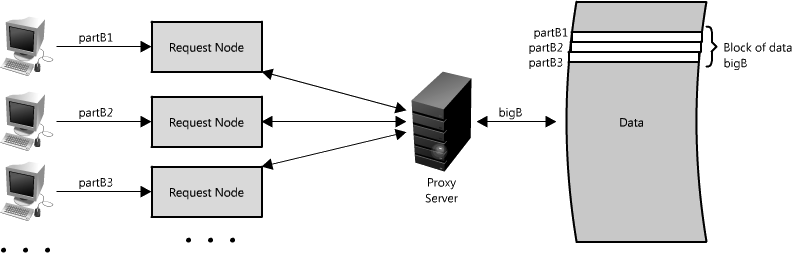
Figure 1.15: Using a proxy to collapse requests for data that is spatially close together
值得注意的是,代理和缓存可以放到一起使用,但通常最好把缓存放到代理的前面,放到前面的原因和在参加者众多的马拉松比赛中最好让跑得较快的选手在队首起 跑一样。因为缓存从内存中提取数据,速度飞快,它并不介意存在对同一结果的多个请求。但是如果缓存位于代理服务器的另一边,那么在每个请求到达 cache之前都会增加一段额外的时延,这就会影响性能。
如果你正想在系统中添加代理,那你可以考虑的选项有很多;Squid和Varnish都经过了实践检验,广泛用于很多实际的web站点中。这些代理解决方案针对大部分client-server通信提供了大量的优化措施。将二者之中的某一个安装为web服务器层的反向代理(reverse proxy,下面负载均衡器一节中解释)可以大大提高web服务器的性能,减少处理来自客户端的请求所需的工作量。














 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









