







1. 11g以前的行列转换
领袖又说了:“温故而知新”。那就让我们先看看11g以前是怎么实现地。行列转换一直当作甄别老手和新手的试金石,面试的时候面试官不问这个都不好意思张嘴。Itpub的Oracle开发版更是每隔十天半个月就有人问这个,你说重要不重要。
假设有表emp_phone如下:
NAME TYPE PHONE
张三 1 1234-5678
张三 2 4567-7890
张三 3 6000-1001
李四 1 2123-1237
李四 3 6001-5600
马五u 1 3248-1378
马五 2 3423-3948
王二(没麻子) 2 2890-1245
。。。
表里放着张三李四王二麻子等等主人翁的电话号码。(TYPE 1/2/3分别对应家/办公室/手机)。如果要把每个人的所有电话放在一行上,就是行转列了。结果如下:
NAME HOME OFFICE MOBILE
张三 1234-5678 4567-7890 6000-1001
李四 2123-1237 6001-5600
马五 3248-1378 3423-3948
王二(没麻子) 2890-1245
写这个SQL的技巧就是按姓名分组,然后使每一组每一类的电话号码最多只有一个,里边用到的分组函数都是聋子的耳朵-摆设。用MAX可以,MIN也行。
这个查询写出来就是:
SELECT
name,
MAX(decode(type, 1, phone)) Home,
MAX(decode(type, 2, phone)) Office,
MAX(decode(type, 3, phone)) Mobile
FROM
emp_phone
GROUP BY
Name
/
那位看官说了:“能不能再变回去?”能,不能戏法不就漏了不是?
这儿要用到另一的技巧就是笛卡尔乘积,将一行复制成三行,每一行取一个类型的电话
偷个懒儿把上边的结果表叫emp_phone_x,把列还原成行的SQL:
SELECT
NAME,
DECODE (lvl, 1, home, 2, office, 3, mobile) phone
FROM
emp_phone_x,
(SELECT LEVEL lvl
FROM DUAL
CONNECT BY LEVEL <= 3)
WHERE
DECODE (lvl, 1, home, 2, office, 3, mobile) IS NOT NULL /
2. 11g 自带的行列转换
旁边那个带眼镜,说的就是你,眼珠子直勾勾的怎么了?上面的没看懂? 要是以前,我老先生就得语重心长地教育你,那么重要的东西没看懂,将来想不想换工作了?但现在这话就说不出口了,因为11g的SQL自己就带这个了。
11g在SELECT语句中新加了关键词PIVOT和UNPIVOT,用这两个关键词,重写上面的两个查询,就变成这个样子的了:
行变列:
SELECT * FROM emp_phone
PIVOT (
MAX(phone) for type IN (1 as home, 2 as office, 2 as mobile)
)
/
PIVOT以后的字句都是新加的。但万变不离其宗,还是要用到分组函数。IN后边是按type的不同值映射成不同的列。简单吧?
列变行,这是UNPIVOT的工作,写法如下:
SELECT * FROM emp_phone_x
UNPIVOT ( phone FOR type in (HOME AS 1, OFFICE AS 2, MOBILE AS 3) ) /
这里是把不同的列转换成不同的type的数值。
再用SCOTT用户里的EMP表做个例子,列出各部门之间工资总和:
SELECT * FROM ( (SELECT sal, deptno FROM emp)
PIVOT ( SUM(sal) FOR deptno IN (10 as dept_10, 20 as dept_20, 30 as dept_30) ) ) /
DEPT_10 DEPT_20 DEPT_30 ---------- ---------- ---------- 8750 10875 9400
2012-11-29 22:51:21 我自己的测试

注意:建表插入的时候varchar字符型必须要加上'',
insert into s1 values('yuan','english',80);
SELECT
*
FROM
s1
PIVOT (
MAX
(score)
for
subject
IN
(
'chinese'
chinese ,
'math'
math ,
'english'
english ) )
|
注意这里max的是分数,in的是subject

返回来
SELECT * FROM ( SELECT * FROM s1 PIVOT ( MAX(score) for subject IN( 'chinese' chinese , 'math' math , 'english' english ) ) ) UNPIVOT ( score FOR subject IN ( chinese , math , english ) )
注意这里 最后一句的in chinese 之类,chinese不需要加''

select *
from (select hosp_wid,
hosp_prop_wid,
hosp_prop_val
from tr_hosp_ext
where hosp_prop_val in
('HOSP_LEVEL',
'HOSP_CLASS'
) )
pivot(sum(hosp_prop_wid) as wid
for hosp_prop_val in
('HOSP_LEVEL' as HOSP_LEVEL,
'HOSP_CLASS' as HOSP_CLASS)
)

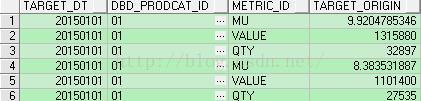
select *
from (select /*+ use_hash(r,p) */
r.target_dt,
r.dbd_prodcat_id,
p.target_price * r.qty_origin as value,
r.qty_origin as qty,
p.mu_rate * r.qty_origin as mu
from tt_dbd_target_retail_orig r
left join tt_dbd_prod_tgt_price p
on r.dbd_prodcat_id = p.dbd_prodcat_id
and r.area_id = p.area_id
and r.target_dt = p.stats_dt
where r.target_dt =20150101 )
unpivot(target_origin for metric_id in(mu as 'MU', value as 'VALUE', qty as 'QTY' ))
elect *
from (select /*+ use_hash(ex,pp) */
ex.hosp_wid, pp.prop_type, /*pp.row_wid prop_wid,*/pp.prop_name
from tr_hosp_ext ex, td_prop pp
where ex.hosp_prop_val = pp.prop_type
and ex.hosp_prop_desc = pp.prop_id
and ex.hosp_wid=9248073
and ex.lang_id='en' and pp.lang_id='en'
and hosp_prop_val in
('HOSP_LEVEL', 'HOSP_CLASS', 'HOSP_MKT'))
/* pivot(sum(prop_wid) as wid for(prop_type) in ('HOSP_LEVEL' as HOSP_LEVEL, 'HOSP_CLASS' as HOSP_CLASS, 'HOSP_MKT' as HOSP_MKT, 'NOVOMIX50_HOSP' as NOVOMIX50_HOSP, 'VICTOZA_HOSP' as VICTOZA_HOSP, 'MATERNITY_TYPE' as MATERNITY_TYPE, 'DDD_FLG' as DDD_FLG, 'EM_FLG' as EM_FLG, 'COUNTY_EN_TYPE' as COUNTY_EN_TYPE))*/
pivot(MAX(prop_name) as name for(prop_type) in ( 'HOSP_LEVEL' as HOSP_LEVEL,
'HOSP_CLASS' as HOSP_CLASS,
'HOSP_MKT' as HOSP_MKT,
))















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









