







laravel 初探 数据填充
laravel数据填充
laravel数据填充 在开发初期数据填充是一个非常有用的功能,可以在开发初期没有数据量的时候进行批量数据填充,便于测试
简介
进入laravel目录,所有填充类都在 database/seeds 目录 ,在新的laravel项目中会有一个基础的填充类文件 DatebaseSeeder.php
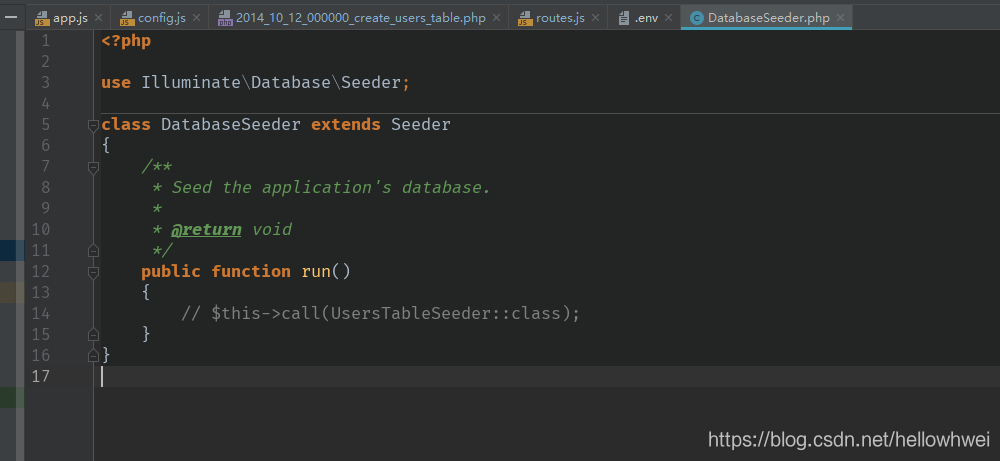
编写填充器文件
你可以用artisan命令创建自定义的填充类文件
php artisan make:seeder UsersTableSeeder
生成的文件位于 database/seeds 中
在run方法中编写数据库填充代码
public function run()
{
DB::table('users')->insert([
'name' => Str::random(10),
'email' => Str::random(10).'@gmail.com'
'password' => bcrypt('123456'),
]);
}
运行填充器
php artisan db:seed默认运行 DatabaseSeeder类
也可以--class来指定运行的指定的填充器
php artisan db:seed --class=UsersTableSeeder














 886
886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









