









rachelcrc写在最前面:
下面是转载别人的,但里面有一些我认为不太对的地方:
其实文章里写的对迅雷下载这部分是不太对的,转载的文章我没修改,在评论补充一下:
1.稀疏文件是文件系统提供的一种用时分配空间的机制,适合某些特殊的使用场景,比如vm disk image
2.不适合下载场景,下载需要预先抢占空间,用的是fallocate系列接口
3.某些场景需要预先申请一块大空间,然后用自己的元数据管理,实际上大多数情况下只会用很小一部分,这就是稀疏文件的使用场景
4.下载是实打实的要用那么多,不适合用稀疏文件,要不然下载过程中有没空间的风险
==============================================================================================
from:http://www.topjishu.com/8277.html
From:http://blog.csdn.net/clamercoder/article/details/38361815
1、Linux文件空洞与稀疏文件
2、文件系统数据存储
3、文件系统调试
文件空洞
- 在UNIX文件操作中,文件位移量可以大于文件的当前长度
在这种情况下,对该文件的下一次写将延长该文件,并在文件中构成一个空洞。位于文件中但没有写过的字节
都被设为 0。 - 如果 offset 比文件的当前长度更大,下一个写操作就会把文件“撑大(extend)”
在文件里创造“空洞(hole)”。
没有被实际写入文件的所有字节由重复的 0 表示。空洞是否占用硬盘空间是由文件系统(file system)决定
的

稀疏文件(Sparse File)
- 稀疏文件与其他普通文件基本相同,区别在于文件中的部分数据是全0,且这部分数据不占用磁盘
空间。
下面是稀疏文件的创建与查看
[root@localhost ~]# dd if=/dev/zeroof=sparse-file bs=1 count=1 seek=1024k
[root@localhost ~]# ls -l sparse-file
-rw-r--r-- 1 root root 1048577 Oct 15 17:50 sparse-file
[root@localhost ~]# du -sh sparse-file
8.0K sparse-file
[root@localhost ~]# cat anaconda-ks.cfg >> sparse-file
[root@localhost ~]# du -sh sparse-file
12K sparse-file
[root@localhost ~]# du -sh anaconda-ks.cfg
12K anaconda-ks.cfg
[root@localhost ~]#Linux文件系统inode数据块存储
索引节点采用了多重索引结构,主要体现在直接指针和3个间接指针。直接指针包含12个直接指
针块,它们直接指向包含文件数据的数据块,紧接在后面的3个间接指针是为了适应文件的大小
变化而设计。

Linux稀疏文件inode数据块存储
文件系统存储稀疏文件时,inode索引节点中,只给出实际占用磁盘空间的Block 号,
数据全零且不占用磁盘空间的文件Block并没有物理磁盘Block号。

Linux稀疏文件inode数据块存储
- 文件空洞部分不占用磁盘空间
- 文件所占用的磁盘空间仍然是连续的

实例:
[root@localhost mnt]# du -sh sparse-file
20K sparse-file
[root@localhost mnt]# ls -lh sparse-file
-rw-r--r-- 1 root root 1.1G Oct 15 10:36 sparse-file
[root@localhost mnt]#
debugfs: stat sparse-file
Inode: 49153 Type: regular Mode: 0644 Flags:
0x0 Generation: 3068382963
User: 0 Group: 0 Size: 1073742848
File ACL: 0 Directory ACL: 0
Links: 1 Blockcount: 40
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x507b76af -- Mon Oct 15 10:36:31 2012
atime: 0x507b765f -- Mon Oct 15 10:35:11 2012
mtime: 0x507b76af -- Mon Oct 15 10:36:31 2012
BLOCKS:
(IND):106496, (256):106497, (DIND):106504,
(IND):106505, (262144):106506
TOTAL: 5Linux文件系统数据块存储多重索引
- Linux文件系统数据存放采用inode多
重索引结构,有直接指针和3个间接指
针。
类似于编程中的变量定义:
unsigned long blk;
unsigned long *blk;
unsigned long **blk;
unsigned long ***blk; - 直接指针直接指向保存数据的Block
号。 - 一级指针指向一个Block,该Block中
的数据是Block指针,指向真正保存数
据的Block。
二级三级指针以此类推。

- 前12个直接指针,直接指向存储的数据区域
如Blocks大小为4096,则前12个直接指针就可以保存48KB文件。 - 一级指针可存储文件大小计算
假设每个指针占用4个字节,则一级指针指向的Block可保存4096/4个
指针,可指向1024个Blocks。一级指针可存储文件数据大小为1024*4096 =
4MB。 - 二级指针可存储文件大小计算
同样按照Blocks大小为4096,则二级指针可保存的Block指针数量为(4096/4) *
(4096/4) = 1024*1024。则二级指针可保存的文件数量大小为(1024*1024)*4096
= 4GB。 - 三级指针可存储文件大小计算
以一级、二级指针计算方法类推,三级指针可存储的文件数据大小为
(1024*1024*1024)*4096 = 4TB。

1.什么是空洞文件?
“在UNIX文件操作中,文件位移量可以大于文件的当前长度,在这种情况下,对该文件的下一次写将延长该文件,并在文件中构成一个空洞,这一点是允许的。位于文件中但没有写过的字节都被设为 0。” --摘自“百度百科”
从上面的描述可以将空洞文件的特点表述为:offset > 实际文件大小。那这又有什么表现和意义呢?我们下面慢慢分析。
( http://blog.csdn.net/shenlanzifa/article/details/44016537 )
文件空洞
我们知道lseek()系统调用可以改变文件的偏移量,但如果程序调用使得文件偏移量跨越了文件结尾,然后再执行I/O操作,将会发生什么情况? read()调用将会返回0,表示文件结尾。令人惊讶的是,write()函数可以在文件结尾后的任意位置写入数据。在这种情况下,对该文件的下一次写将延长该文件,并在文件中构成一个空洞,这一点是允许的。从原来的文件结尾到新写入数据间的这段空间被成为文件空洞。调用write后文件结尾的位置已经发生变化。
在Linux系统之中,文件结束符EOF根本不是一个字符,而是当系统读取到文件结尾,所返回的一个信号值(也就是-1),至于系统怎么知道文件的结尾,资料上说是通过比较文件的长度。
文件空洞占用任何磁盘空间,直到后续某个时点,在文件空洞中写入了数据,文件系统才会为之分配磁盘块。空洞的存在意味着一个文件名义上的大小可能要比其占用的磁盘存储总量要大(有时大出许多)。向文件空洞中写入字节,内核需要为其分配存储单元,即使文件大小不变,系统的可用磁盘空间也将减少。这种情况并不常见,但也需要了解。
下面看一个例子:(转自http://blog.csdn.net/wangxiaoqin00007/article/details/6617801)
ls -l file 查看文件逻辑大小 ( 即文件的实际大小 )
du -c file 查看文件实际占用的存储块多少 (即文件实际占用的磁盘空间大小)
od -c file 查看文件存储的内容 (od命令:http://blog.csdn.net/freeking101/article/details/78182731)
空洞文件就是有空洞的文件,在日常的常识中,我们使用的文件存放在硬盘分区上的时候,有多大的内容就会占用多大的空间,比如这个文本文件里面写有1000个asc字符,那么就会占用磁盘上1000B的存储空间,为了便于管理文件,文件系统都是按块大小来分配给文件的,假如这个文件系统一个块是4096的话,那么这个文件就会占用一个块的,无论实际的内容是1B还是4000B.如果我们有一个4MB的文件,那么它会在分区中占用:4MB/4096B=1000个块.
现在我们先做一个实际的无空洞文件来看看:
#dd if=/dev/urandom of=testfile1 bs=4096 count=1000
这个命令会从/dev/urandom文件复制1000个块,每块大小4096,到testfile1文件去.
好了,我们已经有了testfile1这么一个4M的文件了,里面填充了一些随机的内容,你可以more一下.
然后用ls -l查看这个文件的大小是4096000,用du -h testfile1来查看的话,文件占用的磁盘大小是4M,两者是一样的.
下来是我们的重点,空洞文件,假如我们有一个文件,它有4M的大小,但是它里边很大一部分都是没有存放数据的,这样可不可以呢?试一下:
#dd if=/dev/urandom of=testfile2 bs=4096 seek=999 count=1
这个命令跟前一个命令相似,不同的是,它其实复制了1个块的内容,前面的999个块都跳过了.
我们ls -l一下,发现文件的大小还是4096000,用du -h testfile2查看,占用的块大小是4K
我们发现,虽然文件是4M,但是实际在磁盘上只占用了4K的大小,这就是空洞文件的神奇之处.
实际中的空洞文件会在哪里用到呢?常见的场景有两个:
一是在下载电影的时候,发现刚开始下载,文件的大小就已经到几百M了.
二是在创建虚拟机的磁盘镜像的时候,你创建了一个100G的磁盘镜像,但是其实装起来系统之后,开始也不过只占用了3,4G的磁盘空间,如果一开始把100G都分配出去的话,无疑是很大的浪费.
然后讲一下底层的实现吧,其实这个功能关键得文件系统支持,貌似FAT就不可以吧,linux下一直都很好的支持这一特性,我们举个最简单的ext的例子吧,ext中记录文件实际内容的对应信息的东东是一个叫索引表的东西,里面有十几个条目,每个条目存放对应文件内容块的块号,这样就可以顺序找到对应的文件内容了,大家可能说,几M的一个文件,十几个项哪够啊,不必担心,一般索引表前面几个项目是直接指向文件内容的,如果这几个不够的话,往后的第一个项目不会指向文件内容块,而会指向一个存放项目的块,这样一下多出N个项目来,如果这样还不够,下面的那个是存放指向指向的项目,不好意思,我也绕晕了,总之,前面的是直接指向,下面这个是二级指向,再下面的是二级指向,以此类推,这样,文件系统就可以处理T数量级别的文件,看下图: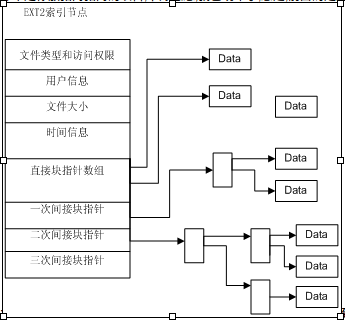
到了空洞文件这里呢,我们只需要把指向没有文件内容部分的索引项目置NULL就好了,这样就不会指向实际的数据块了,也不会占用磁盘空间了,就这么easy~
至于btrfs这些新一代文件系统呢,在空洞文件这里的原理跟ext还是类似的.
最后介绍一下linux对空洞文件的处理,经过我最近的一些测试所得:
在同一文件系统ext4下,cat一个空洞文件到新文件,新文件不再是空洞文件,cp一个空洞文件到新文件,新文件仍然是空洞文件.
在btrfs跟ext4之间做的结果同上面是一致的,但是在不同文件系统之间cp,因为不同文件系统分配的最小单元不同,所以du结果会不同.
在nfs的客户端下,在nfs目录下去cp,新文件仍然是空洞文件!!!但是cp会逐个的去比较文件的内容,所以,受网络状况搞得影响,过程有时候会很慢.
2.怎么获得一个空洞文件?
在linux下,利用lseek人为的修改offset可以获得一个空洞文件。
[cpp] view plain copy
- #include <stdio.h>
- #include <stdlib.h>
- #include <unistd.h>
- #include <sys/stat.h>
- #include <sys/types.h>
- #include <fcntl.h>
- #include <string.h>
- #define OFFSET_LENGTH 15000
- char buff1[] = "abcdefg";
- char buff2[] = "ABCDEFG";
- int
- main(int argc,char** argv)
- {
- int fd = 0;
- int buff1Length = strlen(buff1);
- int buff2Length = strlen(buff2);
- char* buff3 = (char*)malloc(buff1Length + buff2Length + OFFSET_LENGTH);
- memset(buff3,2,buff1Length + buff2Length + OFFSET_LENGTH);
- //create hole file
- if((fd = creat("./hole.f",S_IREAD|S_IWRITE)) < 0)
- {
- perror("create file error!");
- }
- printf("fd:%d\n",fd);
- if(write(fd,buff1,buff1Length) != buff1Length)
- {
- perror("write error!");
- }
- if(lseek(fd,OFFSET_LENGTH,SEEK_CUR) == -1)
- {
- perror("lseek error!");
- }
- if(write(fd,buff2,buff2Length) != buff2Length)
- {
- perror("write error!");
- }
- //create nohole file
- if((fd = creat("./nohole.f",S_IREAD|S_IWRITE)) < 0)
- {
- perror("create file error!");
- }
- if(write(fd,buff3,strlen(buff3)) != strlen(buff3))
- {
- perror("write error!");
- }
- free(buff3);
- return 0;
- }
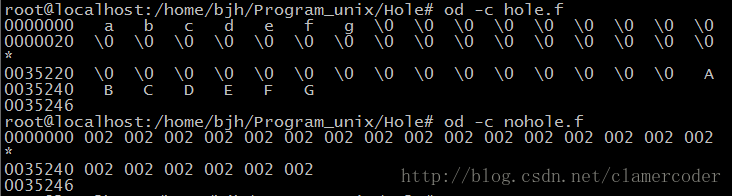
上面的程序创建了一个空洞文件和一个同样大小的非空洞文件,接下来我们将以这两个文件作为基础进行空洞文件的分析。
3.空洞文件的表现
空洞文件特点就是offset大于实际大小,也就是说一个文件的两头有数据而中间为空,以‘\0‘填充。那文件系统会不会不做任何处理的将其存放在硬盘上呢?答案是否定的,文件系统没有傻到这种程度,因为这实际是中浪费,也是一种威胁,因为一旦黑客利用这个漏洞不断侵蚀磁盘资源,计算机就崩溃了。所以说,文件系统肯定会做相应的处理,下面我就来验证一下。
用ls来展现两个文件:

我们在用du来展现两个文件(du命令用于报告文件所使用的磁盘空间总量):

可以看到,用ls展现的空洞和非空洞的大小完全相同,而用du命令展现的则有差别,一个占用了8个1024的字节块,而一个占用了16个1024的字节块。这里有个问题,文件大小为15014,算下来最多就15个block,为什么是16个呢?在《APUE》中有这样的解释:"文件系统使用了若干块以存放指向实际数据块的各个指针"。
为什么会这样呢?原因是ls展现的文件的逻辑大小,也就是文件在文件系统表现出来的大小,而du展现的是文件物理大小,也就是文件在磁盘上实际所占的block数。所以说,空洞文件在文件系统表现的还是和普通文件一样的,但是实际上文件系统并没有给他分配所表现出来的那么多空间,只是存放了有用的信息。
接下俩我们再来看一个现象:
首先我们用cat来输出空洞文件中内容,然后重定向到一个新的文件中:

我们再来用cp去复制一个文件:

可以看到,用cat得到的文件,文件实际占用的block增加了,而cp的没有。那是因为cat在复制空洞文件时会将空洞补齐,将空洞填以0,因为cat命令就是简单的read和write的操作,read在遇到空洞时读出0,write则写入0,这时文件就变成了非空洞文件,而cp在复制文件时不会,cp命令会去判断文件是否有空洞,如果有,则会调用lseek进行空洞的模拟,所以还是会保持和源文件的一致性。
4.空洞文件有什么用?
空洞文件作用很大,例如迅雷下载文件,在未下载完成时就已经占据了全部文件大小的空间,这时候就是空洞文件。下载时如果没有空洞文件,多线程下载时文件就都只能从一个地方写入,这就不是多线程了。如果有了空洞文件,可以从不同的地址写入,就完成了多线程的优势任务。
感觉这并不是空洞文件的全部作用,后续将进行补充。。。。














 866
866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









