







1.2 Spark大数据处理框架
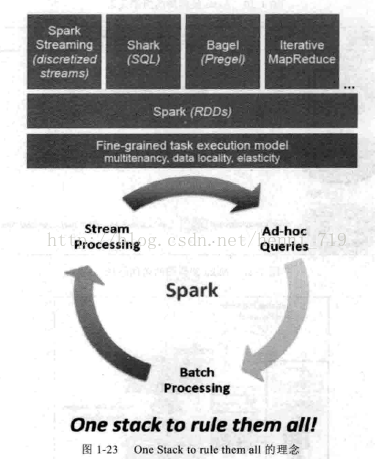
Spark作为一个通用的大数据计算平台,基于"One Stack to rule them all"的理念成功成为了一体化、多元化的大数据处理平台,轻松应对大数据处理中的实时流计算、SQL交互式查询、机器学习和图计算等,如图1-23所示:
1.2.1 Spark速度为何如此快
1. 统一的RDD抽象和操作
Spark速度快的一个核心原因就是统一的RDD抽象,基于该抽象,使得Spark的框架可轻而易举地使用Spark Core中所有的内容,并且各个框架可以在内存中无缝地集成和完成系统任务。基于统一的技术堆栈,Spark目前已经成为大数据通用计算平台。
2. 基于内存的迭代式计算
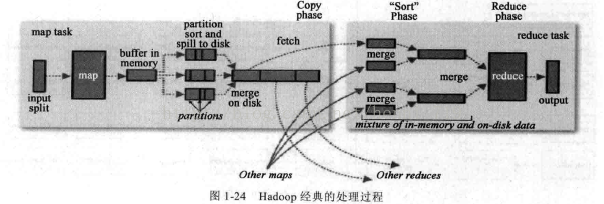
Hadoop经典的处理过程,如图1-24所示:
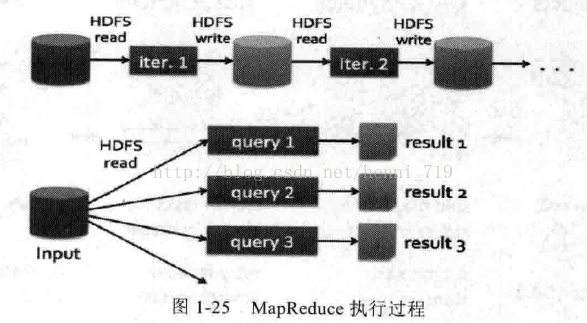
MapReduce在每次执行时都要从磁盘读数据,计算完毕后都要把数据存放在磁盘上,如图1-25所示:
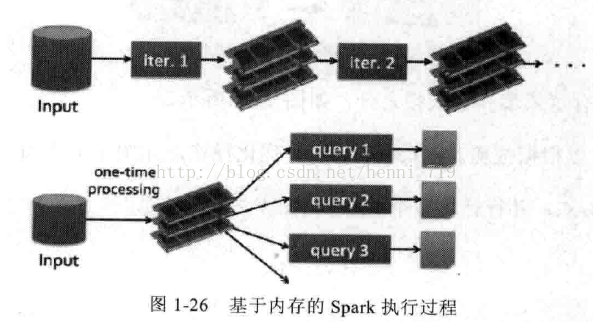
而Spark是基于内存的,执行过程如图1-26所示:
3. DAG(有向无环图)
DAG也是Spark速度快的极为重要的原因,图1-27是一张DAG图示例:
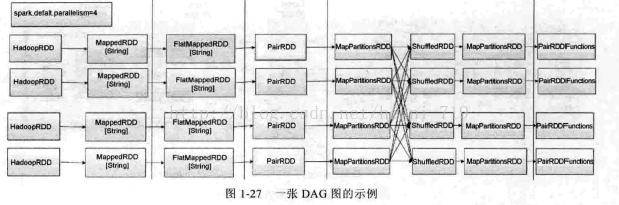
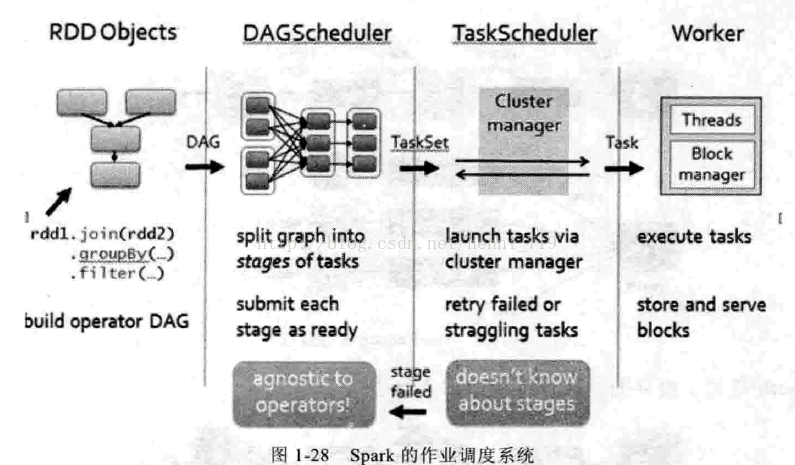
基于DAG,Spark具备非常精致的作业调度系统,如图1-28所示:
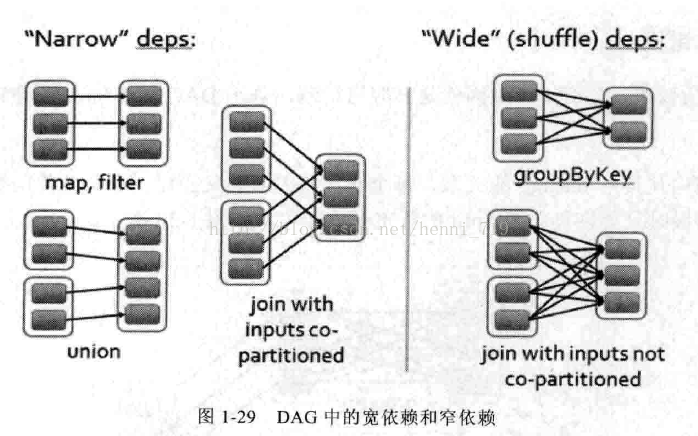
DAG中的依赖有宽依赖和窄依赖之分,如图1-29所示:
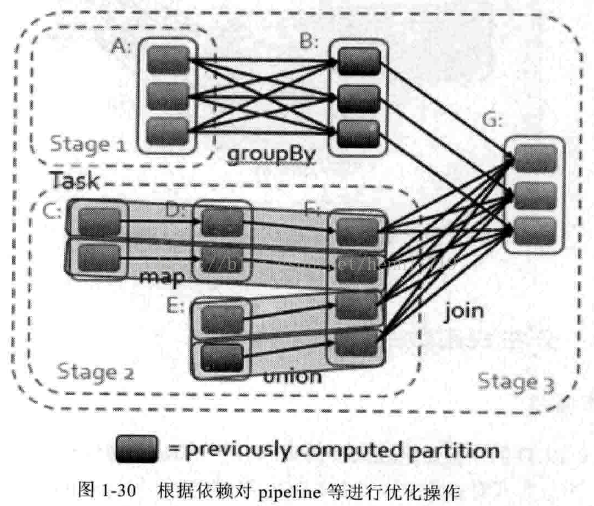
在DAG图中可以根据依赖对pipeline等进行优化操作,如图1-30所示:
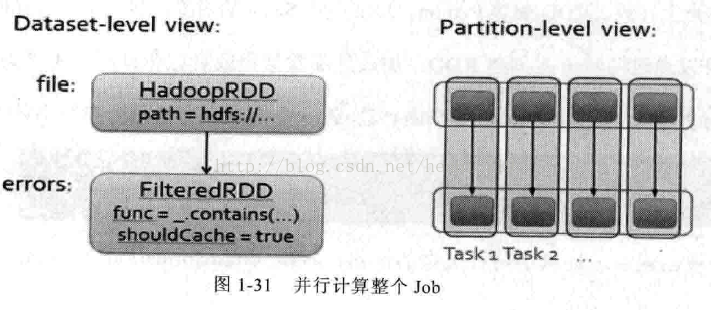
基于RDD和DAG,并行计算整个Job,如果1-31所示:
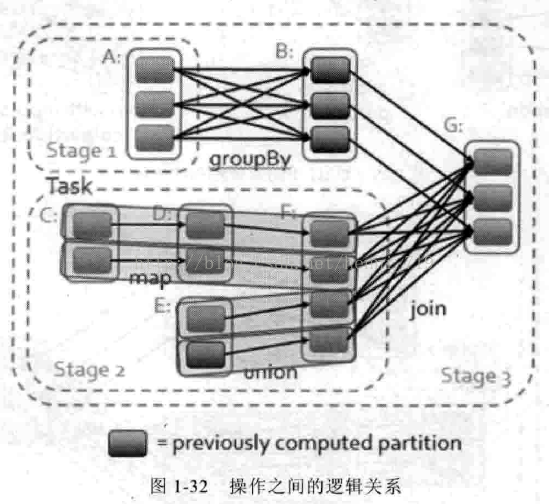
4. 出色的容错机制
Spark快的另一个原因是其容错机制,基于DAG图,lineage是轻量级且高效的。操作之间相互具备lineage的关系,每个操作只关系其父操作,各个分片的数据之间互不影响,出现错误时只要恢复单个Split的特定部分即可,如图1-32所示:















 517
517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











