






Python 有一个内置的 string 类叫做 “str”,该类包含很多方便的特性(还有一个更老的模块叫 “string”,不过我们不会用到它)。String 常量可以被双引号或者单引号包起来,不过通常会使用单引号。反斜线转义符后面带单引号和双引号表示他们的常量——如 \n \’ \”。一个被双引号包住的 String 常量里面可以出现单引号,同样地,单引号也可以包含双引号。一个 String 常量可以跨越多行,但是必须在每行的结尾用反斜线 \ 将本行与新的一行隔开。包含在三引号的 String 常量,”“” 或者 ”’,可以包括多行的文本。
Python 的字符串是“不可改变的”,这意味着字符串被创建之后,就不可以更改(Java 的字符串也使用了这种不可改变的规则)。由于字符串不可以改变,我们构造*新的*字符串,使得我们可以表示计算得到的值。所以举个例子,对于表达式(’hello’ + ‘there’),接收 2 个字符串 ‘hello’ 和 ‘there’,构建了一个新的字符串 ‘hellothere’。
使用标准的 [] 语法可以访问一个字符串里面的字符,并且像 Java 和 C++ 一样,Python 也使用零基索引,所以如果一个 str 是 ‘hello’,那么 str[1] 就是 ‘e’。如果索引超出了字符串的边界,那么 Python 会报错。如果不知道要做什么,那么 Python(不同于 Perl)会停止,而不是提供一个默认值。便利的“切片”语法(下面会介绍)可以从一个字符串中提取出一些子字符串。len(string) 函数返回一个字符串的长度。事实上,[] 语法和 len() 函数可以用于任何序列类型——strings、lists等。Python 尝试在不同的类型间,可以一致地使用运算操作。Python 菜鸟会明白:不要使用 “len” 作为变量名,从而避免无法使用 len() 函数。’+’ 运算符可以连接两个字符串。注意到下面的变量并不需要预先声明,只需要赋值然后就可以使用了。
s = 'hi'
print s[1] ## i
print len(s) ## 2
print s + ' there' ## hi there不同于 Java,‘+’ 不会自动地将数字或者其它类型转换成字符串格式。而由于 str() 函数可以将数值转换成字符串格式,所以它们可以被组合成其它字符串。
pi = 3.14
##text = 'The value of pi is ' + pi ## NO, does not work
text = 'The value of pi is ' + str(pi) ## yes对于数字,标准的运算符,+,/,* 都能以通常的方式工作。没有 ++ 运算符,但是有 +=,-= 等。如果你想要整除,那么最正确的做法是使用 2 个斜杠——如 6 // 5 是 1。
“print” 操作符打印一个或多个 python 项目并且换行(在项目后面保留逗号可以阻止换行)。在字符串常量前面加 ‘r’ 就成了一个 “raw” 字符串常量,它里面的所有字符都不会被反斜杠转义,所以 r’x\nx’ 表示长度为 4 的字符串 ‘x\nx’。’u’ 前缀则表示后面跟的是 unicode 字符串常量(Python 还有很多其它的 unicode 支持特性——下面的内容将会介绍)。
raw = r'this\t\n and that'
print raw ## this\t\n and that
multi = """It was the best of times.
It was the worst of times."""String 方法
一个方法就像一个函数,但是方法是运行在对象上。如果变量 s 是一个字符串,那么代码 s.lower() 表示在字符串对象 s 上运行 lower() 方法并且返回结果(在一个对象上运行方法的思想是组成面向对象程序设计,OOP,的基本思想)。下面是最常用的 string 方法:
s.lower(),s.upper() —— 返回字符串的小写或者大写
s.strip() —— 将字符串开头和结尾的空格都删除,然后返回得到的新字符串
s.isalpha()/s.isdigit()/s.isspace()… —— 测试字符串里面所有的字符是否在各种不同的类中
s.startswith(‘other’), s.endswith(‘other’) —— 测试字符串是否以给定的 other 字符串开头或者结尾
s.find(‘other’) —— 在 s 中查找给定的 other 字符串(不是一个正则表达式),并且如果 s 存在 other 字符串,那么返回第一个出现该字符串的首字母索引。如果不存在需要查找的字符串,则返回 -1。
s.replace(‘old’, ‘new’) —— 将 s 字符串所有出现的 ‘old’ 替换成 ‘new’,并返回得到的新字符串
s.split(‘delim’) —— 返回一个以给定分隔符分离出来的子字符串组成的列表。分隔符不是一个正则表达式,它仅仅是文本。’aaa,bbb,ccc’.split(‘,’) -> [‘aaa’, ‘bbb’, ‘ccc’]。一个方便的方法:s.split()(没有参数)可以以空格字符将字符串分离开来。
s.join(list) —— 与 split() 相反,通过使用分隔符字符串将给定的列表里的元素组合成新的字符串。例如,’—’.join([‘aaa’, ‘bbb’, ‘ccc’]) -> aaa—bbb—ccc
在 Google 上搜索 “python str” 可以得到包含所有字符串方法的官网 python.org 字符串方法。
Python 没有单独的字符类型。而是使用类似 s[8] 这样的表达式返回包含字符的长度为 1 的字符串。对于长度为 1 的字符串,==, <=, …这些运算符都可以使用,所以大部分情况下,你不需要一个单独标量 “char” 类型。
String Slices
“slice” 语法是一种便利的用于分割序列的方法——通常用于 string 和 list。s[start:end] 表示以 start 开始直到 end 但不包括 end 的元素。假设 s = “Hello”。
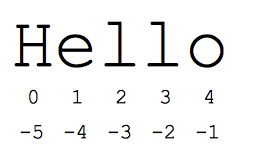
s[1:4] 是 ‘ell’ —— 索引为 1 到但不包括索引为 4 的字符
s[1:] 是 ‘ello’ —— 省略某个索引,默认到开始或者结尾的字符串
s[:] 是 ‘Hello’ —— 省略两个索引通常会得到整个东西的拷贝(这是 Python 的方式来复制一个像 string 或者 list 的序列)
s[1:100] 是 ‘ello’ —— 索引太大的话,该索引会被截断到字符串的长度
标准的零基索引数字使得我们可以很容易在字符串开始的附近访问字符。作为替代方案,Python 使用负数来方便地访问字符串末尾的字符:s[-1] 是最后一个字符 ‘o’,s[-2] 是最后字符旁边的 ‘l’,以此类推。负数索引从字符串的末尾开始计数:
s[-1] 是 ‘o’ —— 最后一个字符(倒数第一个字符)
s[-4] 是 ‘e’ —— 倒数第四个字符
s[:-3] 是 ‘He’ —— 从第一个字符到但不包括倒数第三个字符
s[-3:] 是 ‘llo’ —— 从倒数第三个字符开始,一直到字符串的末尾。
对于任意索引 n,一个关于 slice 的真理是:s[:n] + s[n:] == s。这甚至对于 n 是负数或者超出边界都是适用的。或者说,s[:n] 和 s[n:] 总是可以把一个字符串分成两部分,保存着所有字符。在以后讨论到关于 list 的章节,slice 对于 list 也适用。
String %
Python 有一个类似 printf() 的机制将一些东西组合成一个字符串。% 运算符和一个 printf 类型格式的字符串放在左边(%d int, %s string, %f/%g floating point),元组里面相匹配的值放在右边(一个元组由以逗号分隔开的值组成,通常被小括号包住):
# % operator
text = "%d little pigs come out or I'll %s and %s and %s" % (3, 'huff', 'puff', 'blow down')上面一行有点长——假设你想要将它分成单独的几行。你不能像其它语言一样仅仅在 ‘%’ 后面分行,因为 Python 默认把每一行当成一个独立的语句(从好的方面想,这是为什么我们不需要在每行最后输入分号的原因)。为了解决这个问题,将整个表达式包进一个小括号中——然后表达式就可以跨越多行了。这种跨越多行代码的方法对于后面详细介绍的各种不同的分组构造都适用:(), [], {}。
# add parens to make the long-line work:
text = ("%d little pigs come out or I'll %s and %s and %s" %
(3, 'huff', 'puff', 'blow down'))i18n Strings (Unicode)
常规的 Python 字符串不是 unicode,它们只是普通的字节。我们通过在字符串常量前面加上 ‘u’ 前缀来创建 unicode 字符串:
> ustring = u'A unicode \u018e string \xf1'
> ustring
u'A unicode \u018e string \xf1'一个 unicode string 是不同于常规 “str” string 的对象类型,但是 unicode string 是兼容的(它们共享共同的超级类 “basestring”),并且即使传进的是 unicode string 而不是常规的 string,类似正则表达式等各种不同的库同样可以正确地工作。
使用如 ‘utf-8’ 的编码将 unicode string 转换成字节,即 unicode string 调用 ustring.encode(‘utf-8’) 方法。相反的,unicode(s, encoding) 函数将普通的字节转换成一个 unicode string:
## (ustring from above contains a unicode string)
> s = ustring.encode('utf-8')
> s
'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding
> t = unicode(s, 'utf-8') ## Convert bytes back to a unicode string
> t == ustring ## It's the same as the original, yay!
True内置的 print 没有完美支持 unicode string。你可以首先调用 encode() 将 unicode string 编码成 utf-8 或者其它编码方式,然后再打印出来。在读取文件的章节,有一个例子会介绍如何用一些编码方式打开一个文本文件并且读出 unicode strings。Note that unicode handling is one area where Python 3000 is significantly cleaned up vs. Python 2.x behavior described here.
If 语句
Python 不需要用 {} 将 if/loops/function 这样的代码块包括起来。相反,Python 使用冒号 (:) 和缩进/空格来把语句分组。if 语句的布尔检验不需要放在小括号内(与 C++/Java 很大的不同),它有 elif 和 else 子句(帮助记忆:单词 “elif” 与 “else” 的长度是一样的)。
if 检验可以使用任何值。”zero” 值都可以当做是 flase: None, 0, empty string, empty list, empty dictionary。一个布尔类型可以有两个值:True 和 False(转换成一个 int,就是 1 和 0)。Python 有常用的比较运算:==, !=, <, <=, >, >=。不同于 Java 和 C,== 被重载过,适用于 strings。布尔运算符被写成单词 and,or,not(Python 不使用 C 风格的 && || !)。下面的代码看起来有点像是一个警察让一个超速驾驶者把车靠到路边的情景——注意到每一个 then/else 语句的代码块是如何以 : 开头,如何用缩进将语句分组:
if speed >= 80:
print 'License and registration please'
if mood == 'terrible' or speed >= 100:
print 'You have the right to remain silent.'
elif mood == 'bad' or speed >= 90:
print "I'm going to have to write you a ticket."
write_ticket()
else:
print "Let's try to keep it under 80 ok?"我发现当敲写上述代码的时候,最容易犯的语法错误就是漏掉了冒号 “:”,很可能是因为对于 C++/Java,这个冒号是新的东西。还有就是不要讲布尔检验放到小括号里面——那是 C++/Java 的习惯。虽然有一些人会觉得将代码放到不同的行可读性会更好,但是如果代码比较短,你还是可以将代码放到与 “:” 同一行并且位于它后面,如下(这也适用于函数、循环等)。
if speed >= 80: print 'You are so busted'
else: print 'Have a nice day'练习:string1.py
尝试解决 google-python-exercises 中 string1.py 的问题(位于 basic/ 目录下)。















 2830
2830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









