







文章目录
0. 官方文档下载地址
https://download.csdn.net/download/herosunly/15433271
1. 取label和API序列
如何取出该数据集中每个file_id对应的label的api_sequence,其中每个fild_id包括多个api:
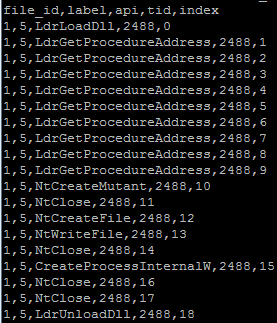
df = pd.read_csv('data.csv')
由于label后续要进行fancy indexing操作,所以我们要把label转换成np.array,而API序列后续会经过特征提取,所以表示成list of list即可。
1.1 取label
方法一删除冗余:
label = df.drop_duplicates(subset=['file_id', 'label'])['label'].values
方法二取第一个,注意pd.Series取第一个元素是用iloc方法:
label = df.groupby(['file_id'])['label'].apply(lambda x: x.iloc[0]).values
方法三去重,注意unique返回的是np.array类型:
label = df.groupby(['file_id'])['label'].apply(lambda x: x.unique()[0]).values
方法四
label = df.groupby(['file_id'])['label'].first().values
四种方法乱斗评测:

1.2 取API序列
api_seq = df.groupby(['file_id'])['api'].apply(','.join).tolist()
api_seq = df.groupby(['file_id'])['api'].apply(' '.join).tolist()
2. 对DataFrame整行/列进行操作
假设我们做的是八分类任务,提交结果为每一类的概率,想通过代码对预测的概率进行定量修改。如有一类概率大于等于0.995,则将该类概率修改为1.0,其余类别概率修改为0。
首先我们要理解axis=0和axis=1,的区别,axis=0是在行的方向上进行伸缩,而axis=1是在列的方向上进行伸缩。由于此时我们是对每一行进行操作,在每一行的作用域内,本质是是对不同即列方向上的伸缩运算,所以此时axis=1。
def process_row(row):
if row.max() >= 0.995:
row[row.argmax()] = 1
row[row.argsort().iloc[:-1]] = 0
return row
df = df.apply(process_row, axis=1)
3. 显示完整信息
import pandas as pd
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)
with pd.option_context('display.max_rows', None, 'display.max_columns', None): # more options can be specified also
print(df)
4. pd.read_csv
pd.read_csv(in_file, engine=‘python’),其中engine='python’可解决部分编码的问题。
5. groupby后如何进行处理
groupby = data.groupby('anzsic06').agg({'geo_count':['mean']})
groupby.columns = groupby.columns.droplevel(0)
groupby.rename(columns={ groupby.columns[0]: "anzsic06_mean" }, inplace = True)
6. pd.read_json() ValueError: Trailing data
在官方文档中read_json的参数lines : reads file as one json object per line。所以如果每一行都是单独的json,则添加上lines=True参数即可。
7. value_counts取其中的最大值
df.groupby([‘source_ip’])[‘domain’].apply(lambda x: x.value_counts().max()),即为每个源ip访问域名中最多域名的个数。
8. isin
Consider the isin() method of Series, which returns a boolean vector that is true wherever the Series elements exist in the passed list. This allows you to select rows where one or more columns have values you want.
df.columns[~df.columns.isin(['sum', 'total'])]
9. 更多
更多内容可参考我的专栏机器学习入门之工具篇。其中包含了对Numpy、Pandas Series、Pandas DataFrame、Scikit-learn、Pytorch、TensorFlow等工具的详细使用。
















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











