







1.前言
B树是为磁盘或其他直接存取的辅助存储设备而设计的一种平衡搜索树。B树类似于红黑树,但它们在降低磁盘I/O操作数方面要更好一些。现在许多数据库系统使用B树或者B树的变种(B+树和B*树)来存储信息。B树用的比较普遍,许多书籍、博客都有详细的介绍,对于B树的严格定义也相对统一,在这里就不予赘述。 B+树是B树的一种变形,它把所有的卫星数据都存储在叶节点中,内部节点只存放关键字和孩子指针,因此最大化了内部节点的分支因子,所以B+树的遍历也更加高效(B树需要以中序的方式遍历节点,而B+树只需把所有叶子节点串成链表就可以从头到尾遍历)。
以下先放一张我所依据的B+树的图示(这张图有所简化,下面讲完定义后会贴一张更加详细的图,两图本质并无差异):

2.定义
B+树的定义如下:
每个节点node有下面的属性: n个关键字key[1],key[2], … ,key[n],以非降序存放,使得key[1]≤key[2]≤…≤key[n];
isRoot,一个布尔值,如果node是根节点,则为TRUE;否则为FALSE;
isLeaf,一个布尔值,如果node是叶子节点,则为TRUE;否则为FALSE;
Node*类型的parent指针,指向该节点的父节点
每个内部节点还包含n个
指向其孩子children[0],children[1], … , children[n],叶子节点没有孩子。(注:此处有争议,B+树到底是与B 树n-1个关键字有n棵子树保持一致,还是B+树n个关键字的结点中含有n棵子树;两种定义都可以,只要自己实现的时候统一用一种就行。如无特殊说明,以下的都是后者:即n个关键字对应n棵子树);
内部节点的关键字对存储在各子树中的关键字范围加以分割:如果key[i]为任意一个存储在内部节点中的关键字,childNum[i]为该节点的对应下标的子树指针指向的节点的任意一个关键字,那么key[1] ≤ childNum[1] < key[2] ≤ childNum[2] < key[3] ≤ childNum[3] < … < key[n] ≤ childNum[n]
内部节点并不存储真正的信息,而是保存其叶子节点的最小值作为索引。比如下图,标注1和标注2都是内部节点,里面保存的并不是真正的信息,而是标注3所示的节点中的最小值。(注:此处有争议以最大值作为索引,同样也是不影响的争议)

任何和关键字相联系的“卫星数据(satellite information)” 将与关键字一样存放在叶子节点中,一般地,可能只是为每个关键字对应的”卫星数据”存放一个指针,指针指向存放实际数据的磁盘页,匹配了某个叶子节点的关键字即可通过该指针找到其他对应数据。
每个叶子节点还有指向下一个节点的指针next,方便遍历整棵B+树。
每个叶子节点具有相同的深度,即树的高度h。
每个节点所包含的关键字个数有上界和下界,用一个被B+树的最小度数(minmum degree)的固定整数t≥2来表示这些界: 除了根节点以外的每个节点必须至少有t个关键字。因此,除了根节点以外的每个内部节点至少有t个孩子
每个节点至多有2t个关键字,因此,一个内部节点至多可有2t个孩子。当一个节点恰好有2t个关键字时,称该节点是满的。
结合以上的具体定义,下面这张图更加详细的描述了一棵具体的B+树

a) 为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
1) B+-tree的磁盘读写代价更低
B+-tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2) B+-tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
读者点评
本文评论下第149楼,fanyy1991针对上文所说的两点,道:个人觉得这两个原因都不是主要原因。数据库索引采用B+树的主要原因是 B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
在B+树的学习与实现过程中,也遇到不少的疑惑之处,现记录如下,持续更新:
内部节点并不存储真正的信息,而是保存其叶子节点的最小值作为索引。每次插入删除都进行更新(此时用到parent指针),保持最新状态。
关于所有叶子节点都处于同一深度是如何实现的?这与B+树具体的插入和删除算法有关。简单解释一下插入时的情况,根据插入值的大小,逐步向下直到对应的叶子节点。如果叶子节点关键字个数小于2t,则直接插入值或者更新卫星数据;如果插入之前叶子节点已经满了,则分裂该叶子节点成两半,并把中间值提上到父节点的关键字中,如果这导致父节点满了的话,则把该父节点分裂,如此递归向上。所以树高是一层层的增加的,叶子节点永远都在同一深度。下面是我实现的B+树中的插入代码的片段:
public void insert(Comparable key, Object obj, BPlusTree tree)
{
// 叶子节点则插入
if (isLeaf) {
// 不需要分裂直接插入
if (containsKeyword(key) || keywords.size() < tree.getDegree()) {
insertInNotFull(key, obj);
// 直接插入
if (parent != null) {
parent.updateAfterInsert(tree); // 更新父节点的信息(将最小的值存到父节点的关键字中作为索引)
}
} else { // 需要分裂成左右两个节点
splitNode(key, obj, tree);
}
} else { // 如果不是叶子节点则继续往下搜索
Node leafNode = downToLeaf(key); // 逐步向下到对应的叶子节点
leafNode.insert(key, obj, tree);
}
}3.结语
B+树还有一个最大的好处,方便扫库,B树必须用中序遍历的方法按序扫库,而B+树直接从叶子结点挨个扫一遍就完了,B+树支持range-query非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
4.总结
通过以上介绍,大致将B树,B+树,B*树总结如下:
B树:有序数组+平衡多叉树;
B+树:有序数组链表+平衡多叉树;
B*树:一棵丰满的B+树。
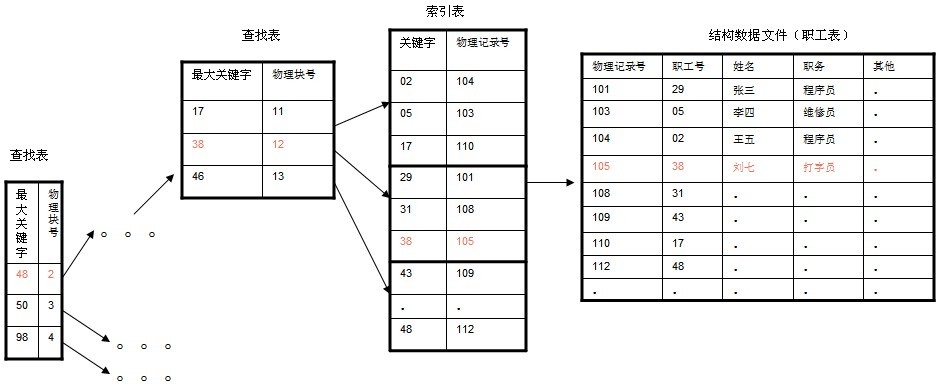
在大规模数据存储的文件系统中,B~tree系列数据结构,起着很重要的作用,对于存储不同的数据,节点相关的信息也是有所不同,这里根据自己的理解,画的一个查找以职工号为关键字,职工号为38的记录的简单示意图。(这里假设每个物理块容纳3个索引,磁盘的I/O操作的基本单位是块(block),磁盘访问很费时,采用B+树有效的减少了访问磁盘的次数。)
对于像MySQL,DB2,Oracle等数据库中的索引结构得有较深入的了解才行,建议去找一些B 树相关的开源代码研究。
走进搜索引擎的作者梁斌老师针对B树、B+树给出了他的意见(为了真实性,特引用其原话,未作任何改动): “B+树还有一个最大的好处,方便扫库,B树必须用中序遍历的方法按序扫库,而B+树直接从叶子结点挨个扫一遍就完了,B+树支持range-query非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
比如要查 5-10之间的,B+树一把到5这个标记,再一把到10,然后串起来就行了,B树就非常麻烦。B树的好处,就是成功查询特别有利,因为树的高度总体要比B+树矮。不成功的情况下,B树也比B+树稍稍占一点点便宜。
B树比如你的例子中查,17的话,一把就得到结果了,
有很多基于频率的搜索是选用B树,越频繁query的结点越往根上走,前提是需要对query做统计,而且要对key做一些变化。
另外B树也好B+树也好,根或者上面几层因为被反复query,所以这几块基本都在内存中,不会出现读磁盘IO,一般已启动的时候,就会主动换入内存。”非常感谢。
Bucket Li:"mysql 底层存储是用B+树实现的,知道为什么么。内存中B+树是没有优势的,但是一到磁盘,B+树的威力就出来了"。















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









