 解决Docker启动问题
解决Docker启动问题




 本文介绍了当遇到Docker无法启动的问题时,如何排查并解决。首先检查selinux配置,然后检查系统内存使用情况,通过释放空间来解决问题。
本文介绍了当遇到Docker无法启动的问题时,如何排查并解决。首先检查selinux配置,然后检查系统内存使用情况,通过释放空间来解决问题。
1.先考虑断电对docker有什么影响?查询一番;描述为 可能是/etc/selinux/中配置文件config被改了,将 SELINUX=disabled 修改为 SELINUX=permissive 再重启服务器,但是没有解决问题;
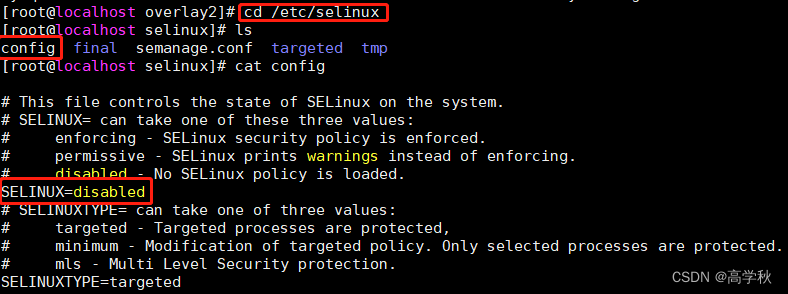
2.一直打不开,查询到可能虚拟机linux系统内存已满,导致无法启动docker;
查看了下内存占用命令:df -h ,发现 /dev/mapper/centos-root 已用内存竟然100%;
此时,可以进行删除虚拟机一些没有用的文件;
可输入以下代码,查看具体占用内存情况;
cd / && du -h -x --max-depth=1
如图所示;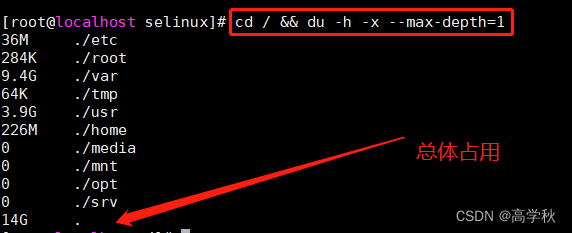
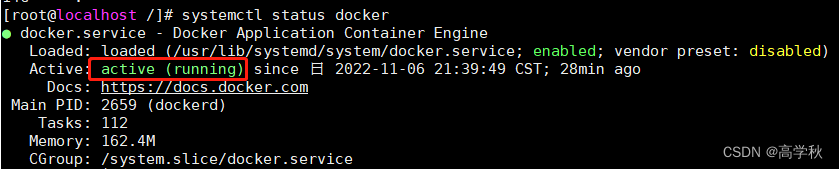
在删除某些文件后,腾出空余的空间,重启docker;输入systemctl restart docker
发现成功了

















 898
898




 到【灌水乐园】发言
到【灌水乐园】发言







