







有序类别特征

有序类别特征,故名思意,就是有相对顺序的类别特征。例如:
-
年龄段特征:"1-10,11-20,21-30,31-40"等年龄段;
-
评分特征:"high,medium,low";
有序类别特征和无序的类别特征有些许区别,例如Label编码等,如果我们直接按照原先的LabelEncoder进行转化就会丢失特征相对大小的信息,这对于梯度提升树模型会带来负向的效果,因为序列信息可能和标签有着强烈的相关性,比如回购的问题,有“high,medium,low”三种评分,用户购物之后如果给商品打了“high“,那么他大概率还会回购,但是如果打了low,那么大概率是不会回购了,传统的LabelEncoder就直接丢失了这种信息,那么相较于无序类别特征的编码,有哪些变化呢?
-
Label编码 -> 字典编码
-
One-Hot编码 -> 很少不用
-
Frequency,Target,WOE,人工编码使用方式不变。
![]()
![]()
1.有序字典编码
有序字典编码,就是将特征中的每个字段按照相对大小构建字典,再进行转化。如下所示,我们假设:'high'>'medium'>'low',然后再进行映射。
from sklearn import preprocessing
import pandas as pd
df = pd.DataFrame({'ratings':['high','medium','low']})
le = preprocessing.LabelEncoder()
le.fit(df['ratings'].values)
df['traditional_encode'] = le.transform(df['ratings'].values)
ratings_dic = {'low':0,'medium':1,'high':2}
df['selfdefined_encode'] = df['ratings'].map(ratings_dic).values
df
| ratings | traditional_encode | selfdefined_encode | |
|---|---|---|---|
| 0 | high | 0 | 2 |
| 1 | medium | 2 | 1 |
| 2 | low | 1 | 0 |
从上面简单的例子中,我们可以看出:
-
无序类别特征的编码打乱了原始的内在顺序关系,可能增大梯度提升树模型训练的难度,而我们有序字典编码的方式则最大程度的保留了所有的信息。


1.分段编码
分段聚类编码也是一种分箱的策略,它主要基于数据的相对大小并结合业务背景知识对类别特征进行分段分组重新编码。举个简单但例子,我们现在需要预测学生的幸福指数,现在有一个类别特征:
-
学籍特征:小学一年级,小学二年级,小学三年级,小学四年级,小学五年级,小学六年级,初中一年级,初中二年级,初中三年级,高中一年级,高中二年级,高中三年级,大学一年级,大学二年级,大学三年级,大学四年级
我们发现学籍特征是存在相对顺序的,也就是我们的有序类别特征;与此同时,我们知道,小学初中高中大学这几个阶段幸福的阶段都不一样,比如小学可能是小学壹年级最不开心,因为刚刚从幼儿园到一年级不适应造成;而小学初中高中大学在最后一个学年都会很不开心,因为那个时候压力最大,面临着人生的重要转折。所以这个时候,我们需要对特征进行分段编码,将学籍编码为小学,初中,高中,大学。还可以将各个不同阶段按照年级的大小进行分段,分为该阶段的高年级生,低年级生和中间年级的学生。
df = pd.DataFrame({'student_status':['小学一年级','小学二年级','小学三年级','小学四年级','小学五年级','小学六年级',\
'初中一年级','初中二年级','初中三年级','高中一年级','高中二年级','高中三年级',\
'大学一年级','大学二年级','大学三年级','大学四年级']})
le = preprocessing.LabelEncoder()
le.fit(df['student_status'].values)
df['traditional_encode'] = le.transform(df['student_status'].values)
map_dic = ['小学一年级','小学二年级','小学三年级','小学四年级','小学五年级','小学六年级',\
'初中一年级','初中二年级','初中三年级','高中一年级','高中二年级','高中三年级',\
'大学一年级','大学二年级','大学三年级','大学四年级']
map_dic = {v:i for i,v in enumerate(map_dic)}
df['selfdefined_encode'] = df['student_status'].map(map_dic).values
df
| student_status | traditional_encode | selfdefined_encode | |
|---|---|---|---|
| 0 | 小学一年级 | 7 | 0 |
| 1 | 小学二年级 | 9 | 1 |
| 2 | 小学三年级 | 8 | 2 |
| 3 | 小学四年级 | 12 | 3 |
| 4 | 小学五年级 | 10 | 4 |
| 5 | 小学六年级 | 11 | 5 |
| 6 | 初中一年级 | 0 | 6 |
| 7 | 初中二年级 | 2 | 7 |
| 8 | 初中三年级 | 1 | 8 |
| 9 | 高中一年级 | 13 | 9 |
| 10 | 高中二年级 | 15 | 10 |
| 11 | 高中三年级 | 14 | 11 |
| 12 | 大学一年级 | 3 | 12 |
| 13 | 大学二年级 | 5 | 13 |
| 14 | 大学三年级 | 4 | 14 |
| 15 | 大学四年级 | 6 | 15 |
df['student_status_1st'] = df['student_status'].map(lambda x: x[:2])
map_dic = {'小学':0, '初中':1, '高中':2, '大学':3}
df['student_status_1st'] = df['student_status_1st'].map(map_dic).values
df
| student_status | traditional_encode | selfdefined_encode | student_status_1st | |
|---|---|---|---|---|
| 0 | 小学一年级 | 7 | 0 | 0 |
| 1 | 小学二年级 | 9 | 1 | 0 |
| 2 | 小学三年级 | 8 | 2 | 0 |
| 3 | 小学四年级 | 12 | 3 | 0 |
| 4 | 小学五年级 | 10 | 4 | 0 |
| 5 | 小学六年级 | 11 | 5 | 0 |
| 6 | 初中一年级 | 0 | 6 | 1 |
| 7 | 初中二年级 | 2 | 7 | 1 |
| 8 | 初中三年级 | 1 | 8 | 1 |
| 9 | 高中一年级 | 13 | 9 | 2 |
| 10 | 高中二年级 | 15 | 10 | 2 |
| 11 | 高中三年级 | 14 | 11 | 2 |
| 12 | 大学一年级 | 3 | 12 | 3 |
| 13 | 大学二年级 | 5 | 13 | 3 |
| 14 | 大学三年级 | 4 | 14 | 3 |
| 15 | 大学四年级 | 6 | 15 | 3 |
map_dic = {'小学一年级':0,'小学二年级':0,'小学三年级':1,'小学四年级':1,'小学五年级':2,'小学六年级':2,\
'初中一年级':0,'初中二年级':1,'初中三年级':2,'高中一年级':0,'高中二年级':1,'高中三年级':2,\
'大学一年级':0,'大学二年级':1,'大学三年级':1,'大学四年级':2}
df['student_status_2nd'] = df['student_status'].map(map_dic).values
df
| student_status | traditional_encode | selfdefined_encode | student_status_1st | student_status_2nd | |
|---|---|---|---|---|---|
| 0 | 小学一年级 | 7 | 0 | 0 | 0 |
| 1 | 小学二年级 | 9 | 1 | 0 | 0 |
| 2 | 小学三年级 | 8 | 2 | 0 | 1 |
| 3 | 小学四年级 | 12 | 3 | 0 | 1 |
| 4 | 小学五年级 | 10 | 4 | 0 | 2 |
| 5 | 小学六年级 | 11 | 5 | 0 | 2 |
| 6 | 初中一年级 | 0 | 6 | 1 | 0 |
| 7 | 初中二年级 | 2 | 7 | 1 | 1 |
| 8 | 初中三年级 | 1 | 8 | 1 | 2 |
| 9 | 高中一年级 | 13 | 9 | 2 | 0 |
| 10 | 高中二年级 | 15 | 10 | 2 | 1 |
| 11 | 高中三年级 | 14 | 11 | 2 | 2 |
| 12 | 大学一年级 | 3 | 12 | 3 | 0 |
| 13 | 大学二年级 | 5 | 13 | 3 | 1 |
| 14 | 大学三年级 | 4 | 14 | 3 | 1 |
| 15 | 大学四年级 | 6 | 15 | 3 | 2 |
通过对学籍的转化,梯度提升树模型往往可以得到更好的效果。但这种特征很多时候需要有一定的业务背景才能挖掘到,不过有很多厉害但朋友也可以通过数据探索分析发现这种规律。
分段编码这种方式在数据竞赛中还是非常常见的,例如我们可以:
-
将24小时分别编码为:上午,下午,晚上;
-
将每个月分为月初,月中,月末等等;
基于转化之后的特征再与其它特征进行组合特征往往还能获得更多的提升。
3.小结
除了上面两个需要注意的情况之外,很多时候有序的类别特征在进行特征工程时和无序类别特征是类似的。
数值特征
有序类别特征在编码之后可以认为是数值特征的一种特例。所以有序类别特征转化之后所采用的各种编码技巧,在数值特征同样适用,很多朋友会好奇,例如Frequency编码难道也可以在数值特征处适用?
-
答案是:肯定的,而且很有意义。
比如说,用户消费,我们对用户的消费进行Frequency编码,发现某些数值的出现的次数特别多,例如100出现多次,该信息可能反映的就是用户经常去消费某类商品,这在没有其它额外辅助信息的情况是非常有帮助的。
其它的此处我们不再赘述。在单个数值特征模块,我们重点介绍数值特征的一些注意事项。
1.小数点之后的数值
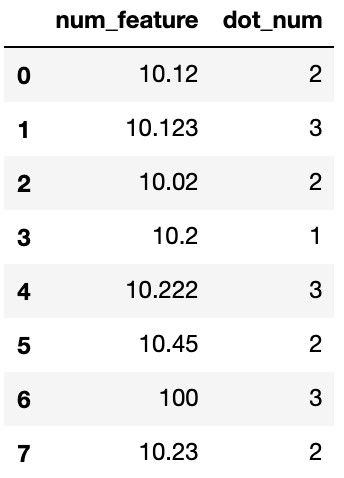
很多数值特征是带有小数点的,而小数点之后的位数有些时候也能反映诸多信息,例如我们有:
-
数值特征:10.12,10.123,10.02,10.2,10.222,10.45,100,10.23,......

这个时候,小数点之后的长度可能就潜藏一些有意思的信息,对其长度进行统计则非常有意义。
2.特殊数字
举个非常典型的案例,就是使用微信红包、微信转账等信息预测二人关系,
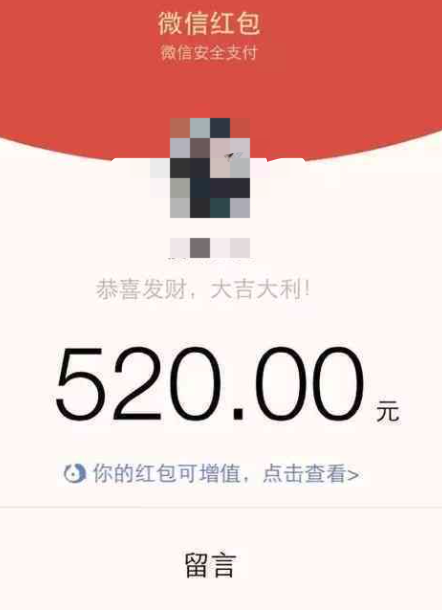

很明显,从这些特殊的数值中,我们就可以很好地预测出二人之间的关系很不一般,可能是情人,关于这些特殊数字的统计信息就能很好地反映此类信息。我们就可以单独做个二元特征来表示该笔转账是否为特殊转账。
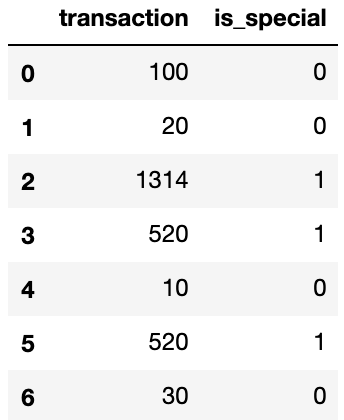
df = pd.DataFrame()
df['transaction'] = [100,20,1314,520,10,520,30]
df['is_special'] = df['transaction'].apply(lambda x: 1 if x in [520,1314] else 0)
df
| transaction | is_special | |
|---|---|---|
| 0 | 100 | 0 |
| 1 | 20 | 0 |
| 2 | 1314 | 1 |
| 3 | 520 | 1 |
| 4 | 10 | 0 |
| 5 | 520 | 1 |
| 6 | 30 | 0 |
3.数值符号
其实数值的符号一般就两个,"+"和"-",最常见的就是银行卡里面的支出和收入。
-
“+“的次数就是收入的次数;“-“的次数就是支出的信息;
这些信息一般在和用户的ID等特征进行组合使用,发挥的价值可能会更大,这样我们就可以得到用户的支出次数和收入的次数等。
4.小结
关于数值特征,可以认为是编码之后的有序类别特征的扩展,所以所有在有序类别特征使用的策略在数值特征处也可以直接使用,但是因为很多时候数值特征是非常多的,如果作为单个类别特征统计信息不是很置信,往往需要进行分箱之后再当做类别特征处理效果更佳一些。除此之外,我们需要重点关注的就是符号、小数点前后的信息、特殊的数值这三点,很多时候,数值特征和其他特征的组合往往能带来巨大的提升,这些信息我们会在后面的特征工程处进行细致的介绍。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









