







当我们在浏览器输入网址:”www.baisu.com”后浏览器最终怎样把这个页面呈现出来?这个过程大致可以分成两个部分:
1.网络通信
2.页面渲染
网络通信
互联网内各网络设备间的通信都遵循TCP/IP协议,利用TCP/IP协议族进行网络通信时,会通过分层顺序与对方进行通信。分层由高到低分别为:应用层、传输层、网络层、数据链路层。发送端从应用层往下走,接收端从数据链路层上向上走。如图所示:
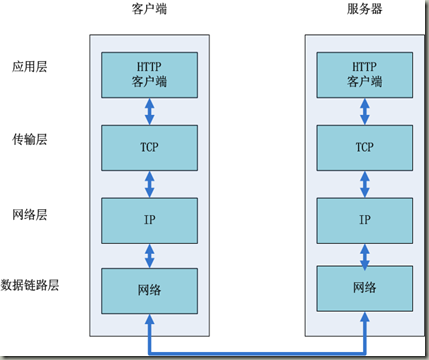
1.在浏览器中输入网址
用户输入url,例如http://www.baidu.com。其中http为协议,www.baidu.com为网络地址,及指出需要的资源在那台计算机上。一般网络地址可以为域名或IP地址,此处为域名。使用域名是为了方便记忆,但是为了让计算机理解这个地址还需要把它解析为IP地址。
2.应用层DNS解析域名
客户端先检查本地是否有对应的IP地址,若找到则返回响应的IP地址。若没找到则请求上级DNS服务器,直至找到或到根节点。
DNS的具体查找过程如下:
* 浏览器缓存 – 浏览器会缓存DNS记录一段时间。 有趣的是,操作系统没有告诉浏览器储存DNS记录的时间,这样不同浏览器会储存个自固定的一个时间(2分钟到30分钟不等)。
* 系统缓存 – 如果在浏览器缓存里没有找到需要的记录,浏览器会做一个系统调用(windows里是gethostbyname)。这样便可获得系统缓存中的记录。
* 路由器缓存 – 接着,前面的查询请求发向路由器,它一般会有自己的DNS缓存。
* ISP DNS 缓存 – 接下来要check的就是ISP缓存DNS的服务器。在这一般都能找到相应的缓存记录。
* 递归搜索 – 你的ISP的DNS服务器从跟域名服务器开始进行递归搜索,从.com顶级域名服务器到Facebook的域名服务器。一般DNS服务器的缓存中会 有.com域名服务器中的域名,所以到顶级服务器的匹配过程不是那么必要了。
*
DNS有一点令人担忧,这就是像wikipedia.org 或者 facebook.com这样的整个域名看上去只是对应一个单独的IP地址。但其实实际上存在一个域名对应许多IP地址的情况。还好,有几种方法可以消除这个瓶颈:
* 循环 DNS 是DNS查找时返回多个IP时的解决方案。举例来说,Facebook.com实际上就对应了四个IP地址。
* 负载平衡器 是以一个特定IP地址进行侦听并将网络请求转发到集群服务器上的硬件设备。 一些大型的站点一般都会使用这种昂贵的高性能负载平衡器。
* 地理 DNS 根据用户所处的地理位置,通过把域名映射到多个不同的IP地址提高可扩展性。这样不同的服务器不能够更新同步状态,但映射静态内容的话非常好。
* Anycast 是一个IP地址映射多个物理主机的路由技术。 美中不足,Anycast与TCP协议适应的不是很好,所以很少应用在那些方案中。
大多数DNS服务器使用Anycast来获得高效低延迟的DNS查找。
3.应用层客户端发送HTTP请求
HTTP请求包括请求报头和请求主体两个部分,其中请求报头包含了至关重要的信息,包括请求的方法(GET / POST)、目标url、遵循的协议(http / https / ftp…),返回的信息是否需要缓存,以及客户端是否发送cookie等。
因为像Facebook主页这样的动态页面,打开后在浏览器缓存中很快甚至马上就会过期,毫无疑问他们不能从中读取。
所以,浏览器将把一下请求发送到Facebook所在的服务器:
··
GET HTTP://facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, […]
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; […]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Host: facebook.com
Cookie: datr=1265876274-[…]; locale=en_US; lsd=WW[…]; c_user=2101[…]
GET 这个请求定义了要读取的URL: “HTTP://facebook.com/”。 浏览器自身定义 (User-Agent 头), 和它希望接受什么类型的相应 (Accept and Accept-Encoding 头). Connection头要求服务器为了后边的请求不要关闭TCP连接。
请求中也包含浏览器存储的该域名的cookies。可能你已经知道,在不同页面请求当中,cookies是与跟踪一个网站状态相匹配的键值。这样cookies会存储登录用户名,服务器分配的密码和一些用户设置等。Cookies会以文本文档形式存储在客户机里,每次请求时发送给服务器。
用来看原始HTTP请求及其相应的工具很多。作者比较喜欢使用fiddler,当然也有像FireBug这样其他的工具。这些软件在网站优 化时会帮上很大忙。
除了获取请求,还有一种是发送请求,它常在提交表单用到。发送请求通过URL传递其参数(e.g.: HTTP://robozzle.com/puzzle.aspx?id=85)。发送请求在请求正文头之后发送其参数。
像“HTTP://facebook.com/”中的斜杠是至关重要的。这种情况下,浏览器能安全的添加斜杠。而像“HTTP: //example.com/folderOrFile”这样的地址,因为浏览器不清楚folderOrFile到底是文件夹还是文件,所以不能自动添加 斜杠。这时,浏览器就不加斜杠直接访问地址,服务器会响应一个重定向,结果造成一次不必要的握手。
4.传输层TCP传输报文
位于传输层的TCP协议为传输报文提供可靠的字节流服务。它为了方便传输,将大块的数据分割成以报文段为单位的数据包进行管理,并为它们编号,方便服务器接收时能准确地还原报文信息。TCP协议通过“三次握手”等方法保证传输的安全可靠。
“三次握手”的过程是,发送端先发送一个带有SYN(synchronize)标志的数据包给接收端,在一定的延迟时间内等待接收的回复。接收端收到数据包后,传回一个带有SYN/ACK标志的数据包以示传达确认信息。接收方收到后再发送一个带有ACK标志的数据包给接收端以示握手成功。在这个过程中,如果发送端在规定延迟时间内没有收到回复则默认接收方没有收到请求,而再次发送,直到收到回复为止。

5.网络层IP协议查询MAC地址
IP协议的作用是把TCP分割好的各种数据包传送给接收方。而要保证确实能传到接收方还需要接收方的MAC地址,也就是物理地址。IP地址和MAC地址是一一对应的关系,一个网络设备的IP地址可以更换,但是MAC地址一般是固定不变的。ARP协议可以将IP地址解析成对应的MAC地址。当通信的双方不在同一个局域网时,需要多次中转才能到达最终的目标,在中转的过程中需要通过下一个中转站的MAC地址来搜索下一个中转目标。
6.数据到达链路层
在找到对方的MAC地址后,就将数据发送到数据链路层传输。这时,客户端发送请求的阶段结束
7.服务器接收数据
接收端的服务器在链路层接收到数据包,再层层向上直到应用层。这过程中包括在运输层通过TCP协议讲分段的数据包重新组成原来的HTTP请求报文。
8.服务器响应请求
服务接收到客户端发送的HTTP请求后,查找客户端请求的资源,并返回响应报文,响应报文中包括一个重要的信息——状态码。状态码由三位数字组成,其中比较常见的是200 OK表示请求成功。301表示永久重定向,即请求的资源已经永久转移到新的位置。在返回301状态码的同时,响应报文也会附带重定向的url,客户端接收到后将http请求的url做相应的改变再重新发送。404 not found 表示客户端请求的资源找不到。
以下面这个响应报文为例:
HTTP/1.1 301 Moved Permanently
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
Location: HTTP://www.facebook.com/
P3P: CP=”DSP LAW”
Pragma: no-cache
Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT;
path=/; domain=.facebook.com; httponly
Content-Type: text/html; charset=utf-8
X-Cnection: close
Date: Fri, 12 Feb 2010 05:09:51 GMT
Content-Length: 0
服务器给浏览器响应一个301永久重定向响应,这样浏览器就会访问“HTTP://www.facebook.com/” 而非“HTTP://facebook.com/”。
为什么服务器一定要重定向而不是直接发会用户想看的网页内容呢?这个问题有好多有意思的答案。
其中一个原因跟搜索引擎排名有 关。你看,如果一个页面有两个地址,就像HTTP://www.igoro.com/ 和HTTP://igoro.com/,搜索引擎会认为它们是两个网站,结果造成每一个的搜索链接都减少从而降低排名。而搜索引擎知道301永久重定向是 什么意思,这样就会把访问带www的和不带www的地址归到同一个网站排名下。
还有一个是用不同的地址会造成缓存友好性变差。当一个页面有好几个名字时,它可能会在缓存里出现好几次。
9.服务器返回相应文件
请求成功后,服务器会返回相应的HTML文件。接下来就到了页面的渲染阶段了。
二.页面渲染
现代浏览器渲染页面的过程是这样的:jiexiHTML以构建DOM树 –> 构建渲染树 –> 布局渲染树 –> 绘制渲染树。
DOM树是由HTML文件中的标签排列组成,渲染树是在DOM树中加入CSS或HTML中的style样式而形成。渲染树只包含需要显示在页面中的DOM元素,像元素或display属性值为none的元素都不在渲染树中。
在浏览器还没接收到完整的HTML文件时,它就开始渲染页面了,在遇到外部链入的脚本标签或样式标签或图片时,会再次发送HTTP请求重复上述的步骤。在收到CSS文件后会对已经渲染的页面重新渲染,加入它们应有的样式,图片文件加载完立刻显示在相应位置。在这一过程中可能会触发页面的重绘或重排。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









