







分布式ID方案有哪些以及各自的优劣势,我们当如何选择
作者介绍
段同海,就职于达达基础架构团队,主要参与达达分布式ID生成系统,日志采集系统等中间件研发工作。
背景
在分布式系统中,经常需要对大量的数据、消息、http请求等进行唯一标识,例如:在分布式系统之间http请求需要唯一标识,调用链路分析的时候需要使用这个唯一标识。这个时候数据库自增主键已经不能满足需求,需要一个能够生成全局唯一ID的系统,这个系统需要满足以下需求:
- 全局唯一:不能出现重复ID。
- 高可用:ID生成系统是基础系统,被许多关键系统调用,一旦宕机,会造成严重影响。
经典方案介绍
1. UUID
UUID是Universally Unique Identifier的缩写,它是在一定的范围内(从特定的名字空间到全球)唯一的机器生成的标识符,UUID是16字节128位长的数字,通常以36字节的字符串表示,比如:3F2504E0-4F89-11D3-9A0C-0305E82C3301。
UUID经由一定的算法机器生成,为了保证UUID的唯一性,规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,以及从这些元素生成UUID的算法。UUID的复杂特性在保证了其唯一性的同时,意味着只能由计算机生成。
优点:
- 本地生成ID,不需要进行远程调用,时延低,性能高。
缺点:
- UUID过长,16字节128位,通常以36长度的字符串表示,很多场景不适用,比如用UUID做数据库索引字段。
- 没有排序,无法保证趋势递增。
2. Flicker方案
这个方案是由Flickr团队提出,主要思路采用了MySQL自增长ID的机制(auto_increment + replace into)
#数据表
CREATE TABLE Tickets64 (
id bigint(20) unsigned NOT NULL auto_increment,
stub char(1) NOT NULL default '',
PRIMARY KEY (id),
UNIQUE KEY stub (stub)
)ENGINE=MyISAM;#每次业务使用下列SQL读写MySQL得到ID号
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();replace into 跟 insert 功能类似,不同点在于:replace into 首先尝试插入数据到表中,如果发现表中已经有此行数据(根据主键或者唯-索引判断)则先删除此行数据,然后插入新的数据, 否则直接插入新数据。
为了避免单点故障,最少需要两个数据库实例,通过区分auto_increment的起始值和步长来生成奇偶数的ID。
Server1:
auto-increment-increment = 2
auto-increment-offset = 1
Server2:
auto-increment-increment = 2
auto-increment-offset = 2优点:
- 充分借助数据库的自增ID机制,可靠性高,生成有序的ID。
缺点:
- ID生成性能依赖单台数据库读写性能。
- 依赖数据库,当数据库异常时整个系统不可用。
对于依赖MySql性能问题,可用如下方案解决:
在分布式环境中我们可以部署多台,每台设置不同的初始值,并且步长为机器台数,比如部署N台,每台的初始值就为0,1,2,3…N-1,步长为N。
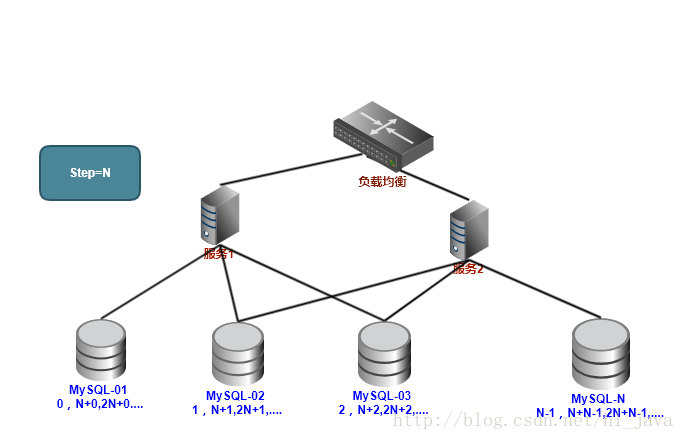
以上方案虽然解决了性能问题,但是也存在很大的局限性:
- 系统扩容困难:系统定义好步长之后,增加机器之后调整步长困难。
- 数据库压力大:每次获取一个ID都必须读写一次数据库。
3. 类snowflake方案
这种方案生成一个64bit的数字,64bit被划分成多个段,分别表示时间戳、机器编码、序号。
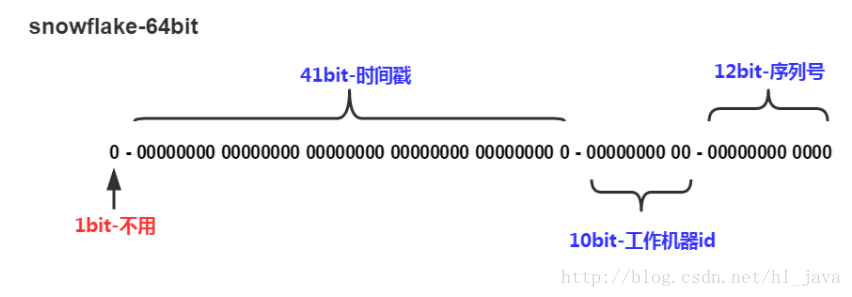
ID为64bit 的long 数字,由三部分组成:
- 41位的时间序列(精确到毫秒,41位的长度可以使用69年)。
- 10位的机器标识(10位的长度最多支持部署1024个节点)。
- 12位的计数顺序号(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)。
优点:
- 时间戳在高位,自增序列在低位,整个ID是趋势递增的,按照时间有序。
- 性能高,每秒可生成几百万ID。
- 可以根据自身业务需求灵活调整bit位划分,满足不同需求。
缺点:
- 依赖机器时钟,如果机器时钟回拨,会导致重复ID生成。
- 在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况。
4. TDDL序列生成方式
TDDL是阿里的分库分表中间件,它里面包含了全局数据库ID的生成方式,主要思路:
- 使用数据库同步ID信息。
- 每次批量取一定数量的可用ID在内存中,使用完后,再请求数据库重新获取下一批可用ID,每次获取的可用ID数量由步长控制,实际业务中可根据使用速度进行配置。
- 每个业务可以给自己的序列起个唯一的名字,隔离各个业务系统的ID。
数据表设计:
seqName varchar(100) 序列名称,主键
cur_value bigint(20) 当前值
step int 步长,根据实际情况设置##### 优点:
- 相比flicker方案,大大降低数据库写压力,数据库不再是性能瓶颈。
- 相比flicker方案,生成ID性能大幅度提高,因为获取一个可用号段后在内存中直接分配,相对于每次读取数据库性能提高了几个量级。
- 不同业务不同的ID需求可以用seqName字段区分,每个seqName的ID获取相互隔离,互不影响。
缺点:
- 强依赖数据库,当数据库异常时整个系统不可用。
发号器实现方案
综合对比以上四种实现方案,以及我们的业务需求,最后决定采用第三种方案。
主要原因:
- 业务需求:业务要求生成的ID要有递增趋势,全局唯一,并且为数字。
系统考虑:第三种方案性能高,稳定性高,对外部资源依赖少。
依据实际业务需求和系统规划,对算法进行局部调整,实现了发号器snowflake方案。
发号器snowflake方案
发号器snowflake方案中对bit的划分做了如下调整:
- 36 bit 时间戳,使用时间秒
- 5 bit 机器编码
- 22 bit 序号
机器编码维护:
机器编码是不同机器之间产生唯一ID的重要依据,不能重复,一旦重复,就会导致有相同机器编码的服务器生成的ID大量重复。 如果部署的机器只是少量的,可以人工维护,如果大量,手动维护成本高,考虑到自动部署、运维等等问题,机器编码最好由系统自动维护,有以下两个方案可供选择:
- 使用mysql自增ID特性,用数据表,存储机器的mac地址或者ip来维护。
- 使用ZooKeeper持久顺序节点的特性。
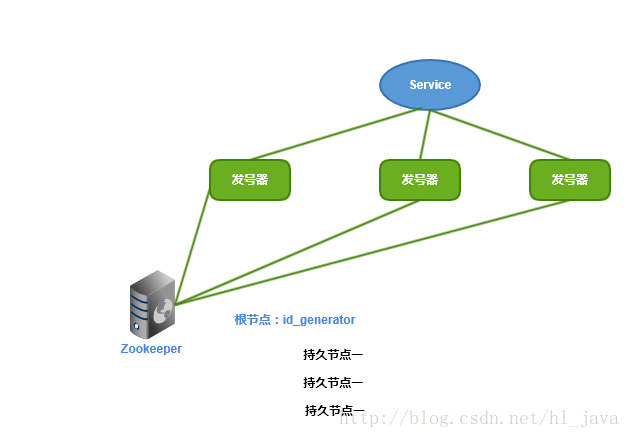
这里我们使用ZooKeeper持久顺序节点特性来配置维护WORKID.发号器的启动顺序如下:
- 启动发号器服务,连接ZooKeeper, 检查根节点id_generator是否存在,如果不存在就创建系统根节点。
- 检查根节点下当前机器是否已经注册过(是否有该顺序子节点)。
- 如果有注册,直接取回自己的WORKID。如果没注册,在根节点下创建一个持久顺序节点,取回顺序号做WORKID。
一旦取回WORKID,缓存在本地文件中,后续直接使用,不再与ZooKeeper进行任何交互,此方案对ZooKeeper依赖极小。
时钟问题:
snowflake方案依赖系统时钟,如果机器时钟回拨,就有可能生成重复ID,为了保证ID唯一性,必须解决时钟回拨问题。
可以采取以下几种方案解决时钟问题:
关闭系统NTP同步,这样就不会产生时钟调整。
系统做出判断,在时钟回拨这段时间,不生成ID,直接返回ERROR_CODE,直到时钟追上,恢复服务。
//发生回拨,本次最新时间小于上次时间
if(timestamp < this.lastTimestamp) {
throw new GeneratIdException("时钟回拨,拒绝生成ID");
}
- 系统做出判断,如果遇到超过容忍限度的回拨,上报报警系统,并把自身从集群节点中摘除
//发生回拨,本次最新时间小于上次时间
if (timestamp < this.lastTimestamp) {
long delay=lastTimestamp - timestamp;
//如果偏差比较小,则等待
if(delay<10) {
Thread.sleep(delay);
}
timestamp=this.timeGen();
//如果还没好,报警
if(timestamp < this.lastTimestamp) {
timeCallBackProcess(timestamp,this.lastTimestamp)
}else{
//重新分配ID
long id=nextSeqId();
}
}系统做兼容处理,由于nfp网络回拨都是几十毫秒到几百毫秒,极少数到秒级别,这种回拨会产生以下几种结果:
- 当前秒数不变: 当前是8:30秒100毫秒,ntp回拨50毫秒,当前时间变成8:30秒50毫秒,这个时候秒数没变,我们算法的时间戳部分不会产生重复,就不影响系统继续发号
- 当前秒数向前:当前是8:30秒800毫秒,ntp 向前调整300毫秒,当前时间变成8:31秒100毫秒,由于这个时间还没发过号,不会生成重复的ID
- 当前秒数向后:当前是8:30秒100毫秒,ntp回拨150毫秒,当前时间变成8:29秒950毫秒,这个时候秒发生回退,就可能产生重复ID。产生重复的原因在于秒回退后,算法的时间戳部分使用了已经用过的时间戳,但是算法的序号部分,并没有回退到29秒那个时间对应的序号,依然使用当前的序号,如果序号也同时回退到29秒时间戳所对应的最后序号,就不会重复发号。解决方案如下:
系统中缓存最近几秒内最后的发号序号(具体范围请根据实际需要确定),存储格式为:时间秒-序号。
Map<Long,Long> map=new ConcurrentHashMap<Long,Long>();
//发生回拨,本次最新时间小于上次时间
if (timestampSec < this.lastTimestampSec) {
//有缓存
if(map.get(timestampSec)!=null) {
this.sequence=map.get(timestampSec);
this.nextId();
map.put(timestampSec,this.sequence)
}else {
throw new GeneratIdException("时钟回退,拒绝生成ID");
}
}闰秒处理:
闰秒,是指为保持协调世界时接近于世界时时刻,由国际计量局统一规定在年底或年中(也可能在季末)对协调世界时增加或减少1秒的调整。由于地球自转的不均匀性和长期变慢性(主要由潮汐摩擦引起的),会使世界时(民用时)和原子时之间相差超过到±0.9秒时,就把协调世界时向前拨1秒(负闰秒,最后一分钟为59秒)或向后拨1秒(正闰秒,最后一分钟为61秒),闰秒一般加在公历年末或公历六月末。
在闰秒产生的时候系统会出现秒级时间调整,下面我们来分析闰秒对发号器的影响:
负闰秒:当前23:59:58的下一秒就是第二天的00:00:00,00:00:00 这个时间我们还没产生过ID,不会产生重复的,对发号器没影响。
正闰秒:当天23:59:59的下一秒当记为23:59:60,然后才是第二天的00:00:00。由于我们系统时间戳部分取的从某个时间点(1970年1月1日)到现在的秒数,是一个数字,只要这个数字不重复,就不会产生重复的ID。如果在闰秒发生一段时间后ntp时间同步(为了规避闰秒风险,很多公司闰秒前关闭ntp同步,闰秒后打开ntp同步),这个时候系统时钟回拨,可以使用解决时钟回拨的方案进行处理。
服务部署优化
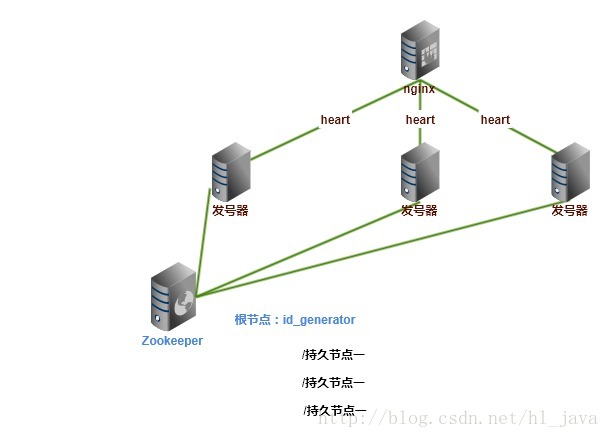
部署结构
为了实现高可用,避免单点故障,系统部署采用集群水平部署,前置使用nginx做负载均衡,发号器使用springboot框架,web服务器使用springboot内嵌tomcat, 发号器和nginx之间进行心跳检测。
tomcat调优
使用APR
Tomcat支持三种接收请求的处理方式:BIO、NIO、APR, 性能 BIO
@Configuration
public class TomcatConfig {
AprLifecycleListener arpLifecycle = null;
@Value("${com.tomcat.apr:false}")
private boolean enableApr;
@Bean
public TomcatEmbeddedServletContainerFactory containerFactory() {
TomcatEmbeddedServletContainerFactory tomcat=new TomcatEmbeddedServletContainerFactory();
if (enableApr) {
arpLifecycle = new AprLifecycleListener();
tomcat.setProtocol("org.apache.coyote.http11.Http11AprProtocol");
}
return tomcat;
}
}开发中遇到的问题
整个开发过程都非常顺利,测试的时候tps也很高,心情很愉快,世界很美好,突然一个意外出现,发现存在full gc现象,有内存溢出? 于是分析了好几遍程序,也没找到明显的线索,只能开始jvm调试旅程。
pingpoint 监控图:
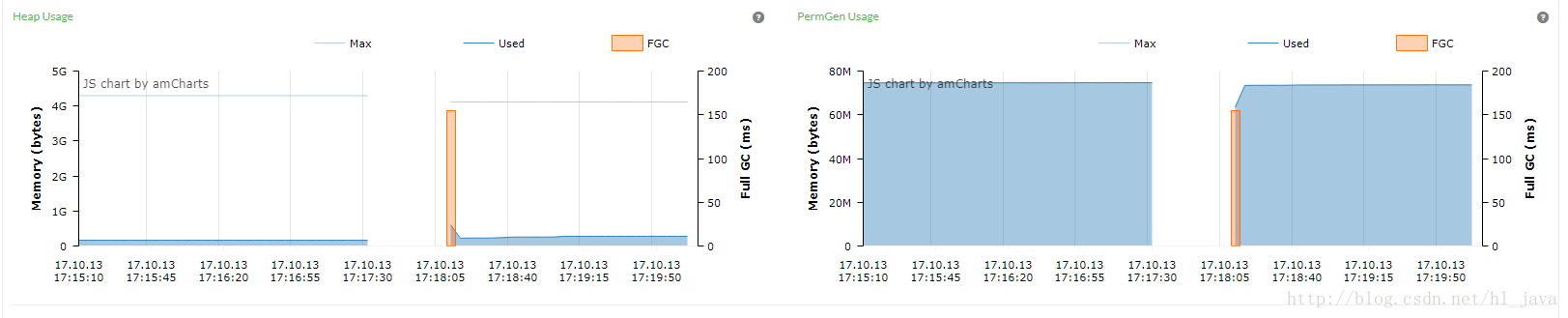
(上图中红色部署表示full gc)
JVM调试最直接的就是获取full gc时的jvm dump文件,以及gc log进行分析:
为了获取dump文件,在jvm参数中加上:
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps
-Xloggc:/tmp/gc2/gc.log -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/gc2/heapdump.bin
-XX:+HeapDumpBeforeFullGC -XX:+HeapDumpAfterFullGC参数介绍:
-XX:+PrintGCDetails 打印出gc详细信息
-Xloggc:/tmp/gc2/gc.log 输出gc日志
-XX:+HeapDumpBeforeFullGC full gc前打出dump文件
-XX:+HeapDumpAfterFullGC full gc后打出dump文件配置上面的虚拟机参数后,虚拟机gc的时候会把gc相关信息输出到文件gc.log中,full gc前后,会生成当时虚拟机的内存dump文件。从pingpoint监控图中可以看出full gc是发生在持久区域。
使用jmap 工具,获取JVM堆内存信息如下:
jmap -heap pid
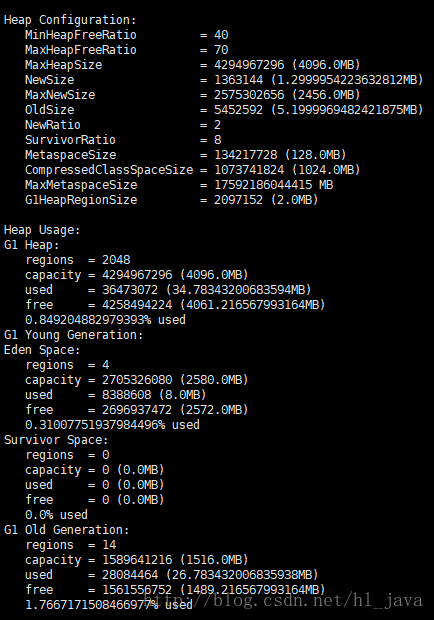
从上图可以看出,使用的堆内存很少,总的堆内存只有0.84% 使用,其它使用指标也都在正常范围,系统装载的类也不多,没有内存泄露。
继续分析gc log:
Java HotSpot(TM) 64-Bit Server VM (25.131-b11) for windows-amd64 JRE (1.8.0_131-b11), built on Mar 15 2017 01:23:53 by "java_re" with MS VC++ 10.0 (VS2010)
Memory: 4k page, physical 8243596k(2632468k free), swap 11934328k(2371912k free)
CommandLine flags: -XX:+DisableExplicitGC -XX:+HeapDumpAfterFullGC -XX:+HeapDumpBeforeFullGC -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/gc2/heapdump.bin -XX:InitialHeapSize=1073741824 -XX:InitiatingHeapOccupancyPercent=35 -XX:LargePageSizeInBytes=134217728 -XX:MaxGCPauseMillis=20 -XX:MaxHeapSize=1073741824 -XX:MaxTenuringThreshold=15 -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseFastAccessorMethods -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
2017-08-10T17:02:29.308+0800: 2.077: [GC (Metadata GC Threshold) [PSYoungGen: 146832K->20475K(305664K)] 146832K->20563K(1005056K), 0.0336455 secs] [Times: user=0.02 sys=0.00, real=0.03 secs]
2017-08-10T17:02:29.341+0800: 2.109: [Heap Dump (before full gc): , 0.0004810 secs]2017-08-10T17:02:29.341+0800: 2.110: [Full GC (Metadata GC Threshold) [PSYoungGen: 20475K->0K(305664K)] [ParOldGen: 88K->19759K(699392K)] 20563K->19759K(1005056K), [Metaspace: 20897K->20897K(1069056K)], 0.0436578 secs] [Times: user=0.13 sys=0.02, real=0.04 secs]
2017-08-10T17:02:29.385+0800: 2.153: [Heap Dump (after full gc): , 0.0002851 secs]2017-08-10T17:02:32.687+0800: 5.455: [GC (Allocation Failure) [PSYoungGen: 262144K->16221K(305664K)] 281903K->35989K(1005056K), 0.0334918 secs] [Times: user=0.09 sys=0.01, real=0.03 secs]
2017-08-10T17:02:32.891+0800: 5.659: [GC (Metadata GC Threshold) [PSYoungGen: 28382K->6904K(305664K)] 48150K->26680K(1005056K), 0.0168069 secs] [Times: user=0.06 sys=0.00, real=0.02 secs]
2017-08-10T17:02:32.908+0800: 5.676: [Heap Dump (before full gc): , 0.0008220 secs]2017-08-10T17:02:32.909+0800: 5.676: [Full GC (Metadata GC Threshold) [PSYoungGen: 6904K->0K(305664K)] [ParOldGen: 19775K->16811K(699392K)] 26680K->16811K(1005056K), [Metaspace: 34773K->34773K(1081344K)], 0.0770809 secs] [Times: user=0.22 sys=0.00, real=0.08 secs]
2017-08-10T17:02:32.986+0800: 5.754: [Heap Dump (after full gc): , 0.0003360 secs]从gc log 中寻找线索:
2017-08-10T17:02:32.908+0800: 5.676: [Heap Dump (before full gc): , 0.0008220 secs]2017-08-10T17:02:32.909+0800: 5.676:== [Full GC (Metadata GC Threshold)== [PSYoungGen: 6904K->0K(305664K)] [ParOldGen: 19775K->16811K(699392K)] 26680K->16811K(1005056K), ==[Metaspace: 34773K->34773K(1081344K)]======================, 0.0770809 secs] [Times: user=0.22 sys=0.00, real=0.08 secs]
2017-08-10T17:02:32.986+0800: 5.754: [Heap Dump (after full gc): , 0.0003360 secs]这里发现了以下线索:
- 从 [Full GC (Metadata GC Threshold)看出,的确产生了full gc,原因 Metadata GC Threshold。
- [Metaspace: 34773K->34773K(1081344K)] full gc前后metaspace的size没有变化说明此区域已经满了,释放不出内存。
- 仔细分析gc log,发现2次full gc记录,第一次full gc [Metaspace: 20897K->20897K(1069056K),这个值比第2次的要小很多。
[Full GC (Metadata GC Threshold) [PSYoungGen: 20475K->0K(305664K)] [ParOldGen: 88K->19759K(699392K)] 20563K->19759K(1005056K), [Metaspace: 20897K->20897K(1069056K)],两次full gc原因都是 Metadata GC Threshold类型,说明pingpoint监控到的full gc是元空间引发的full gc,并非内存泄露引起,但是这个值才34m,距离最大值1081m,还有很大空间,为什么会full gc?
经过查阅官方资料,发现MetaspaceSize的默认大小是21807104b,也就是21296k,而发生GC的时候,元空间已经使用了34722K,从而产生full gc。
方法区:
方法区也是所有线程共享。主要用于存储类的信息、常量池、方法数据、方法代码等。方法区逻辑上属于堆的一部分,但是为了与堆进行区分,通常又叫“非堆”。其实,移除永久代的工作从JDK1.7就开始了。JDK1.7中,存储在永久代的部分数据就已经转移到了Java Heap或者是 Native Heap。但永久代仍存在于JDK1.7中,并没完全移除,譬如符号引用(Symbols)转移到了native heap,字符串常量转移到了java heap,类的静态变量(class statics)转移到了java heap。
在JDK8中,classe metadata(the virtual machines internal presentation of Java class),被存储在叫做Metaspace的native memory。一些新的flags被加入:-XX:MetaspaceSize,class metadata的初始空间配额,以bytes为单位,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当的降低该值;如果释放了很少的空间,就会在不超过MaxMetaspaceSize(如果设置了的话)的情况下,适当的提高该值。
在虚拟机参数中增加MetaspaceSize初始化大小,-XX:MetaspaceSize=128m,重新启动项目,不再有full gc出现。
总结
”发号器“—达达分布式ID生成系统,是以snowflake算法为基础,实现了生成全局唯一ID的功能,解决了在分布式系统唯一ID生成问题。在实现高可用性方面,采用水平集群部署、心跳检测等方案为系统保驾护航。该系统目前已在达达商城等项目中使用,每天提供大量服务。
参考
- Snowflake (https://github.com/twitter/snowflake)
- TDDL















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









