







Abstract:本章将采用 K−means 提取图像的特征,随机在原始图像上切取多块正方形区域训练聚类中心点,通过聚类中心点提取特征,实验说明了白化对实验结果的影响,pooling大小对实验结果的影响。还对比了不同的特征提取模型,对比了不同的识别率。
一. 随机切取原始图像的small-patchs做为原始的训练K-means中心点的样本
数据库:cifar-10
对于原始的图像为
32×32
大小的彩色RGB图像,从这些图像上切取一小块,这一小块可以代表图像的一些细节特征,这小块图像中包含了图像的局部的颜色信息以及细节方面的信息,细节方面的信息可以这样理解,某一块图像中的信息代表原始图像的一部分特有边缘信息,角点信息等其他信息,那么同种类别的图像可能含有同样的信息,我们可以把这一小块做为这类别图像特有的信息。对于一张图像得到的小块的信息可能一样,颜色还有细节方面都有同样的信息,多个小块之间就具有了统计意义,统一特性能代表某一类图像的特性。
1.初始化小块的尺寸,小块的尺寸不能太小,这样不具有统计意义, 太小不能包含足够多的颜色信息,也不能完全涵盖图像某一种特性。尺寸太大包含的信息量太大,不适合做聚类。
2. 初始化聚类的子块数目,那么信息更加丰富,不同的类别越容易分类。
3. 白化,白化的目的是去不同像素点之间的相关性。
1. cifar-10的图像大小为32×32×3,我们取子块为一个方体,大小为N×N×3,本文将用不同尺寸块来测试识别率。
2. 不同的子块数目对最后识别率的影响。
3. 白化对识别率的影响。
图1为随机切割的子块。我们只需要随机化图像中点的坐标,向下和向上平移N个像素点进行切割,得到一个N×N×3的子块。

图1 从原始图像中切割的任意的子块的样本
二. K−means 提取样本特征
本节将采用两种方式进行提取特征。
第一种: 原始图像中的子块到聚类中心的距离作为特征。
第二种: 使用back of words(词袋模型)对图像进行特征提取。
下面将分别介绍两种提取特征的方法。
聚类中心到子块的距离特征
1.对于K个聚类中心( μ1,μ2,...,μk )的K-means,N个样本( x1,x2,...,xN ),其损失函数为:
J(x1,x2,...,xN,μ1,μ2,...,μk)=1m∑mi=1||xi−μc(i)||2 . 得到聚类中心如图2所示:
图2 K-means聚类中心(with whitening)2.从第一步我们可以得到聚类中心,通过聚类中心来提取特征。
对于原始的三通道图像,我们假设其子块大小为w×w,步长为s,我们抽取w×w的块,步长为s取小块,抽取出来得到列向量。那么得到新的图像大小为 (n−w)/s+1 .如图3所示。
图3 抽取新特征的图示

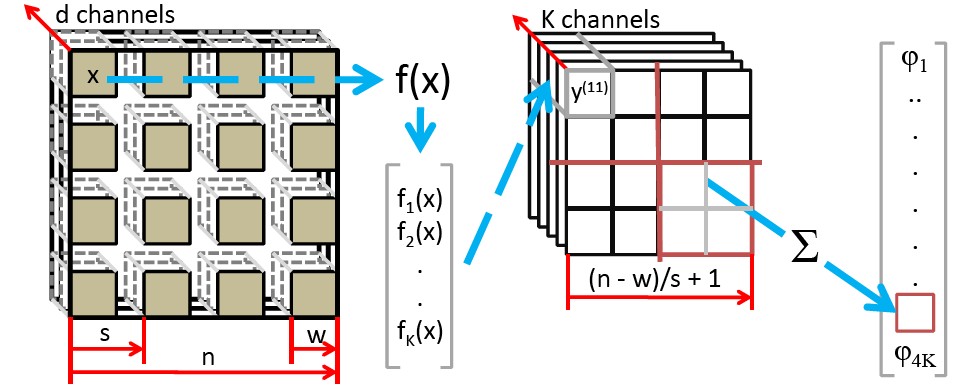
对于得到新特征,需要做归一化处理(均值方差处理)。然后对新特征进行白化使数据之间独立。我们得到新块的大小为
(w×w×3)×((n−w)/s+1)2
.对于cifar-10为32×32×3的图像,子块大小为8×8×3,那么我们可以得到(32-8+1)^2个子块,子块展开为列向量为192维,那么一副图像待提取特征的大小为625×192,我们把这625个192维子块分别与中间求距离,假设有K个中心点,那么每个192的子块可以得到K个距离,那么625个子块就得到一个625×K为的特征。
对于一个向量
x
,其中心点为
对于上式为可以化简如下:
这样处理的距离可能有负值,那么我们把负值设为0即可。那么
提取特征过程类似于图像相关操作,每一点的相应如下表达式所示:
对于聚类提取特征,没一点的相应不是相乘以后累加和,而可以表示为如下:
以下是K-means提取出的1600张特征图,因为有1600个聚类中心点,故有1600张特征图。如图4所示:

对于得到特征图,每一张图可以进行均值pooling,可以看做一张图像到一个中心点的平均距离,那么就有1600个特征。也可以分四个区域分别对特征图进行pooling,那么对于1600个中心点,就有6400个特征,得到的特征可以用来训练softmax分类器。
- 词袋模型提取特征
词袋模型,前面部分我们可以通过小块得到聚类中心,我们可以设置N个词袋,意味着需要聚类N个聚类中心。对M×M,假如我们取的子块a×a,三通道也如此,那么对于步长为1处理,我们可以得到(M-a+1)×(M-a+1)个子图,子图我们展开为一行,每个子图分别与这N个聚类中心求距离,得到这个子图所属的聚类中心,那么这(M-a+1)×(M-a+1)个子图都可以得到属于自己的聚类中心。对M个聚类中心,统计其每个聚类中心有多少张子图(对于每一个聚类中心,最大为(M-a+1)×(M-a+1),称为全靠近,最小为0,那么没有任何一张子图靠近这个聚类中心点)。我们得到一个1—N的直方图,直方图就代表这一样本的特征,我们可以用softmax训练分类器。
三. 实验
我采用两种提取特征的方法测试实验结果。
聚类中心到子块的距离特征,采用两种对比方法,第一种是是否加入白化。第二种,采用不同大小的pooling。本实验还包括词袋模型和聚类中心到子块的距离特征模型的比较。
1.
| 方法 | 识别率 |
| 白化(1600个聚类中心,全局pooling) | 72,72% |
| 非白化(1600个聚类中心,全局pooling) | 62.04% |
图5是白化和非白化得到的聚类中心图
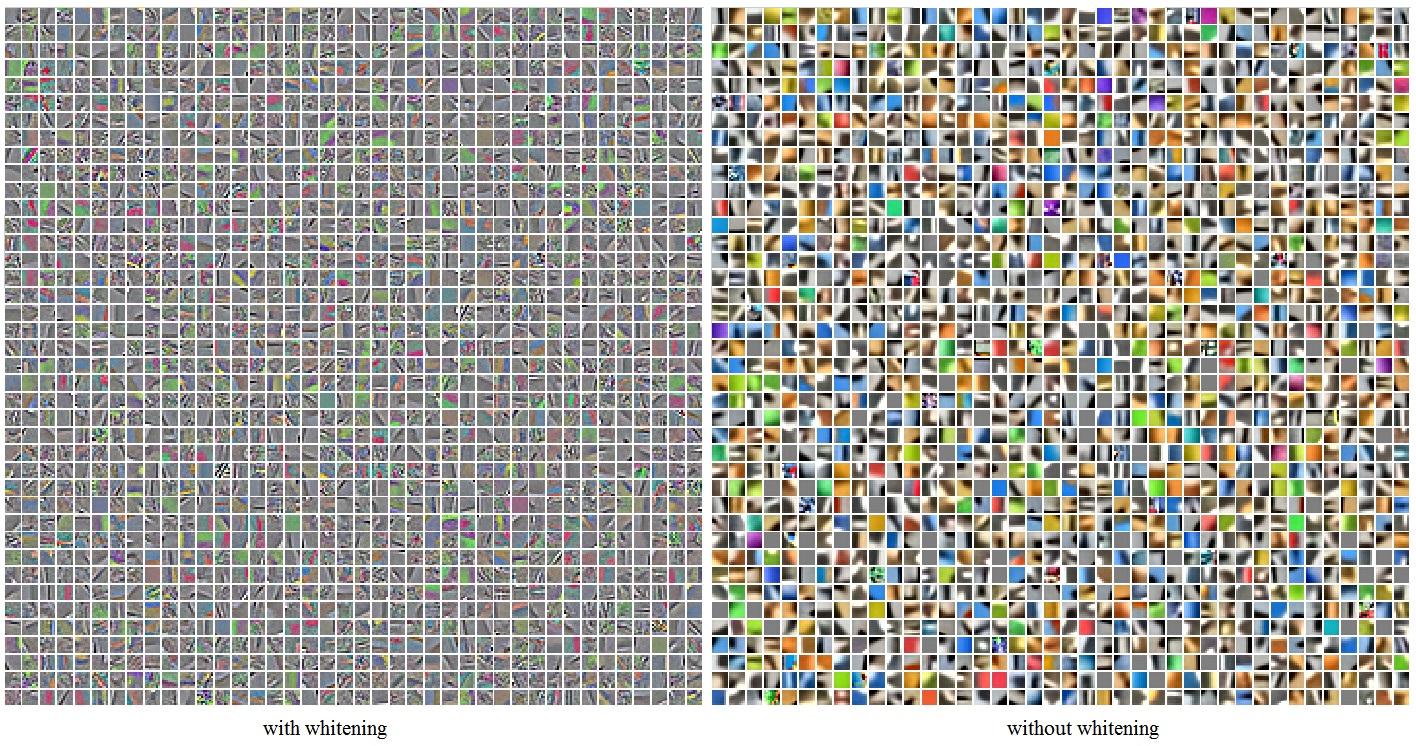
从表一可以看出白化之后的效果会好点
2.
| 方法 | 识别率 |
| 全局pooling(白化) | 72,72% |
| pooling成2×2的块(白化) | 75,72% |
| pooling成3×3的块(白化) | 74,71% |
从表二可以看出全局pooling的效果没有分块pooling的效果好。
2.
| 方法 | 识别率 |
| 聚类中心到子块的距离特征(1600个聚类中心点) | 72,72% |
| 词袋模型(1600个聚类中心点) | 58,92% |
从表三可以看出距离特征建立的模型比词袋模型效果好。
代码和文章见附件(数据库见http://www.cs.toronto.edu/~kriz/cifar.html)

怀柔风光















 1401
1401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









