







本文转载自:http://wenda.chinahadoop.cn/question/1029
是一篇演讲文,而且时间比较早,2015年,当时vertica的最新版本是7.2,现在(2019年)已经出到9.2了。但是,这篇演讲文,对于vertica的介绍还是比较全面的,vertica的前世今生,主要特性。这些很有助于了解vertica,故作此摘录。
首先我想给大家介绍一下什么是MPP数据库,然后重点讨论一下HP Vertica作为一个MPP和列式数据库有什么特点。下面我会讲一些我个人在亲身经历过的一些案例,包括FacceBook,还有ATT。 最后简单讨论一下我们Vertica最新版本(7.2)里面推出的把Vertica的数据引擎放在Hadoop上面的一种实现。
什么是MPP,MPP就是Massively Parallel Processing. 它的意思就是说所有的结点之间没有这些相关性,各个结点有自己的本地磁盘,自己的内存系统等。这种架构的特点就是它有非常好的扩展性,这点基本上现在业界已经是非常明确了。任何一个数据库,或者是应用,如果不是MPP的话,基本上扩展性方面都会有问题。举几个例子,Terdata首先是于1979年把MPP付出实践,另外在1980年左右在Wisconsin大学有一个非常出色的数据库研究小组,做了很多数据库方面的开发工作。他们的Gamma模型也是最早的MPP数据库例子之一。
MPP有两个非常常见的架构,一个有主机有副机,另外一种架构就是我们Vertica和Terdata采用的架构,所有的结点都是完全的一样,没有主结点,和计算结点副结点之分。在任何一个结点上,你都可以加载也可以查询。每个结构的优点缺点应该是很简单的事情, 大家仔细想一下就会明白, 这里我就不细说了。 下面我想简单给大家对整个数据库在最近45年内的发展做一个简单的介绍。
1970年IBM的一个研究人员写了一篇到现在都是非常经典的一篇关系数据库的论文,这篇论文把关系数据库的基础奠定的非常牢固。 在随后的45年间才产生出各种各样的数据库。我这里列的只是一些有关于部分分析数据库的一些演变,主要是OLTP的数据库。
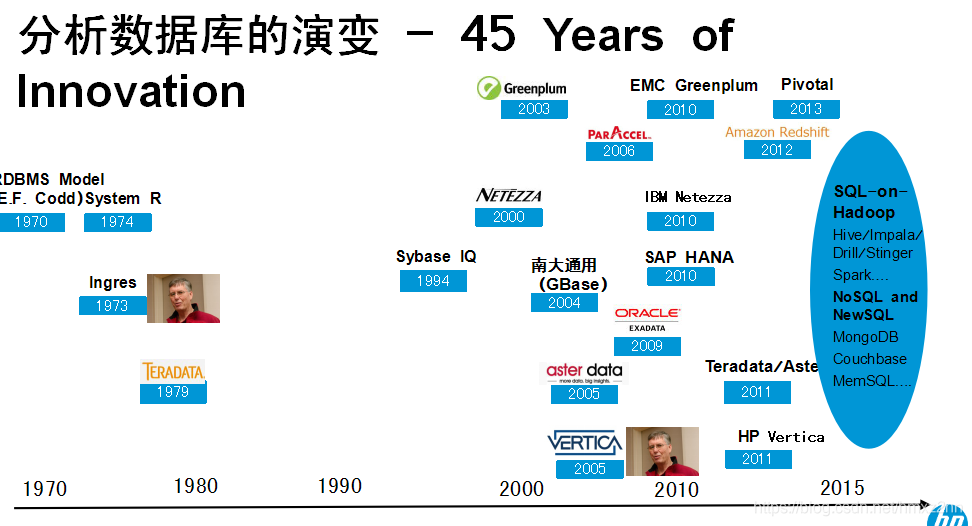
首先看一下在1973年的时候,有位数据库的牛人 Mike Stonebrak,当时是加州伯克利大学的一位年轻教授,他和他的学生开发了一个数据库叫做 Postgres。从这个数据库演变出了很多其他的数据库。他们都是基于Postgres。
另外就是IBM在1974开发的一个关系数据库 (System R),那也是很有名的一个数据库。从那个项目出来了很多牛人,最后去了各个其他的公司。从这个关系来看,从Postgres 后发展出来了一系列的公司像 Netezza, GreenPlum。从System R 也是演化出了一系列的公司, Terdata是世界上第一家公司,把MPP从一个完全抽象的概念,证明在实践中可行。Sybase IQ这家公司的主要贡献就是94年的时候它是第一家公司证明列式数据库的可行性。 Vertica的贡献是什么呢? 2005年我们是第一家公司证明MPP再加上列式储存对整个提升数据库的查询功能有巨大的帮助。这是我们的贡献。还有一些其他的最新出来的一些公司,他们是Vertica的竞争对手。但是这些公司,也是慢慢的演变,被一些更大的公司收购。 Vertica 于2011年被HP收购。目前且有一些其他的开源公司等等。这些都是开源的数据库。但是从基本方面来讲的话,他门还是太新,很多地方还不成熟。另外还有一些NoSQL,NewSQL的数据库等等。这些主要是OLTP方面的数据库。
好,简单介绍一下Vertica的历史。 Vertica是2005年由数据库专业的先驱Mike Stonebraker建立的,Mike Stonebraker不知道大家熟悉不熟悉,他确实是数据库业的大佬,他一个人在美国大概创办了10几家各种各样的一些创业公司。 他这个人也是一个传奇。 就是有这样的人,在学术界做的很好,同时对整个数据库的商业发展还有一些非常好的想法并能付诸实践。Mike Stonebraker他是2015 Turing奖的获得者。 这个奖大家可能也都听说过,它是计算机科学的诺贝尔奖。 一定意义上比诺贝尔奖还难得,因为每年它只发奖给一个人。诺贝尔奖经常是有多人分享。Vertica整个概念,其实基于一篇MIT的博士论文,2005的一篇经典论文。我刚才也提到过,就是Vertica没有发明MPP,我们也没有发明列式储存,但是我们是全世界第一家公司,把MPP和列式储存的概念结合在一起,开发出来的分析型数据库。2011年Vertica被惠普收购时我们在全球有300个企业客户。 2015年截止到目前,有2000多客户。包括一些大家都非常熟悉的公司,FB、美洲银行等等。
Vertica的第一个版本是2007年发布的。最新的版本是一个多星期前发布的,现在最新的版本类型是7.2。去年我们也得了一个奖 - 最佳列式数据库。

我们全球有2000多个客户,横跨各个行业,从金融、互联网、电信和零售等等都有。我简单的列举了几个客户的名字如UBER、facebook 等。 公司A是上个月我们刚刚签的大单子,Vertica有史以来最大的单子,具体的消息还没有公开。另外一家公司很有意思是一家小的创业公司 KIVA,是做小笔信贷工作的。KIVA从商业模式上讲很像国内的蚂蚁金融,但是它是非盈利性质的。
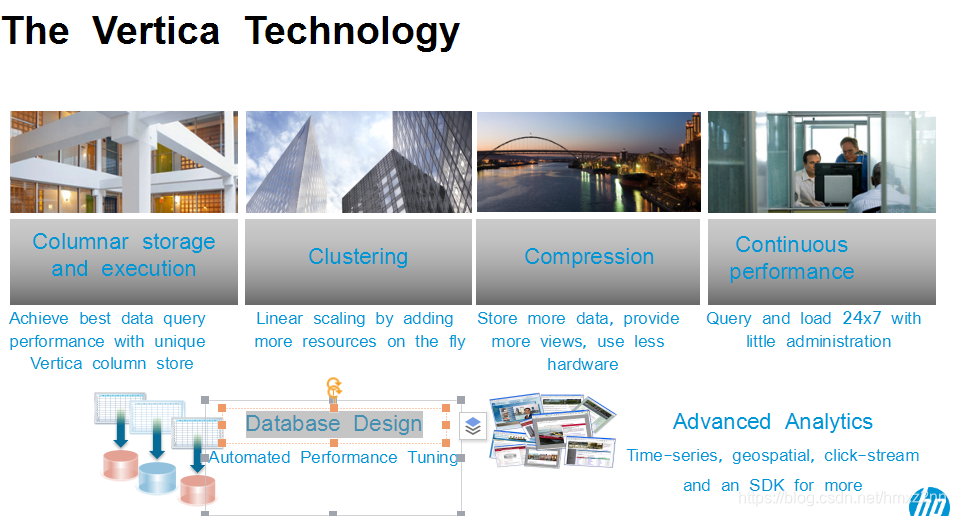
Vertica的技术我们叫4个C,第一首先是整个数据储存完全是columnar,但是columnar从储存到数据库的引擎,以及到数据库的优化性、整个一条线全部是和这个columnar密切相关。 很多市场上所谓columnar数据库完全是在储存领域的一个小把戏。 列式数据储存不是什么了不起的事情,能够把列式数据储存,和数据引擎,以及整个数据库的优化器结合在一起,这才是难的事情。
Clustering就是MPP。 我们在扩容方面相对容易。至于压缩,这是所有列式数据库的一个天然优势。 比起我们的竞争对手,像一些老牌的数据库,Vertica的压缩率比他们高个10倍,几十倍不是很难的事。 Continuous performance是说Vertica的集群,我们有一套数据分布的办法,一定意义上,和Hadoop有一点相象。我们的数据是自动备份,这样的话,可以保证不管集群有多大任何一个结点掉线的情况下,整个集群还何以继续工作。除了这些以外,我们Vertica有一个业界非常少见的一个工具叫Database Designer (DBD)。这是Vertica内部的一个工具,它可以用来做一些自动的物理优化,比如说数据怎么分布,数据怎么排序等等。大家做过DBA的话,对这方面应该是有一些切身的体会。 那方面的工作,非常烦琐,很多情况下,全凭经验靠猜。Vertica开发了自己的工具,那方面的一些非常烦琐、负责的工作全部自动化。另外Vertica作为一个关系数据库,作为一个针对分析方向的数据库我们有自己非常先进的算法,全部可以直接在Vertica数据库上面跑。
简单介绍一下列数据库和其他行存储的数据库有什么优点。 举个例子。假如一个表有100列,绝大多数数据查询,其实他们用的那些列数,其实一般都很少,一般也就是几个列。我们内部做过研究,平均来说也就是5到6个列。这样的话,假如这个数据库是行式储存的话,这样的话,虽然查询只需要其中的三列,行式查询,必须要把100多列,全部都要从这个硬盘上读取出来,然后CPU要处理他们,大家可以想象一下,这样会造成多大的浪费。从列式数据库角度来说,以这个查询作为例子,它只需要读取三列,就从I/O的角度来说Vertica比这些传统的行式储存的数据库,就可以快30几倍. 再加上Vertica的数据引擎可处理这些数据,优化,这样我们从性能角度来说,比一般的行式有大幅度的提高。 我们比它们快10倍、几十倍不是什么特别了不起的事情。除了这点以外,还有其他优势。我提过压缩方面的优势。Vertica和一般大家常见的数据库有一点不同,就是我们在Vertica里面,表(table)只是一个逻辑的概念,一个table它只是定义了这些列的名字和数据类型。真正的物理储存,它怎么样储存在磁盘上,是通过自己的一个概念叫做projection来实现的,它和索引和Oracle里面的物化试图等等还是有区别的。最大的区别在于Vertica的数据永远是同步一致的。 另外就是Vertica的数据存储,像百度马先生也说过都是一些特殊的储存。 我们的储存,既可以在各个结点上分布,是在每个结点上又可以分区,又可以排列,这样的目的就是可以优化查询。排列的方式可以多种排列方式。 举个例子,ABC你可以排序,BA、CA都可以。整个Vertica的运行全部都是MPP,在各个结点上都可以同时跑查询,跑装载。在上一个版本,7.1的版本,我当时还介绍了一个新的概念,我们内部叫做 Life Aggregate Projection (LAP)。这种储存,是对大批量的数据做一个预先的处理,这样有一些查询不需要去直接读后面的表,可以把结果直接读取,这对并发度和效能都有很大的提升。还有Vertica里面,因为我们是并列储存,同时这些列也都是有序的。这样我们在Vertica里面没有索引这个概念。因为没有那些复杂的概念,就像我刚才的说过的,Vertica可以边装载边查询,他们彼此之间不会有任何干扰。Vertica作为一个关系数据库,我们和SQL衔接的非常好。
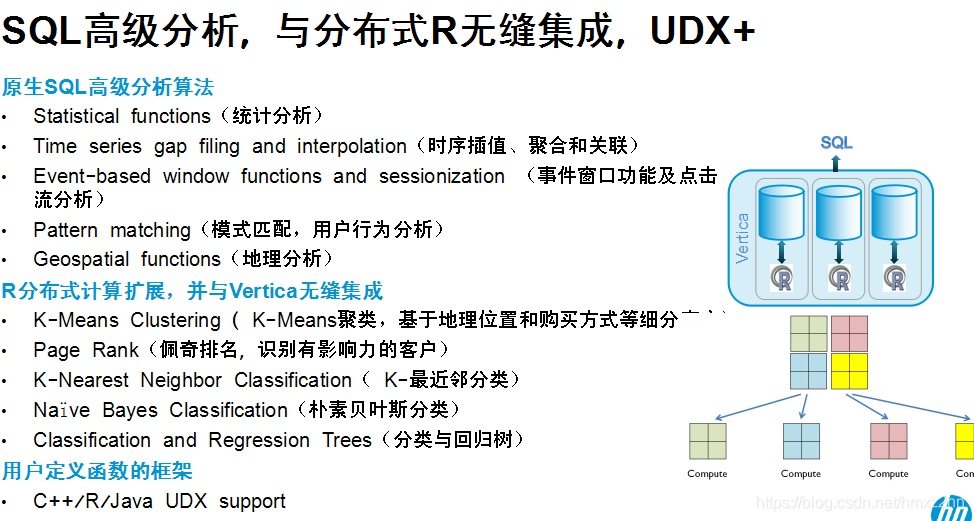
SQL-99基本上是完全的支持,除了标准的一些SQL的语句以外,我们还有自己的一套分析算法,统计分析等等。
分布式R,是HP实验室开发的一个开源R的应用。它和Vertica也是有一个可以做一个无缝衔接,各种各样的函数都有。Vertica同时也支持用C++/Java/R写的用户自定义的函数。
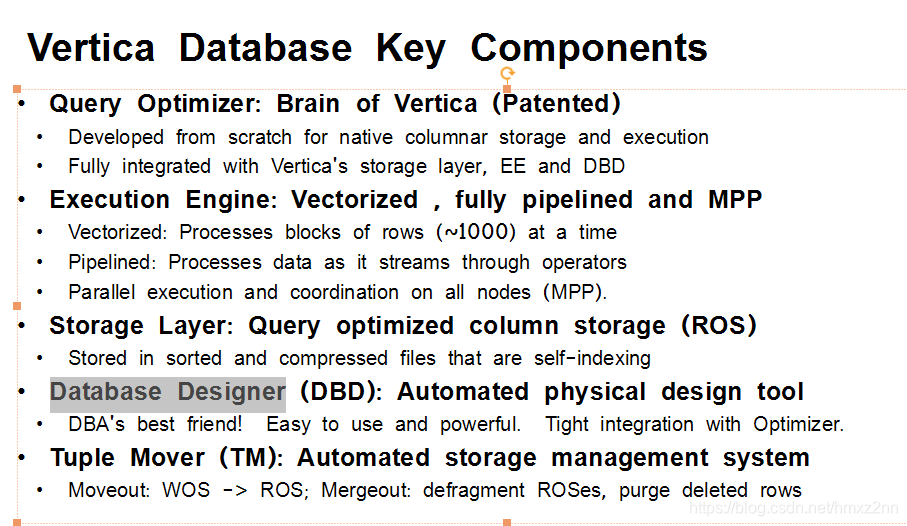
好下面我快速总结一下,Vertica的一些关键功能。 首先就是Vertica的优化器,我们是首创,从头写的,完全是自己一手开发的,这都是用了一些数据库领域非常领先的一些技术。比起其他的数据库Vertica这方面都有很大的优势。所有这些代码全都是C++,全部是模块方式,所以在Vertica内部开发加入新东西,加入一些新的功能,相对来说比起其他的传统数据库都是比较容易的。
Vertica的计算引擎也是有专利的技术。这样在计算的时候,各种各样的计算可以同时对很多数据都可以进行平行处理。
Vertica有自己特殊的储存方式。 这种储存方式当然是为了对查询有一些优化。储存方式最大的特点就是利用hash分布. 这点和很多其他的MPP数据库相似。同时我们也可以在同一个结点上。进行分区同时也可以进行排序。刚才我提到过Database Designer这个工具,这个工具目前业界只有Vertica一家才有。这个工具对于DBA是一个巨大的帮助。很多大的Vertica集群,包括大公司的上百个集群,从管理Vertica集群的人来看都经常不到一两个,同时他们还不是全职的。 他们同时还做开发和别的事情。 为什么?很大的原因,就是因为我们有自动的工具,对物理的一些设计优化我们提供自动解决方式。另外Database Designer(DBD)和我们的优化器,紧密衔接。 每个新的Vertica版本,优化器方面都会有进步,都会有改进,这样的话,在改进的同时,也会对我们Database Designer这个工具,有自动的改进。最后一项不详细说了,是一个后台的事情,对于小的文件,小批量插入Vertica用一些方式会在后台,磁盘上产生很多小的文件。这个工具就是自动把这些小文件整合起来。 这样对整个Vertica数据库的稳定性和查询效能都非常有帮助。这个功能虽然不起眼,绝大多数顾客都不知道。 但这个功能对Vertica的整体稳定性,和Vertica最近几年的成功有密不可分的关系。
为什么说现在在大数据的时代,这么多选择情况下,还很有多公司选择MPP,为什么?首先就是对大数据量的一些精确的分析,和需求,很多过去的数据库的可扩展性都很差。扩展性差性能也差同时价格非常高,这是一个原因。另外有一些一体机的公司,这些公司刚买的时候整体效能还可以,但是随着公司业务的发展,你会发现像一体机你要扩容,需要增加新功能等等,这些都会产生很大的影响。另外一体机普遍都还是太贵,还有就是内存数据库,这方面的技术Vertica内部也是观察的非常的仔细。从我们的角度来说,现在我们的几千家顾客,最大的公司并没有对内存数据库方面有一个非常明显的需求。另外还是因为一个以内存为储存的数据库还是太贵,这一定意义上也解释了为什么像SP HANA等在市场上不是特别流行。 它们也是因为既不成熟的同时,价格也是太贵了。Hadoop方面的技术,我们和百度的马先生的观点也都是一致的。也是觉得Hadoop的技术,性能太慢,Hadoop的开源这个社区乱糟糟,一天恨不得有几个版本出来。这样的话,从大公司角度来说是根本不可能用这样的技术作为他们整个大数据应用的一个核心支架。这四点不是我一人总结的,这是facebook说的。有一点大家觉得很奇怪,facebook居然嫌Hadoop技术不高。这是事实。
我简单讲一下facebook的案例,facebook做什么我就不说了。 2013年facebook是买了Vertica,通过两轮一年左右的POC,第一轮是在500个TB左右。70几结点。第二轮facebook把数据量从500TB,提高到了1.5个PB,这样第一轮淘汰了两个公司 (GreenPlum + Teradata),第二轮淘汰了一个 (Oracle Exadata)。至于说facebook的装载量那都是非常吓人。现在是35个TB一小时。 大家做个简单计算的话它一天大约是要装载一个PB的数据。 Facebook ma买了Vertica做什么? 当然做很多各种各样的分析了. 大家可能要问为什么facebook这么牛的公司,这么好的开发团队,为什么要买Vertica? facebook确实开发了很多自己的工具,它自己也想写一个列式数据库,遇到什么瓶颈?跟储存没有关系,瓶颈就是优化器和数据引擎的问题。他们自己花了一年时间写出来的优化器,数据引擎最后和Vertica PK不如我们,所以才买了我们。
第二个例子是谷歌下面的一家子公司,叫做adometry,这家公司它是在数据市场化领域有一些独到之处。很多年它在广告追踪,广告优化方面做的都比谷歌还好,2013年adometry买了Vertica。 2014年谷歌觉得没有意思,天天跟它竞争,直接就把它买了。所以adometry现在是谷歌的一部分。这家公司用的模型,是我们Vertica的案例。 目前正在把他们250T的数据搬到谷歌云里面,这样也可让谷歌其他部门有机会见识一下Vertica的能力。这家公司名字我们就不说了, 世界最大的手机制造商 (公司 A)。现在还没有公开报出来,上个月公司 A刚刚签了一个Vertica历史上最大的单子。公司 A为什么买Vertica,也是通过一年他们内部做的POC。公司 A做POC也是非常有章法,自己的一个团队,做的都很好,最后的结论,他们就觉得Vertica整体上从性价比方面远远超过公司 A用的Teradata,所以今年才买了Vertica。

这个案例是ATT, Vertica取代Teradata,整个数据大概有3个PB左右,ATT内部自己的计算是说Vertica取代Teradata之后,基本上是每月的这些运维方面的费用节省都在100万美金左右。 Vertica性价比方面比Teradata有非常明显的优势。这家银行是美洲银行,这家银行Netezza最大的顾客,我们同时取代了IBM Netezza和 DB2,从整个新能方面,整个数据库的运维方面,也有大幅的节省。
Vertica和Hadoop也是相辅相成,没有人愿意和Hadoop直接竞争。Vertica的定位是做一些实时的分析。Hadoop定位就是ETL分结构性数据的处理。我们最近有一些Vertica顾客提出来,就是说我们既有Vertica又有Hadoop,希望把Vertica的引擎和优化器放到Hadoop上面来。 这点对我们来说不是什么难题。几个开发人员,不到一年的工夫我们就开发出来Vertica-on-Hadoop这套工具。TPC_DS是一个很常见的标准,它其中有90几个查询,有46个分析方面的查询,Vertica所有的查询,都可以直接跑。Cloudera Impala只能跑21个其他的都需要改,很多查询都不能支持。 即使在21个能跑的,绝大多数功能我们都比它强。Vertica在我们自己网站上有一个社区的免费的社区版本,给你1个TB的裸数据,还有3个结点。大家感兴趣的话可以到Vertica的网站下载。可以看一下测试一下。














 4916
4916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









