一、字节序定义
字节序,顾名思义字节的顺序,再多说两句就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了)。
其实大部分人在实际的开发中都很少会直接和字节序打交道。唯有在跨平台以及网络程序中字节序才是一个应该被考虑的问题。
在所有的介绍字节序的文章中都会提到字节序分为两类:Big-Endian和Little-Endian。引用标准的Big-Endian和Little-Endian的定义如下:
a) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
b) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
c) 网络字节序:4个字节的32 bit值以下面的次序传输:首先是0~7bit,其次8~15bit,然后16~23bit,最后是24~31bit。这种传输次序称作大端字节序。由于 TCP/IP首部中所有的二进制整数在网络中传输时都要求以这种次序,因此它又称作网络字节序。比如,以太网头部中2字节的“以太网帧类型”,表示后面数据的类型。对于ARP请求或应答的以太网帧类型来说,在网络传输时,发送的顺序是0x08,0x06。在内存中的映象如下图所示:
栈底 (高地址)
---------------
0x06 -- 低位
0x08 -- 高位
---------------
栈顶 (低地址)
该字段的值为0x0806。按照大端方式存放在内存中。
二、高/低地址与高低字节
首先我们要知道我们C程序映像中内存的空间布局情况:在《C专家编程》中或者《Unix环境高级编程》中有关于内存空间布局情况的说明,大致如下图:
----------------------- 最高内存地址 0xffffffff
| 栈底
.
. 栈
.
栈顶
-----------------------
|
|
\|/
NULL (空洞)
/|\
|
|
-----------------------
堆
-----------------------
未初始化的数据
----------------(统称数据段)
初始化的数据
-----------------------
正文段(代码段)
----------------------- 最低内存地址 0x00000000
以上图为例如果我们在栈上分配一个unsigned char buf[4],那么这个数组变量在栈上是如何布局的呢[注1]?看下图:
栈底 (高地址)
----------
buf[3]
buf[2]
buf[1]
buf[0]
----------
栈顶 (低地址)
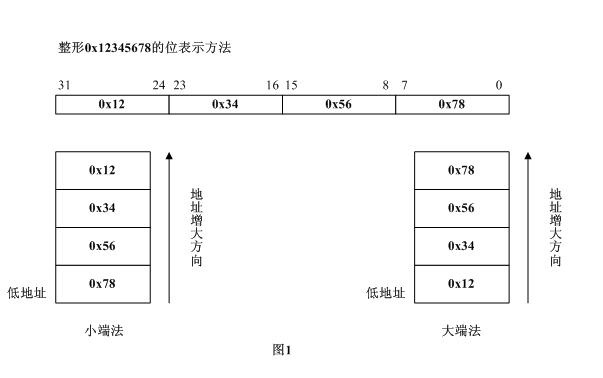
现在我们弄清了高低地址,接着来弄清高/低字节,如果我们有一个32位无符号整型0x12345678(呵呵,恰好是把上面的那4个字节buf看成一个整型),那么高位是什么,低位又是什么呢?其实很简单。在十进制中我们都说靠左边的是高位,靠右边的是低位,在其他进制也是如此。就拿 0x12345678来说,从高位到低位的字节依次是0x12、0x34、0x56和0x78。
高低地址和高低字节都弄清了。我们再来回顾一下Big-Endian和Little-Endian的定义,并用图示说明两种字节序:
以unsigned int value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value:
Big-Endian: 低地址存放高位,如下图:
栈底 (高地址)
---------------
buf[3] (0x78) -- 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) -- 高位
---------------
栈顶 (低地址)
Little-Endian: 低地址存放低位,如下图:
栈底 (高地址)
---------------
buf[3] (0x12) -- 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) -- 低位
---------------
栈顶 (低地址)
在现有的平台上Intel的X86采用的是Little-Endian,而像Sun的SPARC采用的就是Big-Endian。
三、例子
嵌入式系统开发者应该对Little-endian和Big-endian模式非常了解。采用Little-endian模式的CPU对操作数的存放方式是从低字节到高字节,而Big-endian模式对操作数的存放方式是从高字节到低字节。
例如,16bit宽的数0x1234在Little-endian模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
内存地址 存放内容
0x4001 0x12
0x4000 0x34
而在Big-endian模式CPU内存中的存放方式则为:
内存地址 存放内容
0x4001 0x34
0x4000 0x12
32bit宽的数0x12345678在Little-endian模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
内存地址 存放内容
0x4003 0x12
0x4002 0x34
0x4001 0x56
0x4000 0x78
而在Big-endian模式CPU内存中的存放方式则为:
内存地址 存放内容
0x4003 0x78
0x4002 0x56
0x4001 0x34
0x4000 0x12
2009-10-12 20:09 by cesc711, 824 阅读, 评论, 收藏, 编辑
刚才阅读代码的时候看到了一个字节排序函数,一时想不起具体用法了。想想学习linux下的网络编程也不少时间了,这些字节排序和转换的函数还是不太清楚,容易混淆。今天索性把这方面的知识汇总一下,争取以后能够熟练的认识和运用。
字节顺序函数:
小端字节序:将低序字节存储在起始地址。(linux)
大端字节序:将高序字节存储在起始地址。(网络字节序)
举个例子:对于整数0x12345678来说,在不同的系统中存放的方式如下图:
正是因为网际协议采取的是大端字节序,我们在编程的时候才需要考虑网络字节许和主机字节序之间的转换。下面是四个转换函数(在某些采用大端字节序的系统里面,这四个函数被定位空宏):
#include
<
netinet
/
in
.h
>
uint16_t htons(uint16_t host16bitvalue);
uint32_t htonl(uint32_t host32bitvalue);
//
均返回网络字节序
uint16_t ntohs(uint16_t net16bitvalue);
uint32_t ntohl(uint32_t net32bitvalue);
//
均返回主机字节序
地址转换函数:
下面介绍两组地址转换函数。首先是第一组:
#include
<
arpa
/
inet.h
>
int
inet_aton(
const
char
*
strptr,
struct
in_addr
*
addrptr);
//
返回:1——串有效,0——串有错
char
*
inet_ntoa(
struct
in_addr inaddr);
//
返回一个指向ASCII字串的指针
in_addr_t inet_addr(
const
char
*
strptr);
//
成功返回网络字节序,错误返回INADDR_NONE
接下来是第二组,这两个函数比较新,对于IPv4和IPv6都能处理。p的含义是presentation,代表ASCII字串。n的含意是numberic,代表网络地址值。
#include
<
netinet
/
in
.h
>
#define
INET_ADDRSTRLEN 16
#define
INET6_ADDRSTRLEN 46
#include
<
arpa
/
inet.h
>
int
inet_pton(
int
family,
const
char
*
strptr,
void
*
addrptr);
//
返回:1——成功,输入的不是有效表达格式,-1——出错
const
char
*
inet_ntop(
int
family,
const
void
*
addrptr,
char
*
strptr, size_t len);
//
返回:指向结果的指针——成功,NULL——出错
在计算机科学领域中,字节序是指存放多字节数据的字节(byte)的顺序,典型的情况是整数在内存中的存放方式和网络传输的传输顺序。不同的处理器所采用的字节序可能是不同的,例如: x86,6502, Z80, VAX,和 PDP-11都是采用小端字节序,而 Motorola 6800 、 68k, IBM POWER, 和 System/360则采用大端字节序。另外,网络协议通常也会规定其所采用的字节序,还有像java这样的语言,也是规定了字节序的(tcp/ip和java都是采用大端字节序)。
通常,系统中会提供ntohs、htons、ntohl、htonl这4个函数,已实现16位和32位本地字节序和网络字节序的转换。但是,目前好像还没有提供64位数据字节序的转换函数。所以,在这里自己动手写一个。
首先,我们要判断本地系统所采用的字节序:
- #define BigEndian 1
- #define LittleEndian 0
- static bool BigEndianTest()
- {
-
-
-
-
-
-
- const __int16 n = 1;
- if(*(char *)&n)
- {
- return LittleEndian;
- }
- return BigEndian;
- }
当然这里可以再优化一下,写成宏定义。
然后,定义16、32、64位的调位函数。这里就是字节“搬家”而已。
- #define Swap16(s) ((((s) & 0xff) << 8) | (((s) >> 8) & 0xff))
- #define Swap32(l) (((l) >> 24) | /
- (((l) & 0x00ff0000) >> 8) | /
- (((l) & 0x0000ff00) << 8) | /
- ((l) << 24))
- #define Swap64(ll) (((ll) >> 56) |/
- (((ll) & 0x00ff000000000000) >> 40) |/
- (((ll) & 0x0000ff0000000000) >> 24) |/
- (((ll) & 0x000000ff00000000) >> 8) |/
- (((ll) & 0x00000000ff000000) << 8) |/
- (((ll) & 0x0000000000ff0000) << 24) |/
- (((ll) & 0x000000000000ff00) << 40) |/
- (((ll) << 56)))
最后,
- #define BigEndian_16(s) BigEndianTest() ? s : Swap16(s)
- #define LittleEndian_16(s) BigEndianTest() ? Swap16(s) : s
- #define BigEndian_32(l) BigEndianTest() ? l : Swap32(l)
- #define LittleEndian_32(l) BigEndianTest() ? Swap32(l) : l
- #define BigEndian_64(ll) BigEndianTest() ? ll : Swap64(ll)
- #define LittleEndian_64(ll) BigEndianTest() ? Swap64(ll) : ll
现在,我们来测试一下:
- int main()
- {
- unsigned __int16 i16 = 0xabcd;
- unsigned __int32 i32 = 0x0a0b0c0d;
- unsigned __int64 i64 = 0x0102030405060708;
- printf("System is %s/n",BigEndianTest() ? "BigEndian" : "LittleEndian" );
- printf("__int16 i16 = 0x%x, BigEndian:0x%x htons:0x%x, LittleEndian:0x%x ntohs:0x%x/n",
- i16,BigEndian_16(i16),htons(i16),LittleEndian_16(i16),ntohs(BigEndian_16(i16)));
- printf("__int32 i32 = 0x%x, BigEndian:0x%x htons:0x%x, LittleEndian:0x%x ntohs:0x%x/n",
- i32,BigEndian_32(i32),htonl(i32),LittleEndian_32(i32),ntohl(BigEndian_32(i32)));
- printf("__int64 i64 = 0x%llx, BigEndian:0x%llx, LittleEndian:0x%llx/n",i64,
- BigEndian_64(i64),LittleEndian_64(i64));
- getchar();
- return 0;
- }
运行结果如下:
- System is LittleEndian
- __int16 i16 = 0xabcd, BigEndian:0xcdab htons:0xcdab, LittleEndian:0xabcd ntohs:0
- xabcd
- __int32 i32 = 0xa0b0c0d, BigEndian:0xd0c0b0a htons:0xd0c0b0a, LittleEndian:0xa0b
- 0c0d ntohs:0xa0b0c0d
- __int64 i64 = 0x102030405060708, BigEndian:0x807060504030201, LittleEndian:0x102
- 030405060708








 #include
<
arpa
/
inet.h
>
#include
<
arpa
/
inet.h
>














 6094
6094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









