







什么是不良数据?
首先我们要知道什么是不良数据,不良数据也就是坏的数据,不可用的数据,比如说不再有效的地址和职位、拼写错误的姓名、旧电话号码或一开始就不正确的损坏数据等等;
衡量数据质量的6个关键维度:
(1) 准确性 - 正确的账户余额是一元还是一百万元?
(2) 完整性–有关数据是否完整地描述了事实,或缺少关键要素,如一个人的名字?
(3) 一致性–这与系统中其他地方存储的数据点是否一致?
(4) 新鲜度–你所处理的数据元素有多老?这是否反映了当前的业务,或者它已经过时了?
(5) 有效性 - 数据是否遵循并符合模式定义,是否遵循业务规则,或者它是一个不可用的格式?
(6) 唯一性–这个信息是否是唯一出现在数据库中的实例?
所以坏数据主要有以下几种类型:不完整的数据;过时的数据;无法访问的数据(通常会形成企业内部的数据孤岛);不合逻辑的数据;未经同意收集的数据,不可信的数据;重复的数据;不一致的数据;
想要识别坏数据,就得进行数据验证(一般可能会使用ETL验证脚本进行数据校验,但是它无法处理传入的实时数据流,并且速度很慢),数据至少要三个月就清理一次,检查数据字段中的无效字符,例如电话号码中的字母或地址中的奇怪字符。将有效数据移至有效数据文件,将无效数据移至无效数据文件。企业需要在数据管道中建立检查点,建立一个早期预警系统的基础,在数据生命周期的每个阶段测试质量和一致性。他们必须使这些系统与测试计划保持一致,并且测试结果必须确定应用程序和数据存储库的问题所在。可以处理错误数据的应用程序应该知道数据何时不再可使用,并且生产应用程序组应该立即采取行动。除此之外,还需要注意以下三点:
防止、预先阻止数据模式的不符合项,持续验证数据,最好是自动验证。
发生数据错误时,请确保将故障原因与错误一起报告,并可能提供解决问题的方法。
没有上下文信息的故障通知永远不足以解决问题或防止问题再次发生。
如何自动清理和验证实时数据流
您可以将虹科的数据可观察性平台与 Kafka 一起使用,可以让您更好地控制数据管道,并帮助您监控 Kafka 生态系统中的内部事件,以实现更快的吞吐量和更好的稳定性。
您可以通过将 Kafka 服务器连接到一个或多个传入数据源(例如数据库、传感器、网站、附属机构和其他第三方源)来清理和验证实时数据流。数据源通过Kafka Connect连接到 Kafka 服务器。如下所示,您可以从 Kafka 服务器流式传输任意数量的数据流。
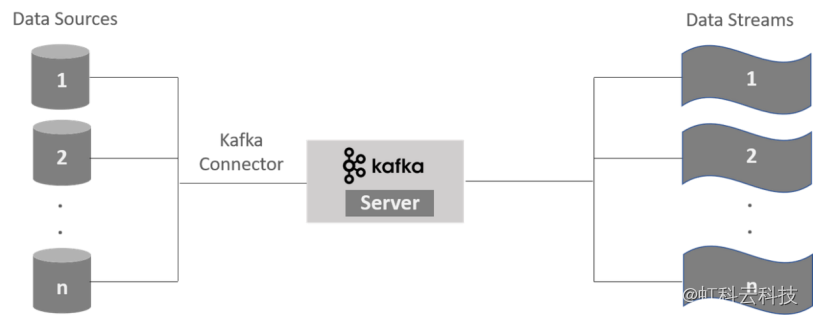
使用虹科的数据可观察性平台进行 Kafka 流式传输可让您分析存储在 Kafka 集群中的数据并监控实时数据流的分布。事件是管道中任何出现的流或消息。使用虹科的数据可观察性平台,您可以监控 Kafka 生态系统中的内部事件,以获得更快的吞吐量和更好的稳定性。
无需依赖 ETL 验证脚本来清理和验证传入数据,您可以使用虹科的数据可观察性平台自动实时标记不完整、不正确和不准确的数据,而无需任何手动干预。
虹科的数据可观察性平台与您环境中的所有数据系统集成。这包括 Spark 等处理引擎,以及 Amazon S3、Hive、HBase、Redshift 和 Snowflake 等现代存储/查询平台,它还与MySQL、PostgreSQL 和 Oracle 数据库等传统数据存储系统集成。
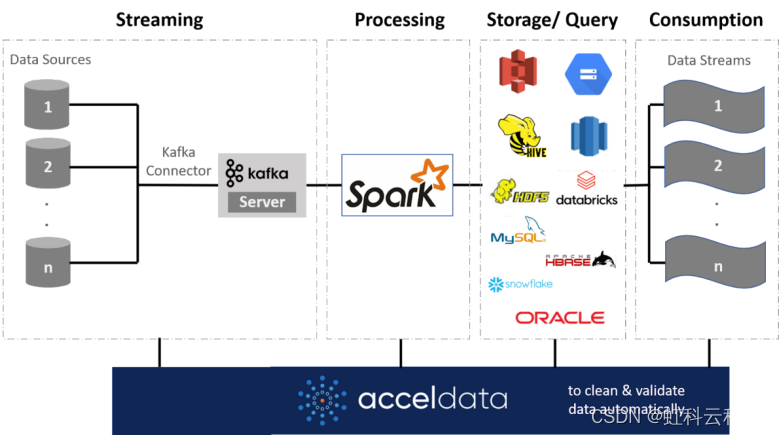
使用HK-Pulse等数据可观察性解决方案利用 AI 功能实现:
- 实时自动清理和验证传入的数据流,因此数据团队不再需要编写耗时的手动脚本,而可以专注于优化基础架构和确保可靠性。
- 自动检测异常并自动进行预防性维护。它还可以加速根本原因分析,并根据历史比较、环境健康和资源争用关联事件。
- 通过以下方式自动分析意外行为变化的根本原因:
(1)以可按严重性或服务搜索的时间直方图形式获取所有应用程序日志的概览
(2)比较不同的查询及其运行时/配置参数
(3)更好地了解不同查询的队列利用率
(4)获取自动建议以纠正慢查询、预测资源可用性和适当调整容器大小
让企业不再依赖低效的 ETL 验证脚本,构建属于自己的数据质量监控系统。















 1709
1709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









