









什么是虚拟机
虚拟机是借助于操作系统对物理机器的一种模拟。但是我们今天所讲述的虚拟机概念比较狭义,与vmware或者virtual-box不同,而是针对具体语言所实现的虚拟机。例如在JVM或者CPython中,JAVA或者python源码会被编译成相关字节码,然后在对应虚拟机上运行,JVM或CPython会对这些字节码进行取指令,译码,执行,结果回写等操作,这些步骤和真实物理机器上的概念都很相似。相对应的二进制指令是在物理机器上运行,物理机器从内存中取指令,通过总线传输到CPU,然后译码、执行、结果存储。
虚拟机为了能够执行字节码,需要模拟出物理CPU能够执行的相关操作,与虚拟机实现相关的概念如下:
(1)将源码编译成VM所能执行的具体字节码。
(2)字节码格式(指令格式),例如三元式,树还是前缀波兰式。
(3)函数调用相关的栈结构,函数的入口,出口,返回以及如何传参。还有为了能够顺利返回所需的相关栈帧信息如何布置。
(4)一个“指令指针”,指向下一条待执行的指令(内存中),对应物理机器的EIP。
(5)一个虚拟“CPU”-指令调度器,
- 获取下一条指令
- 对操作数进行解码
- 执行这条指令
这三点是解释器执行字节码最重要的开销。
虚拟机的实现方式
如今虚拟机的实现方式有两种,基于栈的和基于寄存器的,这两种实现方式各有优劣,也都有标志性的产品。基于栈的虚拟机,有JVM,CPython以及.Net CLR。基于寄存器的,有Dalvik以及Lua5.0,另外Perl听说也要改为基于寄存器方式。无论这两种方式实现机制如何,都要实现以下几点:
- 取指令,其中指令来源于内存
- 译码,决定指令类型(执行何种操作)。另外译码的过程要包括从内存中取操作数
- 执行。指令译码后,被虚拟机执行(其实最终都会借助于物理机资源)
- 存储计算结果
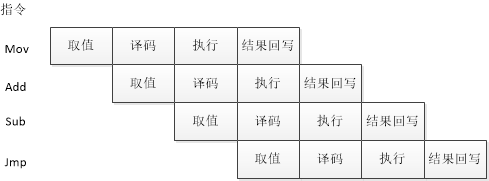
其实这和物理机CPU的执行是很相似的,都包括取值,译码,执行,回写等步骤。但是不同的一点是虚拟机应该模仿不出流水线,例如在当前指令译码完成之后,CPU中的译码部件处于空闲状态,可以用来对下一条指令进行译码,所以流水线有多少级就相当于可以并行执行多少指令。当然中间还有些指令相关和乱序的概念,这里就不详说了。
下图中一个典型的指令流水线结构,由于虚拟机在操作系统上通过程序模拟,遵循冯诺依曼结构顺序执行的,应该很难实现出流水线结构。
基于栈的虚拟机
基于栈的虚拟机有一个操作数栈的概念,虚拟机在进行真正的运算时都是直接与操作数栈(operand stack)进行交互,不能直接操作内存中数据(其实这句话不严谨的,虚拟机的操作数栈也是布局在内存上的),也就是说不管进行何种操作都要通过操作数栈来进行,即使是数据传递这种简单的操作。这样做的直接好处就是虚拟机可以无视具体的物理架构,特别是寄存器。但缺点也显而易见,就是速度慢,因为无论什么操作都要通过操作数栈这一结构。
由于执行时默认都是从操作数栈上取数据,那么就无需指定操作数。例如,x86汇编”ADD EAX, EBX”,就需要指定这次运算需要从什么地方取操作数,执行完结果存放在何处。但是基于栈的虚拟机的指令就无需指定,例如加法操作就一个简单的”Add”就可以了,因为默认操作数存放在操作数栈上,直接从操作数栈上pop出两条数据直接执行加法运算,运算后的结果默认存放在栈顶。其中操作数栈(operand stack)的深度由编译器静态确定,方便给栈帧预分配空间。这个和不能再栈上定义变长数组相似(其实这句话不严谨的,栈上分配变长数组,需要编译器的支持,分配在栈顶),由于局部变量的地址只能在编译期(compile time)确定针对当前栈帧的offset,如果中间有一个变量是一个变长数组的话,那么后面变量的offset就无法确定了(vector的数据是分配在堆上的,自己控制)。
例如执行”a = b + c”,在基于栈的虚拟机上字节码指令如下所示:
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
由于操作数都是隐式地,所以指令可以做的很短,一般都是一个或者两个字节。但是显而易见就是指令条数会显著增加。而基于寄存器虚拟机执行该操作只有一条指令,
- 1
- 1
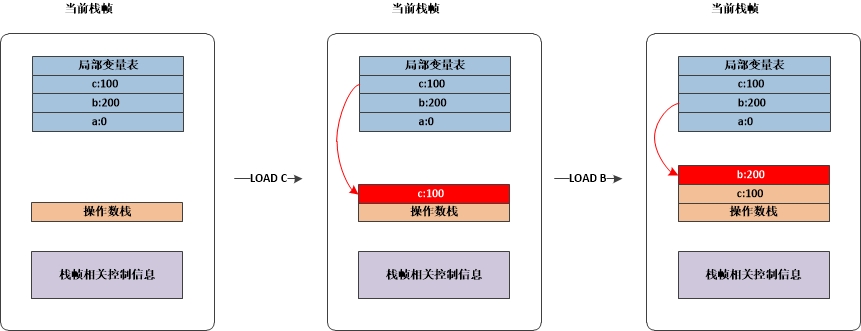
其中a,b,c都是虚拟寄存器。操作数栈上的变化如下图所示:
首先从符号表上读取数据压入操作数栈,
然后从栈中弹出操作数执行加法运算,这步操作有物理机器执行,如下图所示:
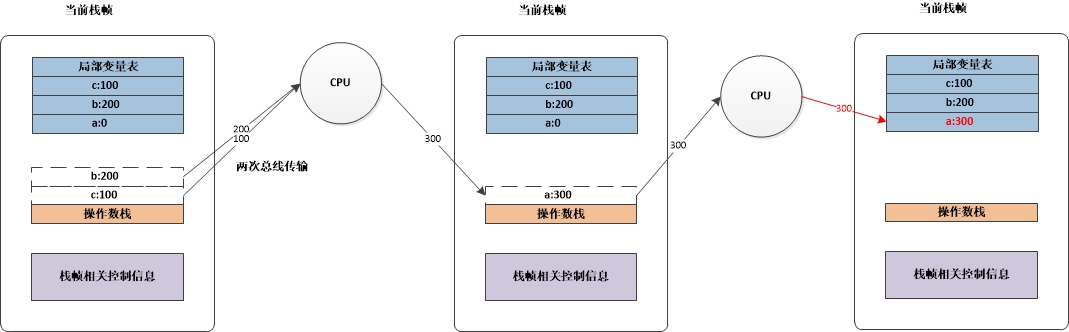
从图示中可以看出,数据从局部变量表中还要经过一次操作数栈的操作,注意操作数栈和局部变量表都是存放在内存上,内存到内存的数据传输在x86的机器上都是要经过一次数据总线传输的。可以得出一次简单的加法基本上需要9次数据传输,想想都很慢。
但是基于栈的虚拟机优点就是可移植,寄存器由硬件直接提供。使用栈架构的指令集,用户程序(编译后的字节码)不会直接使用硬件中的寄存器,同时为了提高运行时的速度,可以将一些访问比较频繁的数据存放到寄存器中以获取尽量好的性能。另外,基于栈的虚拟机中指令更加紧凑,一个字节或者两个字节即可存储,同时编译器实现也比较简单,不用进行寄存器分配。寄存器分配是一门大学问。
基于寄存器的虚拟机
前面提到过基于栈的虚拟机,这里我们简要介绍一下基于寄存器的虚拟机运行机制。
基于寄存器的虚拟机中没有操作数栈的概念,但是有很多虚拟寄存器,一般情况下这些寄存器(操作数)都是别名,需要执行引擎对这些寄存器(操作数)的解析,找出操作数的具体位置,然后取出操作数进行运算。
既然是虚拟寄存器,那么肯定不在CPU中(想想也不应该在CPU中,虚拟机的根本目的就是跨平台和兼容性),其实和操作数栈相同,这些寄存器也存放在运行时栈中,本质上就是一个数组。
新的虚拟机也用栈分配活动记录,寄存器就在该活动记录中。当进入Lua程序的函数体时,函数从栈中分配一个足以容纳该函数所有寄存器的活动记录。函数的所有局部变量都各占据一个寄存器。因此,存取局部变量是相当高效的。
上面就是Lua虚拟机对寄存器的相关描述,示意图如下:
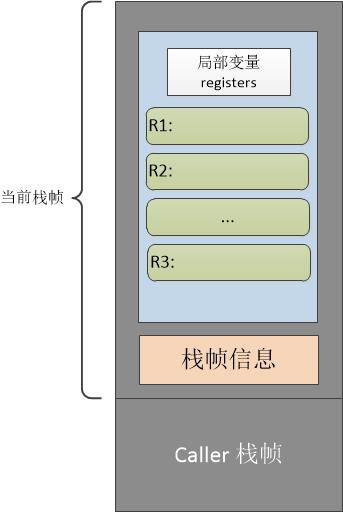
从上图中我们可以看到,其实“寄存器”的概念只是当前栈帧中一块连续的内存区域。这些数据在运算的时候,直接送入物理CPU进行计算,无需再传送到operand stack上然后再进行运算。例如”ADD R3, R2, R1”的示意图就如下所示:
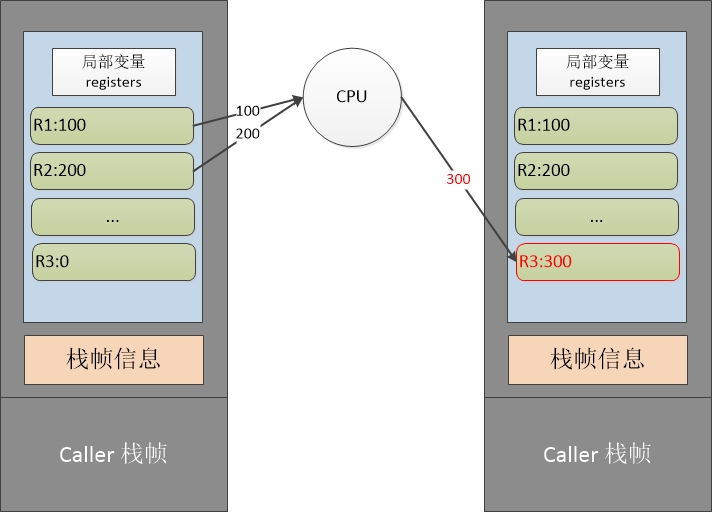
其实”ADD R3, R2, R1”还要经过译码的一个过程,当然当前这条指令的种类和操作数由虚拟机进行解释。后面我们会看到,在有些实现中,有一个很大的switch-case来进行指令的分派及真正的运算过程。
下图是Lua虚拟机的一些指令,该图片来自这篇文章,中译文这里。
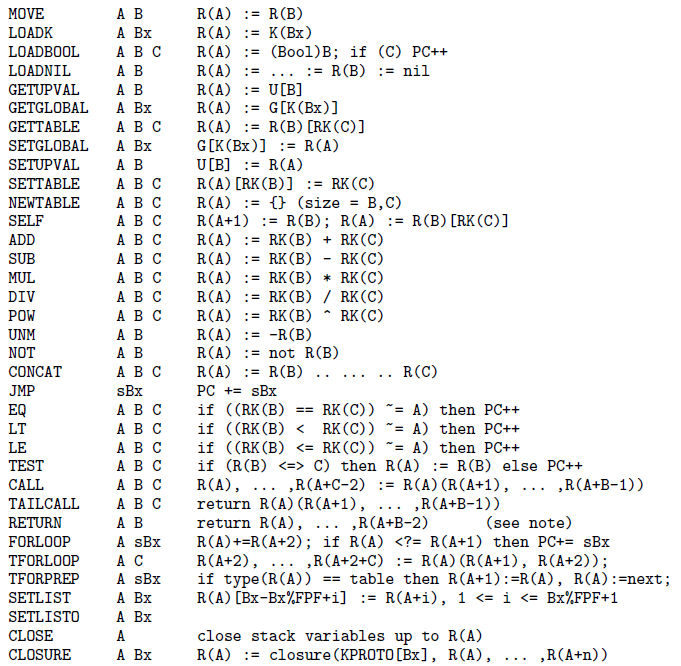
使用寄存器式虚拟机没有基于栈的虚拟机在拷贝数据而使用的大量的出入栈(push/pop)指令。同时指令更紧凑更简洁。但是由于显示指定了操作数,所以基于寄存器的代码会比基于栈的代码要大,但是由于指令数量的减少,其实没有大多少。
栈式虚拟机 VS 寄存器式虚拟机
(1)指令条数:栈式虚拟机多
(2)代码尺寸:栈式虚拟机
(3)移植性:栈式虚拟机移植性更好
(4)指令优化:寄存器式虚拟机更能优化
| 栈式 VS 寄存器式 | 对比 |
|---|---|
| 指令条数 | 栈式 > 寄存器式 |
| 代码尺寸 | 栈式 < 寄存器式 |
| 移植性 | 栈式优于寄存器式 |
| 指令优化 | 栈式更不易优化 |
| 解释器执行速度 | 栈式解释器速度稍慢 |
| 代码生成难度 | 栈式简单 |
| 简易实现中的数据移动次数 | 栈式移动次数多 |
解释器最重要的开销在于指令调度(instruction dispatch),指令调度主要操作包括从内存中取出指令,然后跳转到解释器相对应的代码段,然后执行这条指令。其中一个简易实现就是使用switch-based的方式来进行,这种方式简单易实现,另外任何语言都有相应的switch语句。switch-based的指令调度,通过一个死循环不断的从内存取出指令来执行,针对不同的指令选择不同的执行方式。
一种JVM基于SBD实现方式如下图所示:
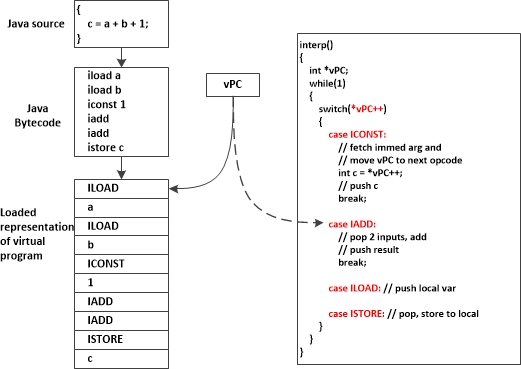
注:图片来自这里
这种方式实现加单,代码移植性好,但是有一个缺点就是分支预测失效的概率比较高。
现在的CPU都是基于流水线结构的,间接跳转指令的跳转结果需要等到执行级才能知晓,如果预测失败需要排空流水线,流水线级数越多分支预测失败导致流水线排空的时间越长。
由于编译后的指令是随机的,不太可能提取出预测模式。《》















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









