







深度学习是计算机领域中目前非常火的话题,不仅在学术界有很多论文,在业界也有很多实际运用。本篇博客主要介绍了三种基本的深度学习的架构,并对深度学习的原理作了简单的描述。翻译自:原文地址
简介
机器学习技术在当代社会已经发挥了很大的作用:从网络搜索到社交网络中的内容过滤到电子商务网站的个性化推荐,它正在快速的出现在用户的消费品中,如摄像机和智能手机。机器学习系统可以用来识别图像中的物体,将语音转变成文字,匹配用户感兴趣的新闻、消息和产品等,也可以选择相关的搜索结果。这些应用越来越多的使用一种叫做“深度学习(Deep Learning)”的技术。
深度学习(Deep Learning)(也称为深度结构学习【Deep Structured Learning】、层次学习【Hierarchical Learning】或者是深度机器学习【Deep Machine Learning】)是一类算法集合,是机器学习的一个分支。它尝试为数据的高层次摘要进行建模。以一个简单的例子来说,假设你有两组神经元,一个是接受输入的信号,一个是发送输出的信号。当输入层接收到输入信号的时候,它将输入层做一个简单的修改并传递给下一层。在一个深度网络中,输入层与输出层之间可以有很多的层(这些层并不是由神经元组成的,但是它可以以神经元的方式理解),允许算法使用多个处理层,并可以对这些层的结果进行线性和非线性的转换。
译者补充:深度学习的思想与人工神经网络思想是一致的。总的来说,神经网络是一种机器学习架构,所有的个体单元以权重的方式连接在一起,且这些权重是通过网络来训练的,那么它就可以称之为神经网络算法。人工神经网络算法的思想来源于模仿人类大脑思考的方式。人类大脑是通过神经系统得到输入信号再作出相应反映的,而接受外部刺激的方式是用神经元接受神经末梢转换的电信号。那么,我们希望通过人造神经元的方式模拟大脑的思考,这就产生了人工神经网络了。人工神经元组成了人工神经网络的计算单元,而人工神经网络结构描述了这些神经元的连接方式。我们可以采用层的方式组织神经元,层与层之间可以互相连接。以前受制于很多因素,我们无法添加很多层,而现在随着算法的更新、数据量的增加以及GPU的发展,我们可以用很多的层来开发神经网络,这就产生了深度神经网络。而深度学习其实就是深度神经网络的一个代名词。关于人工神经网络算法可以参考人工神经网络(Artificial Neural Network)算法简介。
近些年来,深度学习通过在某些任务中极佳的表现正在改革机器学习。深度学习方法在会话识别、图像识别、对象侦测以及如药物发现和基因组学等领域表现出了惊人的准确性。但是,“深度学习”这个词语很古老,它在1986年由Dechter在机器学习领域提出,然后在2000年有Aizenberg等人引入到人工神经网络中。而现在,由于Alex Krizhevsky在2012年使用卷积网络结构赢得了ImageNet比赛之后受到大家的瞩目。
深度学习架构
1、生成式深度架构(Generative deep architectures),主要是用来描述具有高阶相关性的可观测数据或者是可见的对象的特征,主要用于模式分析或者是总和的目的,或者是描述这些数据与他们的类别之间的联合分布。(其实就是类似与生成模型)
2、判别式深度架构(Discriminative deep architectures),主要用于提供模式分类的判别能力,经常用来描述在可见数据条件下物体的后验类别的概率。(类似于判别模型)
3、混合深度架构(Hybrid deep architectures),目标是分类,但是和生成结构混合在一起了。比如以正在或者优化的方式引入生成模型的结果,或者使用判别标注来学习生成模型的参数。
尽管上述深度学习架构的分类比较复杂,其实实际中对应的模型的例子就是深度前馈网络,卷积网络和递归神经网络(Deep feed-forward networks, Convolution networks and Recurrent Networks)。
深度前馈网络(Deep feed-forward networks)
深度前馈网络也叫做前馈神经网络,或者是多层感知机(Multilayer Perceptrons,MLPs),是深度学习模型中的精粹。
前馈网络的目标是近似某些函数。例如,对于一个分类器,y=f(x)
使得产生最好的函数近似。
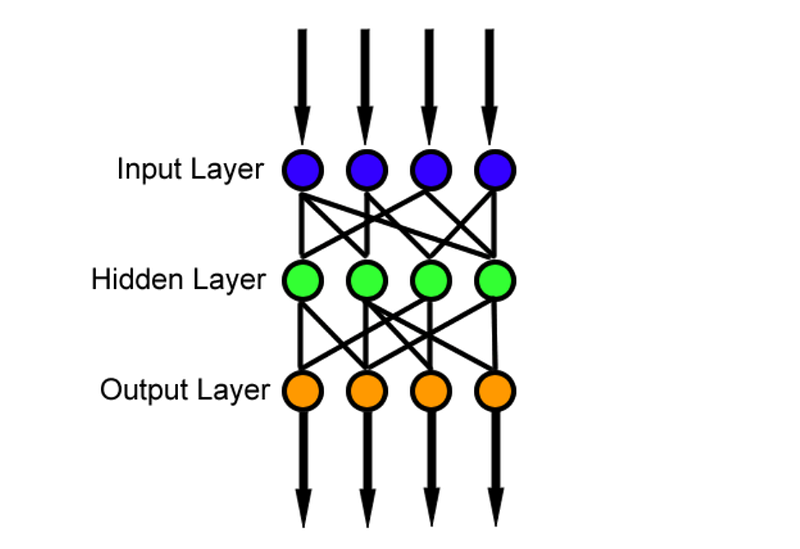
简而言之,神经网络可以定义成输入层,隐含层和输出层。其中,输入层接受数据,隐含层处理数据,输出层则输出最终结果。这个信息流就是接受x
,通过处理函数 f,在达到输出 y。这个模型并没有任何的反馈连接,因此被称为前馈网络。模型如下图所示:
卷积神经网络(Convolution Neural Networks)
在机器学习中,卷积神经网络(简称CNN或者ConvNet)是一种前馈神经网络,它的神经元的连接是启发于动物视觉皮层。单个皮质神经元可以对某个有限空间区域的刺激作出反应。这个有限空间可以称为接受域。不同的神经元的接受域可以重叠,从组成了所有的可见区域。那么,一个神经元对某个接受域内的刺激作出反应,在数学上可以使用卷积操作来近似。也就是说,卷积神经网络是受到生物处理的启发,设计使用最少的预处理的多层感知机的变体。
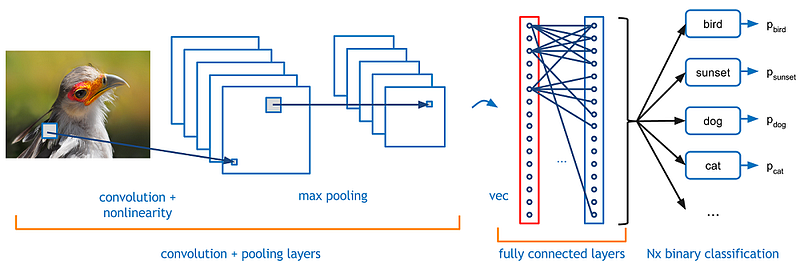
卷积神经网络在图像和视频识别、推荐系统以及自然语言处理中都有广泛的运用。
LeNet是早期推动深度学习发展的卷积神经网络之一。这是Yann LeCun从1988年以来进行的许多词的成功迭代后得到的开创性工作,称之为LeNet5。在当时,LeNet架构主要用来进行字符识别的工作,如读取邮编,数字等。如下图所示,卷积神经网络主要包含四块:
- 卷积层(Convolutional Layer)
- 激活函数(Activation Function)
- 池化层(Pooling Layer)
- 全连接层(Fully Connected Layer)

卷积层(Convolutional Layer)
卷积层是基于单词“卷积(Convolution)”而来,这是一种数学上的操作,它是对两个变量f\*g
进行操作产生第三个变量。它和互相关(cross-correlation)很像。卷积层的输入是一个 m×m×r图像,其中m是图像的高度和宽度,r是通道的数量,例如,一个RGB图像的通道是3,即 r=3。卷积层有 k个滤波器【filters】(或者称之为核【kernel】),其大小是 n×n×q,这里的 n是比图像维度小的一个数值, q既可以等于通道数量,也可以小于通道数量,具体根据不同的滤波器来定。滤波器的大小导致了
激活函数(Activation Function)
为了实现复杂的映射函数,我们需要使用激活函数。它可以带来非线性的结果,而非线性可以使得我们很好的拟合各种函数。同时,激活函数对于压缩来自神经元的无界线性加权和也是重要的。
激活函数很重要,它可以避免我们把大的数值在高层次处理中进行累加。激活函数有很多,常用的有sigmoid,tanh和ReLU。
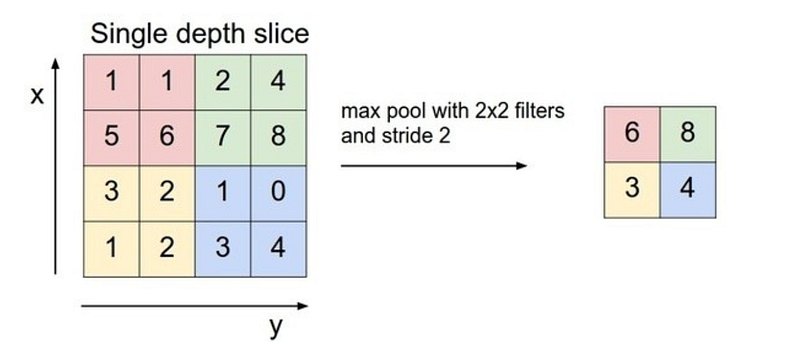
池化层(Pooling Layer)
池化是一个基于样本的离散化过程。其目的上降低输入表示的采样(这里的输入可以是图像,隐层的输出等),减少它们的维度,并允许我们假设特征已经被包含在了子区域中。
这部分的作用是通过提供一种抽象的形式表示来帮助过拟合表示。同样的,它也通过减少了参数的数量降低了计算的复杂度并为内部的表示提供一个基本的不变性的转换。
目前最常用的池化技术有Max-Pooling、Min-Pooling和Average-Pooling。下图是2*2滤波器的Ma-Pooling操作示意图。
全连接层(Fully Connected Layer)
“全连接”的意思是指先前的层里面的所有的神经元都与后一个层里面的所有的神经元相连。全连接层是一种传统的多层感知机,在输出层,它使用softmax激活函数或者其他激活函数。
递归神经网络(Recurrent Neural Networks)
在传统的神经网络中,我们假设所有的输入之间相互独立。但是对于很多任务来说,这并不是一个好的主意。如果你想知道一个句子中下一个单词是什么,你最好知道之前的单词是什么。RNN之所以叫RNN就是它对一个序列中所有的元素都执行相同的任务,所有的输出都依赖于先前的计算。另一种思考RNN的方式是它会记住所有之前的计算的信息。
一个RNN里面有很多循环,它可以携带从输入中带来的信息。如下图所示,x_t
是一种输入,A是RNN里面的一部分, h_t是输出。本质上,您可以从句子中输入文字,甚至还可以从字符串中输入 x_t格式的字符,通过RNN可以提供一个 h_t。 RNN的一些类型是LSTM,双向RNN,GRU等。

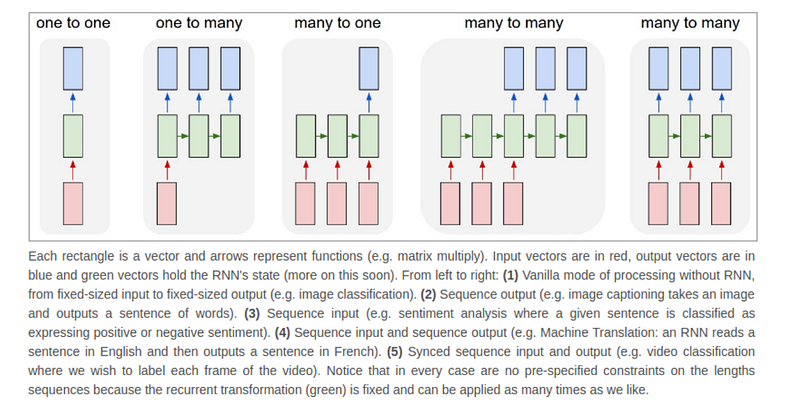
由于任何输入和输出都可以在RNN中变成一对一或者多对多的形式,RNN可以用在自然语言处理、机器翻译、语言模型、图像识别、视频分析、图像生成、验证码识别等领域。下图展示了RNN可能的结构以及对模型的解释。
应用
深度学习有很多应用,很多特别的问题也可以通过深度学习解决。一些深度学习的应用举例如下:
黑白图像的着色
深度学习可以用来根据对象及其情景来为图片上色,而且结果很像人类的着色结果。这中解决方案使用了很大的卷积神经网络和有监督的层来重新创造颜色。
机器翻译
深度学习可以对未经处理的语言序列进行翻译,它使得算法可以学习单词之间的依赖关系,并将其映射到一种新的语言中。大规模的LSTM的RNN网络可以用来做这种处理。
图像中的对象分类与检测
这种任务需要将图像分成之前我们所知道的某一种类别中。目前这类任务最好的结果是使用超大规模的卷积神经网络实现的。突破性的进展是Alex Krizhevsky等人在ImageNet比赛中使用的AlexNet模型。
自动产生手写体
这种任务是先给定一些手写的文字,然后尝试生成新的类似的手写的结果。首先是人用笔在纸上手写一些文字,然后根据写字的笔迹作为语料来训练模型,并最终学习产生新的内容。
自动玩游戏
这项任务是根据电脑屏幕的图像,来决定如何玩游戏。这种很难的任务是深度强化模型的研究领域,主要的突破是DeepMind团队的成果。
聊天机器人
一种基于sequence to sequence的模型来创造一个聊天机器人,用以回答某些问题。它是根据大量的实际的会话数据集产生的。想了解详情,可以参考:https://medium.com/shridhar743/generative-model-chatbots-e422ab08461e
结论
从本篇博客来看,由于模仿了人类大脑,深度学习可以运用在很多领域中。目前有很多领域都在研究使用深度学习解决问题。尽管目前信任是个问题,但是它终将被解决。
参考文献可以见原文末尾:原文地址















 1815
1815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









