






Java集合
说List Set Map 之间的区别
List:有序,可重复,存储单个对象。
Set:无序(或特定实现有序),不可重复,存储单个对象。
-
HashSet:无序,遍历顺序不确定。
-
LinkedHashSet:有序,遍历顺序与插入顺序一致。
-
TreeSet:有序,遍历顺序按元素的自然顺序或指定的排序规则排列。
因此,如果你需要一个无序集合,HashSet是常用的选择;如果你需要维持插入顺序或排序顺序,可以选择LinkedHashSet或TreeSet。
Map:键值对存储,键无序(或特定实现有序),键不可重复,值可重复。
这些集合在java中都有那些对应实现类 以及底层数据结构
-
List:
-
ArrayList:动态数组,适合频繁读取场景。 -
LinkedList:双向链表,适合频繁插入删除场景。 -
Vector:线程安全的动态数组,适合多线程环境。 -
Stack:基于Vector实现的LIFO栈,适合栈结构场景。
-
-
Set:
-
HashSet:哈希表,无序且唯一,适合快速去重。 -
LinkedHashSet:链表+哈希表,有序且唯一,适合有序去重。 -
TreeSet:红黑树,排序且唯一,适合有序集合。
-
-
Map:
-
HashMap:哈希表,无序,适合快速存取键值对。 -
LinkedHashMap:链表+哈希表,有序,适合有序存取键值对。 -
TreeMap:红黑树,排序,适合有序映射表。 -
Hashtable:线程安全的哈希表,适合早期多线程代码。 -
ConcurrentHashMap:分段锁哈希表,适合高效多线程环境。
-
不同的集合类有不同的底层数据结构和特性,选择合适的集合类可以有效提高程序的性能和可维护性。
ArrayList 和 Array(数组)的区别?
ArrayList 内部基于动态数组实现,比 Array(静态数组) 使用起来更加灵活:
-
ArrayList会根据实际存储的元素动态地扩容或缩容,而Array被创建之后就不能改变它的长度了。 -
ArrayList允许你使用泛型来确保类型安全,Array则不可以。 -
ArrayList中只能存储对象。对于基本类型数据,需要使用其对应的包装类(如 Integer、Double 等)。Array可以直接存储基本类型数据,也可以存储对象。 -
ArrayList支持插入、删除、遍历等常见操作,并且提供了丰富的 API 操作方法,比如add()、remove()等。Array只是一个固定长度的数组,只能按照下标访问其中的元素,不具备动态添加、删除元素的能力。 -
ArrayList创建时不需要指定大小,而Array创建时必须指定大小。
ArrayList和linkedList的区别
-
是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
-
底层数据结构: ArrayList 底层使用的是 Object 数组;LinkedList 底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
-
插入和删除是否受元素位置的影响: ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element)),时间复杂度就为 O(n)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 LinkedList 采用链表存储,所以在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、 removeLast()),时间复杂度为 O(1),如果是要在指定位置 i 插入和删除元素的话(add(int index, E element),remove(Object o),remove(int index)), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入和删除。
-
是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而 ArrayList(实现了 RandomAccess 接口) 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。
-
内存空间占用: ArrayList 的空间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
hashMap的底层数据结构 扩容处理 不同版本下底层数据结构的不同
JDK1.8 之前
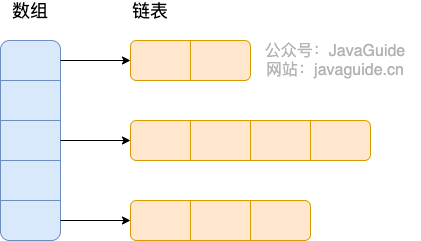
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashcode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
HashMap 中的扰动函数(hash 方法)是用来优化哈希值的分布。通过对原始的 hashCode() 进行额外处理,
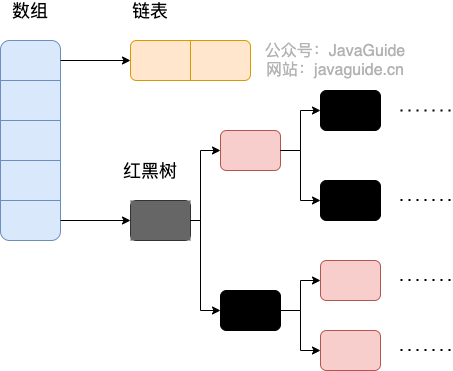
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
-
底层数据结构: JDK1.7 的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟 HashMap1.8 的结构一样,数组+链表/红黑二叉树。
-
Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
-
实现线程安全的方式(重要): 在 JDK1.7 的时候,ConcurrentHashMap 对整个桶数组进行了分割分段(Segment,分段锁),每一把锁只锁容器其中一部分数据(下面有示意图),多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
-
到了 JDK1.8 的时候,ConcurrentHashMap 已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6 以后 synchronized 锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;
-
Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









