







【前言】因为一个需求需要测试算法的可伸缩性,即需要测试不同规模的集群,算法的运行情况,因此我就试着去动态往正在运行的集群中添加节点,然后摸索着发现也没那么难,很简单的一件事情其实,下面简单的记录了一下,希望对大家有所帮助!
在hadoop集群中,HDFS分布式文件系统和mapreduce计算框架是可以独立部署安装的,在hadoop2中体现的也是非常明显的,如果需要只使用部分结点进行计算,那么可以采用的方法如下:
集群的分布式存储系统HDFS可以独立部署使用,MR计算框架可以选择性的部署安装,只需要单独启动resourcemanager和需要使用的结点上的nodemanager即可,查找命令可以参考/hadoop2/sbin/start-yarn.sh中是如何写的就可以找到答案了!
在hadoop2/sbin/start-yarn.sh脚本中,写了启动resourcemanager和所有节点上的nodemanager,所以只需要参考该脚本文件,就能得到启动单个节点上的nodemanager的方法: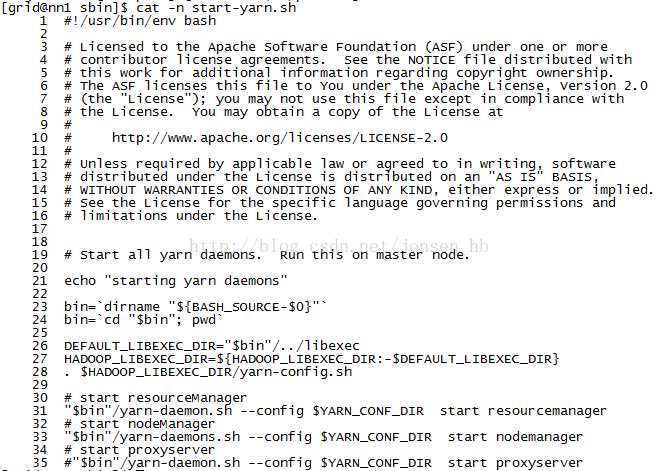
从第30行开始为启动resourcemanager的脚本命令,从中可以看到,单独启动resourcemanager和nodemanager是在yarn-daemon.sh脚本中,使用start + 要启动的进程即可。
如果是这种需求的话就要注意了,在启动集群的时候不要使用start-yarn.sh脚本来启动resourcemanager,这样的话每个结点的nodemanager都会被启动!
【注】这种情况下所谓的使用部分结点进行计算是仅开启部分nodemanager,如果不能满足需求的话,那就是另一种情况了,就是动态的增加节点!
下面介绍下如何动态的添加结点(注意一般是不会出现动态的减少结点的,这样的话会打乱HDFS上已经存在的文件,是的分布式计算受影响,而增加节点后只需要执行下集群HDFS的负载均衡即可,这样对文件系统不会有影响。
增加结点的步骤(集群本身是运行状态):
集群状态描述(自动HA配置)
namenode两台:nn1 nn2
zookeeper集群:d1、d2、d3
journalnode:d4、d5、d6
运行中的datanode:d1、d2、d3
需要添加的datanode:d4、d5
修改nn1上的slaves文件,将d4、d5添加进文件中,然后使用scp命令将slaves文件分发到其余的节点的对于位置,然后再在d4和d5节点上单独启动datanode和journalnode:
hadoop2/sbin/hadoop-daemon.sh startdatanode
hadoop2/sbin/yarn-daemon.sh startjournalnode
然后执行下集群HDFS的负载均衡即可完成动态添加节点了!命令:
hadoop2/bin/hdfsbalancer














 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









