







一、安装
二、scala shell
./bin/spark-shell
scala> val lines = sc.textFile("/Users/study/spark/derby.log")
lines: org.apache.spark.rdd.RDD[String] = /Users/Documents/spark/derby.log MapPartitionsRDD[1] at textFile at <console>:27
scala> lines.count()
res4: Long = 13
scala> lines.first()
scala> val sparkLine = lines.filter(line => line.contains("spark"))
sparkLine: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at <console>:29
scala> sparkLine.first()
res7: String = "on database directory /Users/Documents/spark/metastore_db with class loader org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1@6bc8d8bd "
scala> sparkLine.count()
res8: Long = 3
三、核心概念介绍
3.1 宏观overview
- Speed
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. - Ease of Use
Write applications quickly in Java, Scala, Python, R. - Generality
Combine SQL, streaming, and complex analytics.
- Runs Everywhere
Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
引用源自Spark官网
3.2 spark知识点
- Spark Core Api
- Spark SQL
- Spark Streaming 流式计算
- Spark MLib 机器学习
- Spark GraphX 并行的图计算
- Spark的集群管理器(YARN、Mesos、自带的独立调度器)
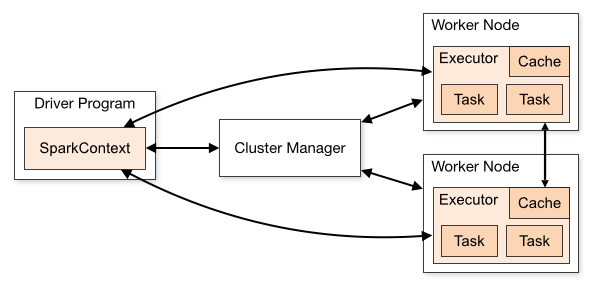
3.3 任务运行过程
一个Spark应用 –> 一个驱动器(driver program)节点 –> 多个工作节点(worker node)
一个工作节点 –> 一个执行器(executor) –> 多个并行任务(task)
3.4 几个任务概念的区分
http://spark.apache.org/docs/1.6.1/cluster-overview.html
- job 一系列stage组成一个job,一个行动就是一个job
- stage 一个job可以分为多个stage, stage划分的条件,shuffle或者行动操作
- task executor上的最小任务单元称之为task,task是并行的,单个shuffle根据partition数划分成n个tasks
| Term | Meaning |
|---|---|
| Application | User program built on Spark. Consists of a driver program and executors on the cluster. |
| Application jar | A jar containing the user’s Spark application. In some cases users will want to create an “uber jar” containing their application along with its dependencies. The user’s jar should never include Hadoop or Spark libraries, however, these will be added at runtime. |
| Driver program | The process running the main() function of the application and creating the SparkContext |
| Cluster manager | An external service for acquiring resources on the cluster (e.g. standalone manager, Mesos, YARN) |
| Deploy mode | Distinguishes where the driver process runs. In “cluster” mode, the framework launches the driver inside of the cluster. In “client” mode, the submitter launches the driver outside of the cluster. |
| Worker node | Any node that can run application code in the cluster |
| Executor | A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors. |
| Task | A unit of work that will be sent to one executor |
| Job | A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs. |
| Stage | Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you’ll see this term used in the driver’s logs. |
四、Spark Core原理解析
4.1 架构
- Spark集群采用的是典型的主 / 从结构
- 一个Spark应用(application) = 一个中央协调驱动器(Driver)节点 + 多个执行任务的执行器(Executor)节点;
- 【Executor】负责并行的执行任务(task)、存储必要的RDD数据
- 【Driver】负责任务拆分、任务调度
- 程序之间的RDD变换关系组成了一张逻辑上的DAG,程序运行时逻辑图将转换为物理执行过程,Driver在对任务划分的时候会将连续的映射转为流水线,将多个操作合并到同一个步骤(stage)中来,明显的例子
val local_lines = sc.textFile("XXX")
local_lines.first()
#连续起来执行后只需要加载文件的第一行- Application -> Jobs -> stages -> tasks
1) val local_lines = sc.textFile("XXX")
1.2) val local_lines_1 = local_lines.map(xxx)
2) val local_lines_2 = sc.textFile("XXX")
3) println(local_lines_1.union(local_lines_2))
# 3)是一个job,可以拆分为1*)、2)两个stage
# 每个stage可以分为并行的多个task- 【集群管理器】启动执行器节点,某些特定情况(比如、–deloy-mode=cluster)下才会靠集群管理器来启动驱动器节点。程序启动的时候,驱动器程序与集群管理器通信申请资源启动执行器节点;程序结束的时候,驱动器程序终止执行器过程,并告诉集群管理器释放资源
- 集群管理器的主节点、从节点和Spark的驱动器、执行器节点是两个维度的概念;
集群的主从表示集群的中心化和分布式的部分
Spark的执行器、驱动器节点描述的是执行Spark程序的两种进程的节点
二者没有关联性,所以即使在YARN的工作节点上,Spark也是可以跑执行器和驱动器进程的
4.2 DAG、Jobs、Stage、Task详解
1)val input = sc.textFile("file:///tmp/input.txt")
2)val tokenized = input.map(line => line.split(" ")).filter(words => words.size>0)
3)val counts = tokenized.map(words => (words(0), 1)).reduceByKey((a,b) => a+b)
4)counts.collect()
# 每一个RDD都记录了父节点的关系
scala> input.toDebugString
res82: String =
(2) file:///tmp/input.txt MapPartitionsRDD[62] at textFile at <console>:27 []
| file:///tmp/input.txt HadoopRDD[61] at textFile at <console>:27 []
scala> tokenized.toDebugString
res83: String =
(2) MapPartitionsRDD[64] at filter at <console>:29 []
| MapPartitionsRDD[63] at map at <console>:29 []
| file:///tmp/input.txt MapPartitionsRDD[62] at textFile at <console>:27 []
| file:///tmp/input.txt HadoopRDD[61] at textFile at <console>:27 []
scala> counts.toDebugString
res84: String =
(2) ShuffledRDD[66] at reduceByKey at <console>:31 []
+-(2) MapPartitionsRDD[65] at map at <console>:31 []
| MapPartitionsRDD[64] at filter at <console>:29 []
| MapPartitionsRDD[63] at map at <console>:29 []
| file:///tmp/input.txt MapPartitionsRDD[62] at textFile at <console>:27 []
| file:///tmp/input.txt HadoopRDD[61] at textFile at <console>:27 []
##
stage_1 : HadoopRDD --> MapPartitionsRDD --> map --> filter --> map --> reduceByKey
stage_2 : collect- 一个job(counts.collect())被拆成了两个stages
- 在行动操作之前,一切都是逻辑的DAG,行动操作是真实的物理变化发生时
- 驱动器程序执行了“流水线操作”,将多个RDD合并要一起执行
- 系谱图是自下而上的查找,这意味着如果任何一个父RDD上已经有数据缓存,这条链路都将得到优化
- Spark的执行流程:用户代码定义DAG - 行动操作将DAG转转义为执行计划 - 任务在集群中调度并执行
4.3 执行器节点内存分配
- 默认60% RDD存储
cache()
persist()默认20% 数据清洗与聚合
缓存数据混洗的输出数据,存储聚合的中间结果,通过spark.shuffle.memoryFraction来限定内存占比默认20% 用户代码
与代码中的中间数据存储,比如创建数组
4.4 容错性
Spark会自动重新执行失败的 或 较慢的任务来应对有错误的或者比较慢的机器
Spark还可能会在一台新的节点上投机的执行一个新的重复任务,如果提前结束,则提前获取结果,因此一个方法可能被执行多次
所以spark的累加器并不一定准
五、RDD编程
5.1 RDD是什么
RDD(弹性分布式数据集、Resilient Distributed Dataset)是Spark的数据结构。RDD的行为只分为三种:创建、转化(产生一个新的RDD)、行动(对当前RDD进行统计)
5.2 RDD创建
val local_lines = sc.textFile("file:///usr/local/opt/spark-1.6.1-bin-hadoop2.4/README.md")
或者
val local_lines = sc.parallelize(List("pandas", "i like pandas")5.3 RDD的转化
系谱图记录各个RDD之间的转换关系
5.3.1 针对各个元素的转化
# map() 针对每个元素一一对应的转换
scala> val numbers = sc.parallelize(List(1,2,3,4));
scala> numbers.map(x => x*x).collect().foreach(println)
1
4
9
16
# filter() 针对每个元素的过滤选择
scala> val numbers = sc.parallelize(List(1,2,3,4));
scala> numbers.filter(x => x>2).collect().foreach(println)
3
4
# flatmap() 对每一个元素处理后放回同一个大集合,典型的例子:split
scala> val strings = sc.parallelize(List("huang#hai#feng", "zhong#guo", "huang#hai#feng"));
scala> strings.flatMap(x => x.split("#")).collect().foreach(println)
huang
hai
feng
zhong
guo
huang
hai
feng
# sample 采样,
scala> numbers.collect().foreach(println)
1
2
3
4
# 每个位置按照随机种子,选 or 不选
scala> numbers.sample(false, 0.5).collect().foreach(println)
1
2
4
# 这个true,, 待理解
scala> numbers.sample(true, 0.5).collect().foreach(println)
2
3
3
4
5.3.2 伪集合操作
scala> numbers.collect().foreach(println)
1
2
3
4
scala> numbers_1.collect().foreach(println)
3
4
5
6
# union 并集,允许重复元素
scala> numbers.union(numbers_1).collect().foreach(println)
1
2
3
4
3
4
5
6
scala> numbers.union(numbers_1).distinct().collect().foreach(println)
4
1
5
6
2
3
# intersection交集
scala> numbers.intersection(numbers_1).collect().foreach(println)
4
3
# subtract差集
scala> numbers.subtract(numbers_1).collect().foreach(println)
2
1
# cartesian笛卡尔乘积
scala> numbers.cartesian(numbers_1).collect().foreach(println)
(1,3)
(1,4)
(2,3)
(2,4)
(1,5)
(1,6)
(2,5)
(2,6)
(3,3)
(3,4)
(4,3)
(4,4)
(3,5)
(3,6)
(4,5)
(4,6)5.4 RDD的行动
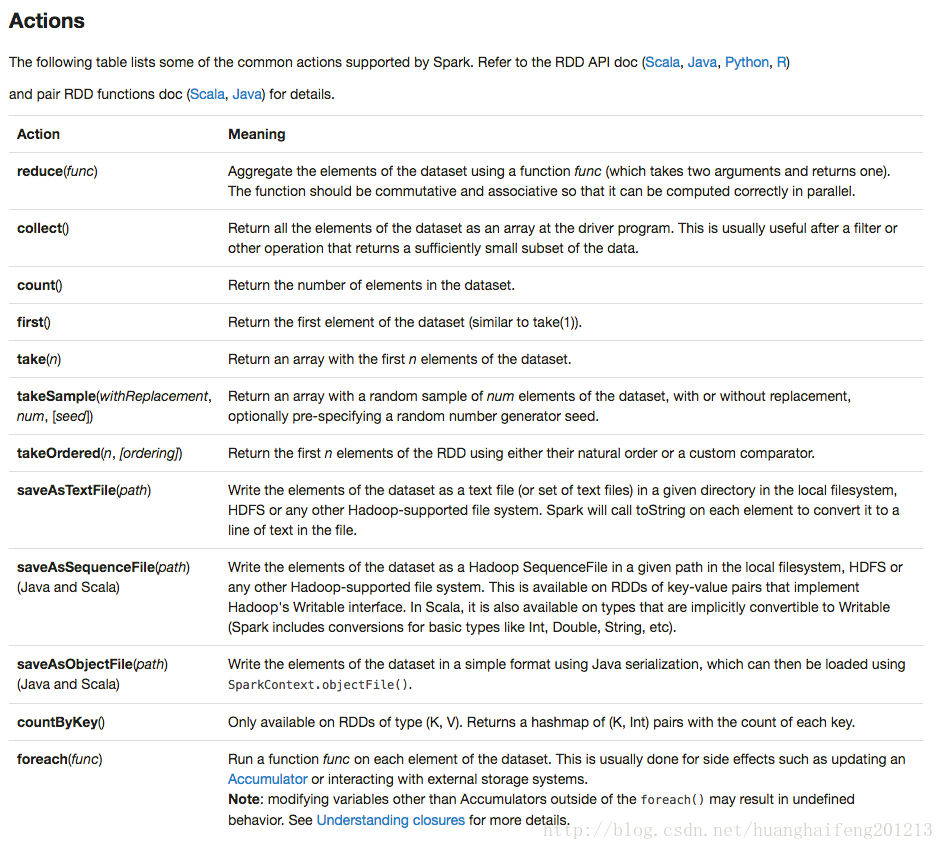
# reduce
scala> numbers.reduce((x, y) => x*y)
res102: Int = 24
# countByValue word count已实现
scala> numbers.countByValue()
res104: scala.collection.Map[Int,Long] = Map(4 -> 1, 2 -> 1, 1 -> 1, 3 -> 1)
# fold 需要传入一个初始的单元值 加法是0 乘法是1
scala> numbers.fold(1)((x, y) => x*y)
res103: Int = 24
# aggregate 求平均数
scala> val numbers = sc.parallelize(List(3,4,5,6))
numbers: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:27
#numbers.aggregate((0,0))(
# ((x, value) => (x._1 + value, x._2 + 1)),
# ((x1, x2) => (x1._1+x2._1, x1._2+x2._2))
# )
scala> numbers.aggregate((0,0))(((x, value) => (x._1 + value, x._2 + 1)), ((x1, x2) => (x1._1+x2._1, x1._2+x2._2)))
res0: (Int, Int) = (18,4)
scala> res0._1/res0._2.toDouble
res1: Double = 4.5
5.5 RDD的打印
- take(n) 分区就近原则出
scala> numbers.take(2).foreach(println)
1
2- top(n)
scala> numbers.top(2).foreach(println) 按照数据集合自己的顺序出
4
3- sample(bWithReplacement, dFraction, seed) 丢骰子取样
scala> numbers.sample(false, 0.3).foreach(println)
3
4
2- takeSample(bWithReplacement, n, seed) 随机取样n个
scala> numbers.takeSample(false, 3).foreach(println)
4
3
1- collect() 全返回
scala> numbers.collect().foreach(println)
1
2
3
4
scala> numbers.collect().mkString(",")
res2: String = 1,2,3,45.6 持久化的几种类型
| 级别 | 使用的空间 | CPU时间 | 是否在内存中 | 是否在磁盘上 | 备注 |
|---|---|---|---|---|---|
| NONE | |||||
| DISK_ONLY | 低 | 高 | 否 | 是 | |
| DISK_ONLY_2 | 低 | 高 | 否 | 是 | 同上一个级别,但存了两份 |
| MEMORY_ONLY | 高 | 低 | 是 | 否 | |
| MEMORY_ONLY_2 | 高 | 低 | 是 | 否 | 同上一个级别,但存了两份 |
| MEMORY_ONLY_SER | 低 | 高 | 是 | 否 | ser是序列化的意思 |
| MEMORY_ONLY_SER_2 | 低 | 高 | 是 | 否 | 同上一个级别,但存了两份 |
| MEMORY_AND_DISK | 高 | 中等 | 部分 | 部分 | 如果内存装不下了,多出了的写到磁盘 |
| MEMORY_AND_DISK_2 | 高 | 中等 | 部分 | 部分 | 同上一个级别,但存了两份 |
| MEMORY_AND_DISK_SER | 低 | 高 | 部分 | 部分 | 内存存不下,多出来的部分存到磁盘,并将序列化数据写入内存 |
| MEMORY_AND_DISK_SER_2 | 低 | 高 | 部分 | 部分 | 同上一个级别,但存了两份 |
| OFF_HEAP |
- 如果内存使用的不够了, 我们使用最少使用原则(LRU)进行回收
- Spark还提供有unpersist()方法手动释放内存
六、Pair RDD编程
6.1 创建Pair RDD
scala> numbers.collect().mkString(",")
res7: String = 3,4,5,6
scala> val pairs = numbers.map(x => (x+1, x*x))
pairs: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[1] at map at <console>:29
scala> pairs.collect().mkString(",")
res9: String = (4,9),(5,16),(6,25),(7,36)
val lines = sc.textFile("data.txt")
val pairs = lines.map(s => (s, 1))
val counts = pairs.reduceByKey((a, b) => a + b)6.2 转化操作
scala> val pairs_1 = sc.parallelize(List((1, 2), (3, 4), (3, 6)))
pairs_1: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[3] at parallelize at <console>:27
scala> pairs_1.collect.mkString(",")
res12: String = (1,2),(3,4),(3,6)
scala> pairs_1.reduceByKey((x, y) => x+y).collect.mkString(",")
res13: String = (1,2),(3,10)
scala> pairs_1.groupByKey().collect.mkString(",")
res16: String = (1,CompactBuffer(2)),(3,CompactBuffer(4, 6))
scala> pairs_1.mapValues(x => x+10).collect.mkString(",")
res17: String = (1,12),(3,14),(3,16)
scala> pairs_1.flatMapValues(x => (x to 15)).collect.mkString(",")
res19: String = (1,2),(1,3),(1,4),(1,5),(1,6),(1,7),(1,8),(1,9),(1,10),(1,11),(1,12),(1,13),(1,14),(1,15),(3,4),(3,5),(3,6),(3,7),(3,8),(3,9),(3,10),(3,11),(3,12),(3,13),(3,14),(3,15),(3,6),(3,7),(3,8),(3,9),(3,10),(3,11),(3,12),(3,13),(3,14),(3,15)
scala> pairs_1.keys.collect.mkString(",")
res24: String = 1,3,3
scala> pairs_1.values.collect.mkString(",")
res25: String = 2,4,6
scala> pairs_1.sortByKey().collect.mkString(",")
res28: String = (1,2),(3,4),(3,6)
scala> pairs_1.sortByKey(false).collect.mkString(",")
res49: String = (3,4),(3,6),(1,2)
----------------------------
scala> pairs_1.sortByKey().collect.mkString(",")
res28: String = (1,2),(3,4),(3,6)
scala> val pairs_2 = sc.parallelize(List((3, 9)))
pairs_2: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[15] at parallelize at <console>:27
scala> pairs_1.join(pairs_2).collect.mkString(",")
res31: String = (3,(4,9)),(3,(6,9))
scala> pairs_1.rightOuterJoin(pairs_2).collect.mkString(",")
res33: String = (3,(Some(4),9)),(3,(Some(6),9))
scala> pairs_1.leftOuterJoin(pairs_2).collect.mkString(",")
res34: String = (1,(2,None)),(3,(4,Some(9))),(3,(6,Some(9)))
scala> pairs_1.cogroup(pairs_2).collect.mkString(",")
res35: String = (1,(CompactBuffer(2),CompactBuffer())),(3,(CompactBuffer(4, 6),CompactBuffer(9)))
scala> pairs_1.filter{case(x, y) => y>4}.collect.mkString(",")
res40: String = (3,6)6.3 行动操作
scala> pairs_1.collect.mkString(",")
res48: String = (1,2),(3,4),(3,6)
## 注意,返回的是一个Map
scala> pairs_1.countByKey()
res50: scala.collection.Map[Int,Long] = Map(1 -> 1, 3 -> 2)
## 注意,返回的是一个Map, 一个Key对应一个Value
scala> pairs_1.collectAsMap()
res52: scala.collection.Map[Int,Int] = Map(1 -> 2, 3 -> 6)
## 查询Value
scala> pairs_1.lookup(3)
res54: Seq[Int] = WrappedArray(4, 6)
scala> pairs_1.lookup(3).toString
res55: String = WrappedArray(4, 6)6.4 分区详解
每一个RDD都是不可变的,每一个RDD我们都可以指定其分区方法
- org.apache.spark.HashPartitioner(partitions : scala.Int) Hash分区
- org.apache.spark.RangePartitioner[K, V] 范围分区
分区的好处不言而喻——减少数据的重新洗牌,大数据合并小数据集,小数据向着大数据集的分区靠拢,自然久省去了很多网络的耗时,一切就像是并行在单机上一样的
分一次分区都会创建新的RDD
分区完毕后还需要用到则需要使用缓存函数persist,避免每次都重新分区
scala> pairs_1.partitioner
res56: Option[org.apache.spark.Partitioner] = None
scala> pairs_1.partitionBy(new org.apache.spark.HashPartitioner(2))
res59: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[42] at partitionBy at <console>:30
scala> pairs_1.partitioner
res60: Option[org.apache.spark.Partitioner] = None
scala> res59.partitioner
res61: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@2)
scala> pairs_1.sortByKey()
res62: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[45] at sortByKey at <console>:30
scala> res62.partitioner
res63: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.RangePartitioner@8ed)这里列出了所有会为生成的结果 RDD 设好分区方式的操作:
cogroup()
groupWith()
join()
leftOuterJoin()
rightOuterJoin()
groupByKey()
reduceByKey()
combineByKey()
partitionBy()
sort()
mapValues()(如果父 RDD 有分区方式的话)
flatMapValues()(如果父 RDD 有分区方式的话)
filter()(如果父 RDD 有分区方式的话)对于二元操作,输出数据的分区方式取决于父 RDD 的分区方式。默认情况下,结果会采用哈希分区,分区的数量和操作的并行度一样。
如果其中的一个父 RDD 已经设置过分区方式,那么结果就会采用那种分区方式;
如果两个父 RDD 都设置过分区方式,结果 RDD 会采用第一个父 RDD 的分区方式。但是分区数会选max
| action | 是否会修改分区数 | 是否会修改分区方法 |
|---|---|---|
| partitionBy(new HashPartitioner(n)) | n | HashPartitioner |
| distinct | 不变 | none |
| distinct(n) | n | none |
| mapValues | 不变 | 不变 |
| reduceByKey | 不变 | 不变 |
| map | 不变 | none |
| zipWithUniqueId | 不变 | none |
七、文件操作
7.1 Spark支持的文件格式
| 格式名称 | 结构化 | 备注 |
|---|---|---|
| 文本文件 | 否 | 普通的文本文件,每行一条记录 |
| JSON | 半结构化 | 常见的基于文本的格式,大多数库都要求每行一条记录 |
| CSV | 是 | 非常常见的基于文本的格式,通常在电子表格应用中使用 |
| SequenceFiles | 是 | 一种用于键值对数据的常见 Hadoop 文件格式 |
| Protocol buffers | 是 | 一种快速、节约空间的跨语言格式 |
| 对象文件 | 是 | 用来将 Spark 作业中的数据存储下来以让共享的代码读取。改变类的时候 它会失效,因为它依赖于 Java 序列化 |
# 当传入的参数是目录的时候
## 转化为一个RDD
val input = sc.textFiles(inputFile)
## 转化为一个以文件名为Key的Pair RDD
val input = sc.wholeTextFiles(inputFile)
# 输出的产出参数是一个目录,因为Spark是并发输出的
rdd.saveAsTextFile(output_path)def main(args: Array[String]) {
if (args.length < 3) {
println("Usage: [sparkmaster] [inputfile] [outputfile]")
exit(1)
}
val master = args(0)
val inputFile = args(1)
val outputFile = args(2)
val sc = new SparkContext(master, "BasicParseJson", System.getenv("SPARK_HOME"))
val input = sc.textFile(inputFile)
//input.flatMap(msg => if (JSON.parseObject(msg).getString("name").contentEquals("Sparky The Bear")) { msg } else { "" }).collect().foreach(print)
input.map(JSON.parseObject(_)).saveAsTextFile(outputFile)
}case class Person(name: String, favouriteAnimal: String)
def main(args: Array[String]) {
if (args.length < 3) {
println("Usage: [sparkmaster] [inputfile] [outputfile]")
exit(1)
}
val master = args(0)
val inputFile = args(1)
val outputFile = args(2)
val sc = new SparkContext(master, "BasicParseCsv", System.getenv("SPARK_HOME"))
val input = sc.textFile(inputFile)
val result = input.map{ line =>
val reader = new CSVReader(new StringReader(line));
reader.readNext();
}
val people = result.map(x => Person(x(0), x(1)))
val pandaLovers = people.filter(person => person.favouriteAnimal == "panda")
pandaLovers.map(person => List(person.name, person.favouriteAnimal).toArray).mapPartitions{ people =>
val stringWriter = new StringWriter();
val csvWriter = new CSVWriter(stringWriter);
csvWriter.writeAll(people.toList)
Iterator(stringWriter.toString)
}.saveAsTextFile(outputFile)
}
7.2 Spark支持的文件存储方式
- File System
- HDFS
- Cassandra
- HBase
- Amazon S3
- Spark SQL
- etc. Spark supports text files, SequenceFiles, and any other Hadoop InputFormat.
val lines = sc.textFile("file:///usr/local/opt/spark-1.6.1-bin-hadoop2.4/README.md")
val lines = sc.textFile("hdfs:///usr/local/opt/spark-1.6.1-bin-hadoop2.4/README.md")
val lines = sc.textFile("s3n://bigdata-east/tmp/README.md") 八、Spark编程进阶
8.1 共享变量
8.1.1 累加器 accumulator
- 生命周期
在驱动器中创建 – 在执行器中累计 – 在驱动器中获取返回结果 - 累加器不是严格的只累计一次
转化操作可以因为一些原因被多次执行(任务执行失败重新执行、任务执行的太慢呗重新执行、原来RDD占用的内存被回收转化操作重新加载并执行方法),从而导致目前的累加器只适合做debug使用,或者foreach - 累加器的操作需要满足交换律(即,a op b等同于b op a) 和 结合律(即、 (a op b) op c 等同于 a op (b op c)),比如加法、乘法、max函数
def main(args: Array[String]) {
val master = args(0)
val inputFile = args(1)
val sc = new SparkContext(master, "BasicLoadNums", System.getenv("SPARK_HOME"))
val file = sc.textFile(inputFile)
val errorLines = sc.accumulator(0) // Create an Accumulator[Int] initialized to 0
val dataLines = sc.accumulator(0) // Create a second Accumulator[Int] initialized to 0
val counts = file.flatMap(line => {
try {
val input = line.split(" ")
val data = Some((input(0), input(1).toInt))
dataLines += 1
data
} catch {
case e: java.lang.NumberFormatException => {
errorLines += 1
None
}
case e: java.lang.ArrayIndexOutOfBoundsException => {
errorLines += 1
None
}
}
}).reduceByKey(_ + _)
println(counts.collectAsMap().mkString(", "))
println(s"Too many errors ${errorLines.value} for ${dataLines.value}")
}8.1.2 广播变量
- 调用SparkContext.broadcast创建出一个Broadcast[T]对象。 任何可序列化的类型都可以
- 通过value属性访问该广播变量的值
- 广播变量只会被发到各个节点一次,应作为只读值处理(但是,如果修改了这个值,将不会影响到别的节点)
- 传输中选择一个既好又快的序列化格式是很重要的
val signPrefixes = sc.broadcast(loadCallSignTable())
val countryContactCounts = contactCounts.map{
case (sign, count) =>
val country = lookupInArray(sign, signPrefixes.value)
(country, count)
}.reduceByKey((x, y) => x + y)
def loadCallSignTable() = {
scala.io.Source.fromFile("./files/callsign_tbl_sorted").getLines()
.filter(_ != "").toArray
}
# ./files/callsign_tbl_sorted
3DM, Swaziland (Kingdom of)
3DZ, Fiji (Republic of)
3FZ, Panama (Republic of)
3GZ, Chile
3UZ, China (People's Republic of)8.2 调用第三方脚本 Pipe
val pwd = System.getProperty("user.dir")
val distScript = pwd + "/bin/finddistance.R"
val distScriptName = "finddistance.R"
## 上传脚本
sc.addFile(distScript)
val pipeInputs = contactsContactLists.values.flatMap(x => x.map(y => s"${y.contactlat},${y.contactlong},${y.mylat},${y.mylong}"))
println(pipeInputs.collect().toList)
## 根据脚本名加载文件
val distances = pipeInputs.pipe(SparkFiles.get(distScriptName))8.3 数值RDD - StatCounter
调用stats()时,会通过一次遍历数据计算出大多数常用的数据统计
count() RDD 中的元素个数
mean() 元素的平均值
sum() 总和
max() 最大值
min() 最小值
variance() 元素的方差
sampleVariance() 从采样中计算出的方差
stdev() 标准差
sampleStdev() 采样的标准差
val stats = distanceDoubles.stats()
val stddev = stats.stdev
val mean = stats.mean













 144
144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









