






高尔基曾经说:书籍是人类进步的阶梯,21世纪的今天书籍依然是人类进步的阶梯!
当当网计算机图书
每满100减50!
满200减100!
满300-150!
满400-200!
机械工业出版社华章公司联合当当网特意为小编用户申请了一批可与满减叠加使用的“满200减30”的图书优惠码,优惠码使用后相当于:
400减230 !!!
优惠码:【YCQHMP】(注意区分大小写)
使用渠道:当当app和当当小程序
使用时间:5/25-6/3
本活动满减与礼券均不支持团购,同一账号、同一地址、同一手机号、同一IP反复购买本活动商品,当当有权取消订单,终结交易。
使用方法:原有的满减(满100减50,满200减100,满300减150,满400减200)核算后,得出的总价如果超过200可以用优惠码再减30。
示例:

操作方法
(1)长按识别下方小程序码

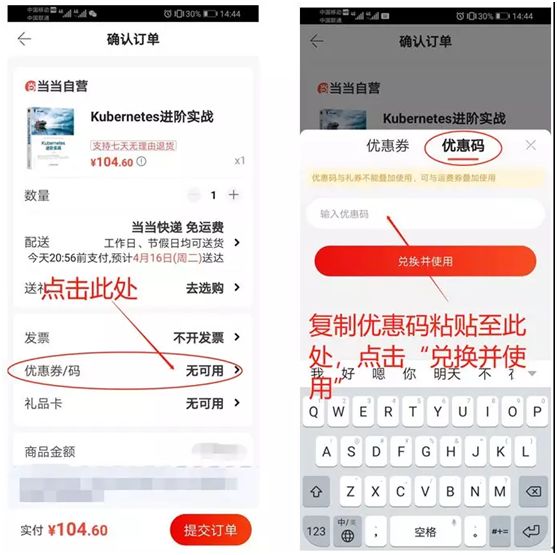
(2)在结算付款界面,点击优惠券/码,输入优惠码(如下图所示)。
小程序直达购选书专题
阅读原文:http://h5.dangdang.com/mix_gys_04001_c2h2
关于买哪些书,我在下面推荐一份书单:
1

《Java核心技术第10版卷I(基础知识)+卷II(高级特性)》
全新第10版!Java领域极具影响力和价值的著作之一,与《Java编程思想》齐名,10余年全球畅销不衰,广受好评
2

《Effective Java中文版(原书第3版)》
Java之父James Gosling鼎力推荐、Jolt获奖作品全新升级,针对Java 7、8、9全面更新,Java程序员必备参考书。包含大量完整的示例代码和透彻的技术分析。
3

《深入理解Java虚拟机:JVM高级特性与最佳实践(第2版)》
Java图书领域公认的经典著作和超级畅销书!以实战为导向,通过大量与实际生产环境相结合的案例,展示了解决各种常见JVM问题的技巧和最佳实践
4

《JVM G1源码分析和调优》
详细分析G1的基本运行原理以及调优方法,讲解细腻,图示丰富,可帮助Java工程师深入理解垃圾回收技术。
5

《Java图像处理:基于OpenCV与JVM》
本书提供了常见图像处理问题的Java解决方案、学习实践案例,以及有关使用OpenCV进行图像处理的各种知识。
6

《Java并发编程实战》
第16届Jolt大奖提名图书,Java并发编程必读佳作!
本书深入浅出地介绍了Java线程和并发,是一本完美的Java并发参考手册。
7

《Java高并发编程详解:多线程与架构设计》
汇丰软件全球(广东)研发中心技术专家撰写,作者毫无保留地分享了多年的Java服务器、大数据程序开发架构经验和最佳实践。实战性强,从底层原理的角度总结和归纳各个技术细节,结合真实的案例讲解高并发程序设计。
8

《Docker技术入门与实战(第3版)》
入门Docker的首本书,经典畅销书升级,系统化掌握容器技术栈,第3版基于 Docker 新 18.x系列版本。
9

《Spring Cloud微服务:全栈技术与案例解析》
资深Java工程师撰写,详细讲解SpringCloud微服务的全栈技术和扩展知识,以及微服务架构与设计的经验
10

《微服务架构设计模式》
微服务架构的先驱、Java开发者社区的意见领袖ChrisRichardson亲笔撰写,微服务实用落地指南。















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









