






前言
记录Spring的一些基本理论,引申出Spring循环依赖的问题
Spring是什么
是容器(承载各种bean) 是基石、生态(SpringBoot、SpringCloud都是在此基础上的扩展)
Spring容器(IOC)
本质上就是一个Map,存放各种Bean
整体工作流程
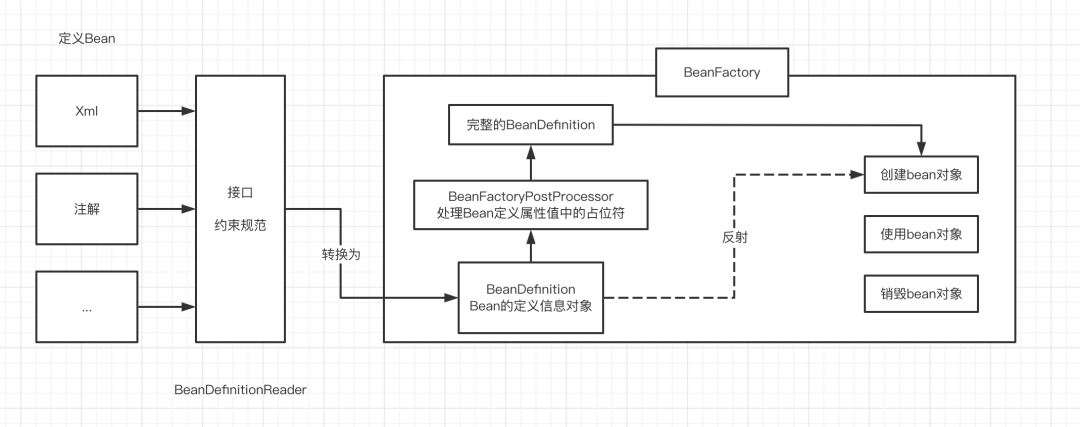
BeanDefinitionReader 一个接口,约束和规范bean信息的定义。其子类是将各种格式的bean信息转换为BeanDefinition的实现
(1) XmlBeanDefinitionReader转换XML
(2) PropertiesBeanDefinitionReader转换配置文件(Resource,Property)
(3) GroovyBeanDefinitionReader转换Groovy
此处体现了Spring强大的扩展性
BeanFactory访问Bean容器的根接口
(1) 如子类ApplicationContext
SpringContextHolder.getApplicationContext().getBean(xxx.class)
(2) 如子类BeanFactoryPostProcessor也是间接实现此接口操作BeanDefinition
BeanFactoryPostProcessor处理Bean定义属性值中的占位符
(1) 如spring.shardingsphere.datasource.master.username={ERP2_MYSQL_USERNAME}
(2) 如name="username" value="${jdbc.username}">xml文件中的${jdbc.username}
创建Bean对象
放大创建Bean对象的流程
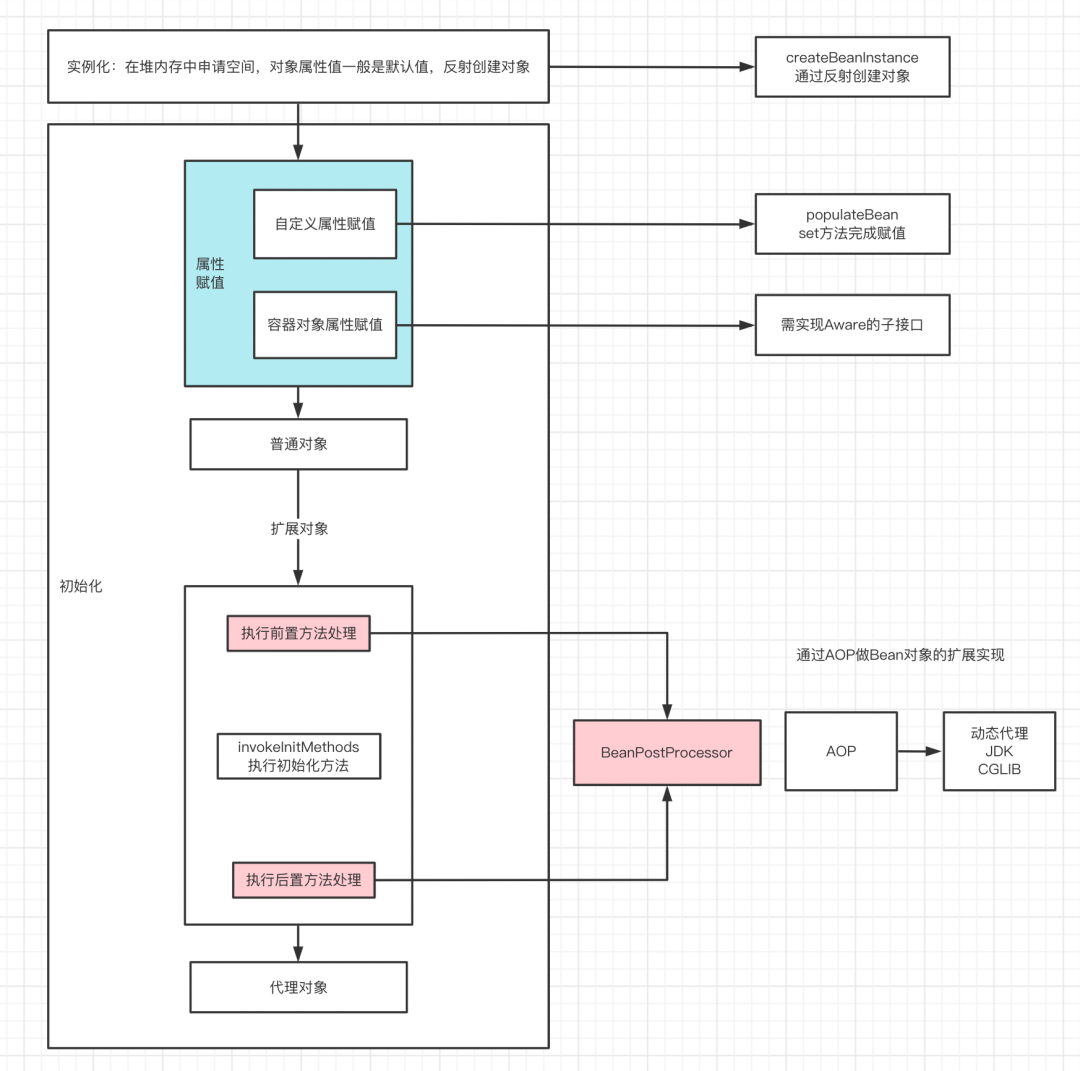
Aware一个无声明的接口,Spring用于标识bean是否为容器对象
如想把ApplicationContext这种容器对象想作为自定义bean的属性时,则需实现ApplicationContextAware(ApplicationContextAware extends Aware)接口,告诉Spring(让Spring感知),Spring会在统一的地方处理为其赋值
BeanPostProcessor做Bean对象的扩展实现
(1) 如子类AbstractAutoProxyCreator通过动态代理方式实现扩展(AOP)
此处引出AOP的概念:表明AOP是IOC整体流程中的一个扩展点
invokeInitMethods执行Bean对象自定义初始化方法
(1) 当校验Bean实现InitializingBean接口时,此处会调用afterPropertiesSet方法,做一些bean使用前的初始化工作
Spring循环依赖的问题
什么是循环依赖
在上文创建Bean对象流程中,放大属性赋值中自定义属性赋值流程,假设有这种情况:自定义对象A引用了自定义对象B,自定义对象B又引用了自定义对象A,这种情况称之为循环依赖(跟死锁类似)
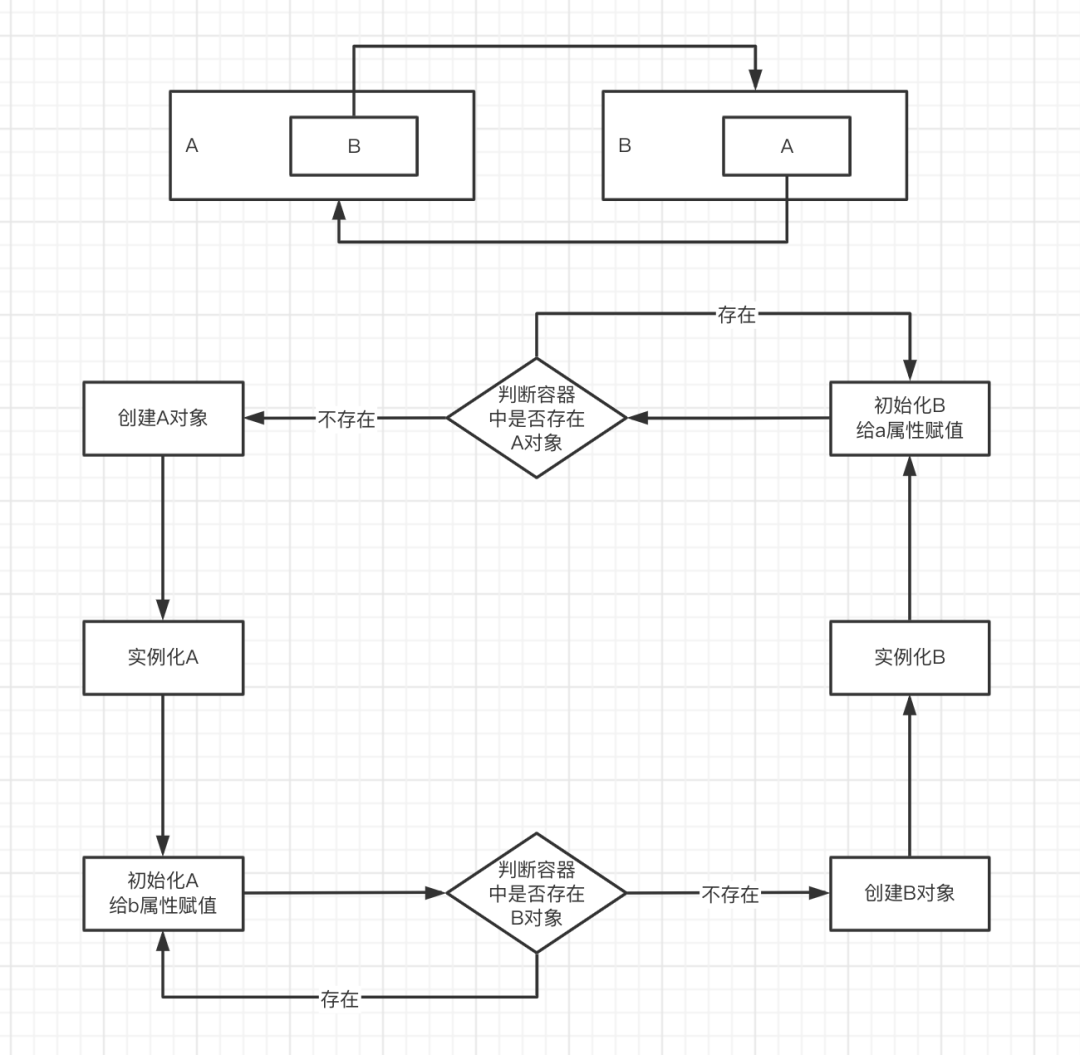
Spring解决方式
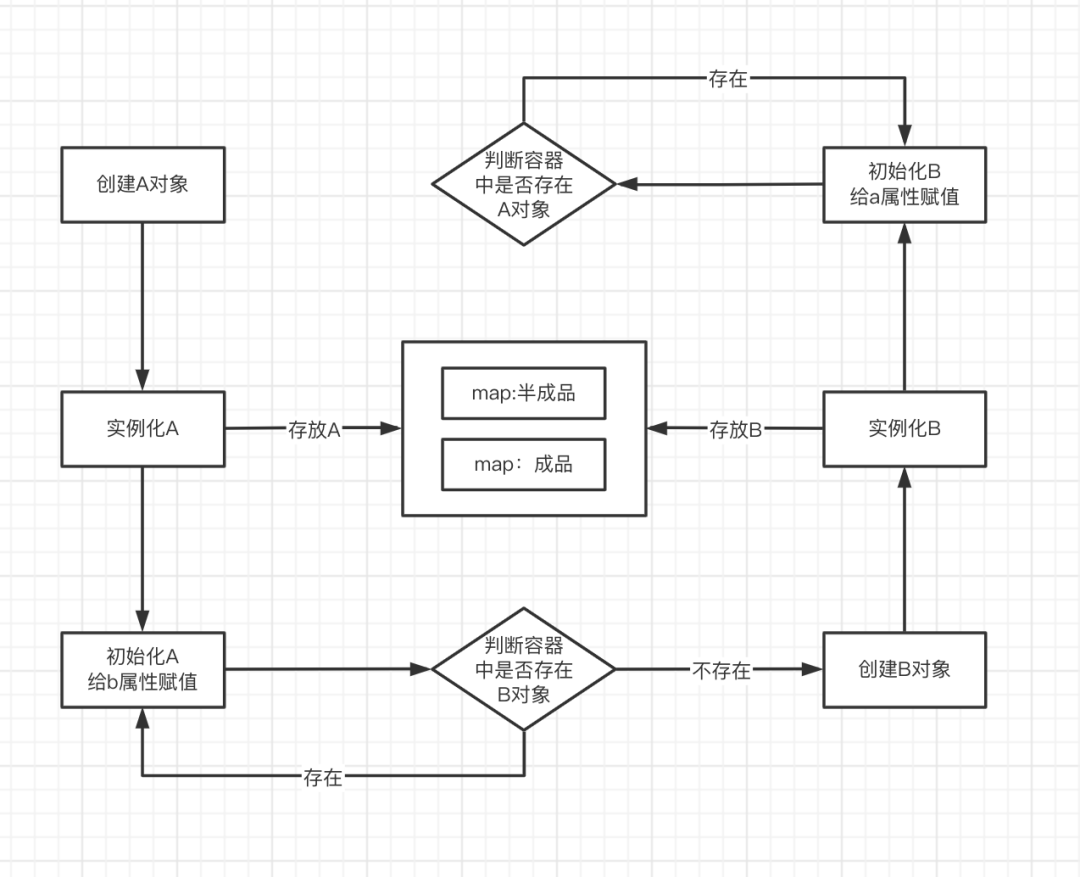
先将对象按照创建状态分类:半成品(实例化完成)、成品(初始化完成),不同的状态存放至不同的Map中(三级缓存),后续在判断容器是否存在A对象的时候,不需要去获取完整的A成品对象,只需要获取A半成品对象即可,这也是为什么Spring会把创建对象分为实例化和初始化两个阶段来执行的根本原因。
有种特殊情况,如果A对象中的b属性,是通过构造函授方式注入 ,那么就是在A实例化阶段就需要B对象了,这种情况就无法解决循环依赖的问题!
三级缓存
本质上就是三个Map,Srping用于存放不同创建状态的Bean,查看源码DefaultSingletonBeanRegistry
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
...
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
...
}singletonObjects一级缓存,存放成品对象(初始化完成)
earlySingletonObjects二级缓存,存放半成品对象(实例化完成)
singletonFactories三级缓存 ,存放创建对象的Lambda表达式
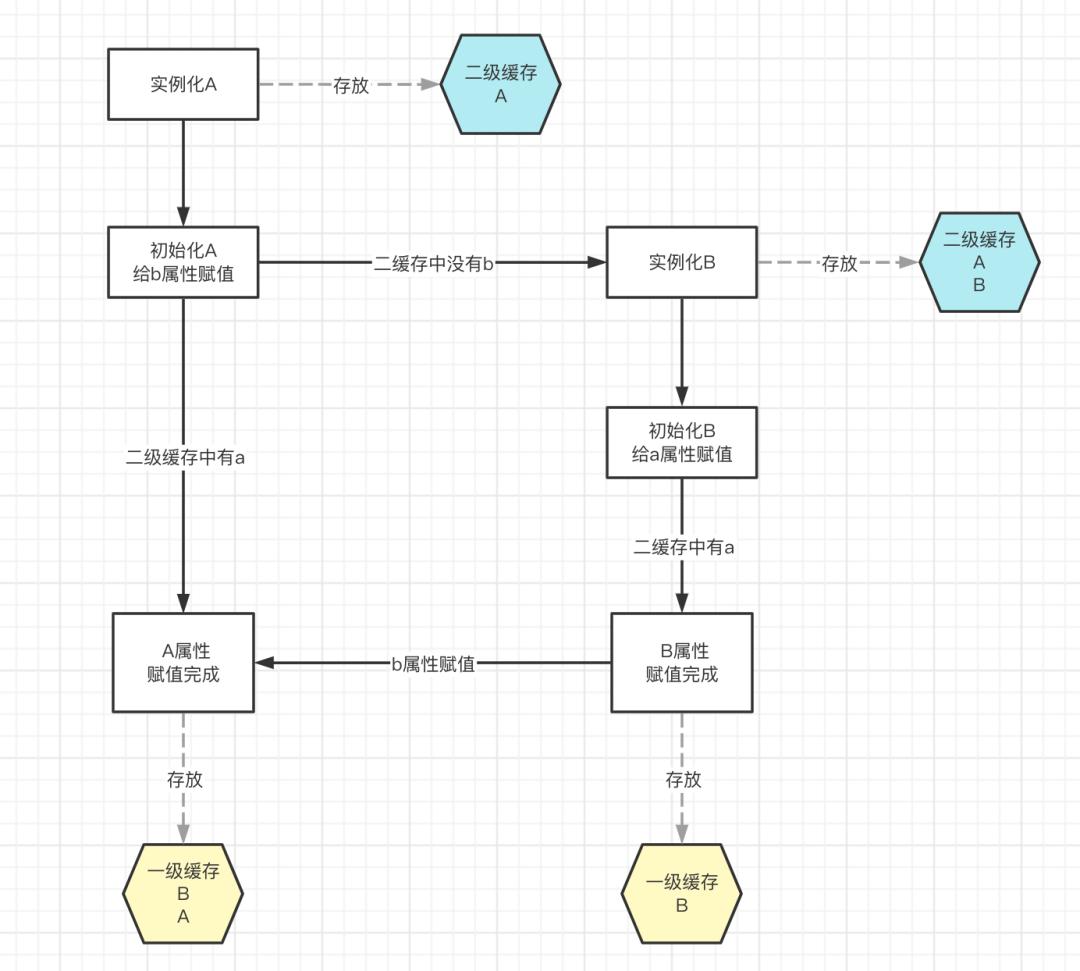
看流程图,使用二级缓存,就能解决循环依赖的问题,为什么需要用到三级缓存?
回顾上面创建Bean对象流程,Bean赋值完成后是为普通对象,如果对象需要扩展为AOP代理对象呢?
此时AB对象中各自拿到的就都不是最终版本的AB(拿到的是普通对象,AOP失效)
再看创建Bean对象流程,代理对象的创建是在属性赋值阶段之后的,如何在属性赋值阶段获取到代理对象?
在属性赋值的时候判断是否需要将普通对象替换为代理对象
如何判断?
使用Lambda表达式(Lambda表达式只有在调用的时候才会执行, 来判断返回的到底是代理对象还是原始对象) 完整流程
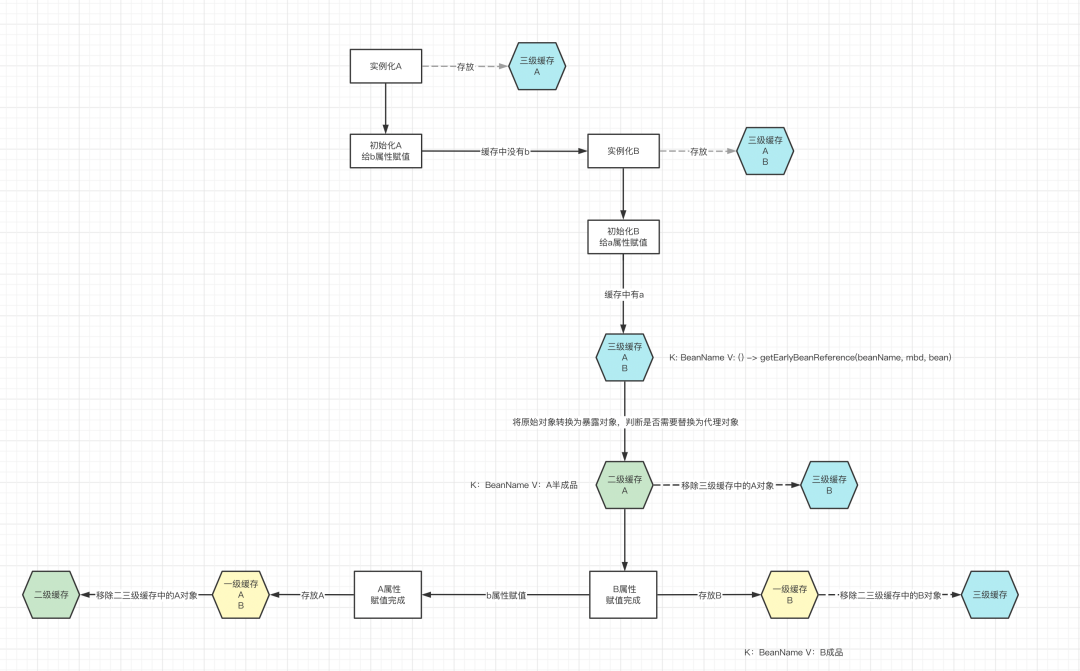
在A对象从三级缓存晋升到二级缓存时, 如果判断A对象是需要代理的,则会去提前生成A对应的代理对象,替换普通返回。相当于提前执行了A的BeanPostProcessor,而A对象在后续的扩展阶段也无需再次生成代理类了
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#getEarlyBeanReference
最后的问题
如果A对象是需要代理的,那么直接在earlySingletonObjects二级缓存中存放代理对象不行吗,为什么要使用Lambad函数式接口?
回顾Bean的生命周期:设计原则是 Bean实例化、属性赋值、初始化之后再去执行AOP生成代理对象
但是为了解决循环依赖但又尽量不打破这个设计原则的情况下,使用了存储了函数式接口的第三级缓存;如果使用二级缓存的话,可以将aop的代理工作提前到属性赋值阶段执行;也就是说所有的bean在创建过程中就先生成代理对象再初始化和其他工作;但是这样的话,就和spring的aop的设计原则相驳,aop的实现需要与bean的正常生命周期的创建分离;这样只有使用第三级缓存封装一个函数式接口对象到缓存中, 发生循环依赖时,再触发代理类的生成。
source : www.cnblogs.com/xurongze/articles/16275516.html记得点「赞」和「在看」↓
爱你们
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









