









当向leveldb写入数据时,首先是将数据写入leveldb的Memtable(Memtable可能转化为IMMemtable)中,Memtable是存储在内存中的。只有经过compaction操作后,才会将内存中的数据写入到磁盘中的sstable中。
当要读数据时,首先在Memtable中查找,若没有找到,则在sstable中继续查找。而sstable是存储在磁盘中的,这样就需要进行多次磁盘操作,速度会非常慢。为了加快查找速度,leveldb在采用了Cache的方式,尽最大可能减少随机读操作。
cache分为Table Cache和 Block Cache两种,其中Table Cache中缓存的是sstable的索引数据,Block Cache缓存的是Block数据,Block Cache是可选的,即可以在配置中来选择是否打开这个功能。
当要进行Compaction操作调用CompactMemTable()时,会调用WriteLevel0Table(),此时则会创建一个Meta File,并保存在Table Cache中,然后可通过Table Cache进行读取。
leveldb中的Cache主要用到了双向链表、哈希表和LRU(least recently used)思想。
1、LRUHandle
LRUHandle表示了Cache中的每一个元素,通过指针形成一个双向循环链表:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
在Table Cache中,Cache的key值是SSTable的文件名称,Value部分包含两部分,一个是指向磁盘打开的SSTable文件的文件指针,这是为了方便读取内容;另外一个是指向内存中这个SSTable文件对应的Table结构指针。这样就将不同的sstable文件像cache一样进行管理。
leveldb通过LRUHandle 结构将hash值相同的所有元素串联成一个双向循环链表,通过指针next_hash来解决hash 碰撞。
2、HandleTable
leveldb通过HandleTable维护一个哈希表:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
HandleTable只有3个成员变量: uint32_t length_; //hash表长,相当于二维数组的元素个数
uint32_t elems_; //hash表中元素总个数
LRUHandle** list_; //hash表头,相当于一个双向循环链表数组,其中每一个元素指向一个循环链表
初始时,length_=elems_=0, list_=NULL;此时hash表为空
然后调用resize()为hash表分配空间,初始时分配4个元素,当空间不足时,则成倍增加。此时hash表的结构如下:
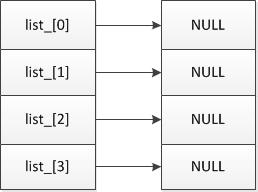
3、LRUCache
LRUCache顾名思义是指一个缓存,同时它用到了LRU的思想
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
LRUCache维护了一个双向循环链表lru_和一个hash表table,当要插入一个元素时,首先将其插入到链表lru的尾部,然后根据hash值将其插入到hash表中。
当hash表中已存在hash值与要插入元素的hash值相同的元素时,将原有元素从链表中移除,这样就可以保证最近使用的元素在链表的最尾部,这也意味着最近最少使用的元素在链表的头部,这样即可实现LRU的思想。
capacity_:当前Cache的最大容量
usage_:当前Cache已使用的内存大小,当超过最大容量时,从链表的头部开始移除元素
mutex_:保证每个Cache都是线程安全的
4、Cache和ShardedLRUCache
Class Cache采用虚函数定义了Cache的接口:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
具体实现的ShardedLRUCache继承自Cache,实现了相应的功能:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
由于每一个LRUCache是线程安全的,为了多线程访问,尽可能快速,减少锁开销,ShardedLRUCache内部将所有Cache根据hash值的高4位分为16份,即有16个LRUCache分片。
查找Key时首先计算key属于哪一个分片,分片的计算方法是取32位hash值的高4位,找到对应的LRUCache分配,然后在相应的LRUCache中进行查找,这样就大大减少了多线程的访问锁的开销。以Insert为例:
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
由上可知,ShardedLRUCache最终都是调用LRUCache的相应操作来实现的,因此下面将详细介绍LRUCache中的相关操作
5、LRUCache的具体操作
假设此时刚刚完成LRUCache的初始化和Resize()
插入元素:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
1) 调用LRU_Append(e) 将元素加入到双向循环链表中:
双向链表的插入操作示意图如下:
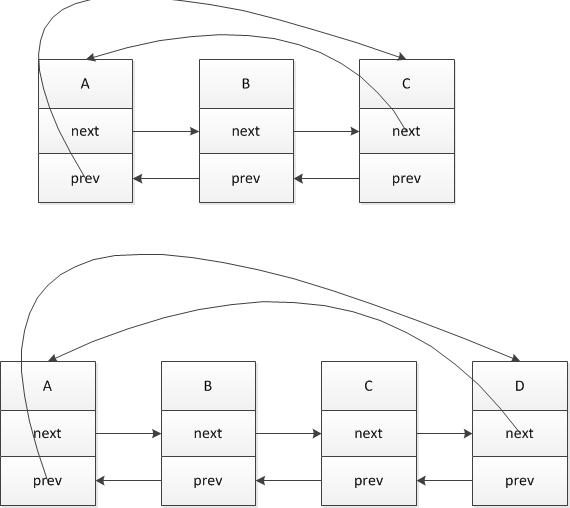
当插入节点D时:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这样就将一个节点插入到双向链表的尾部了
2) 调用 LRUHandle* old = table_.Insert(e); 向hash表中插入一个元素:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
当要插入一个元素时,首先进行查找:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
假设首先要插入元素的hash值为1:
此时length_ = 4,则 [ hash & (length_ - 1) ]=[01 & 11]= [1],即ptr= &list_[1],此时*ptr = NULL
则返回ptr并完成插入操作,此时hash表为:
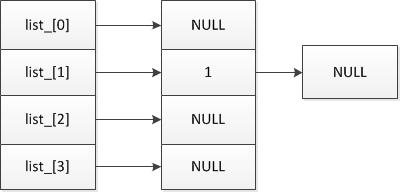
当要继续插入元素,且元素的hash值为5时:
此时length_ = 4,则 [ hash & (length_ - 1) ]=[101 & 11]= [1],ptr= &list_[1],此时*ptr = e(1),继续向后查找,ptr=&(*ptr)->next_hash; 最终*ptr = NULL ,则返回ptr并完成插入操作,此时hash表为:
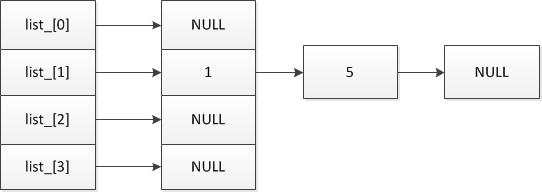
插入操作的基本操作为:首先构造LRUHandle结构体,然后将其插入到双向链表中,然后根据hash值将其插入到hash表中,并调整hash表的大小,最后根据内存大小,移除双向链表表头后第一个元素,来实现LRU算法。
其它操作如Lookup()、Erase()、Release()等,都是先根据hash值的高四位来找到对应的LRUCache,然后在相应的hash表中根据hash值找到相应元素,最终来对找到的元素执行相关操作。
6、总结
1)一个SharedLRUCache根据hash值的高4位,将所有的Cache分为16份,每一份为一个LRUCache。
2)LRUCache用来维护所有元素(LRUHandle),通过锁mutex来保证线程安全,同时记录当前
Cache的最大容量和已用内存。
3)每一个LRUCache中有一个循环链表(LRUHandle)和一个hash表(HandleTable),通过循环链
表实现LRU思想,通过hash表来加快查找速度。
假定设置的最大容量为4,即capacity_=4,然后依次向其中插入元素1、5、2、4、9,简单的示意图如下:
当插入元素1,5, 2, 4后,usage=4。每个元素在hash表中的位置为 list [ hash&length_-1 ] ,由此可知 ,1和5,2和4有着相同的hash值,分别对应list[1],list[2]
此时得到如下结果(为简化,与循环链表头部相连的部分指针线未画出):
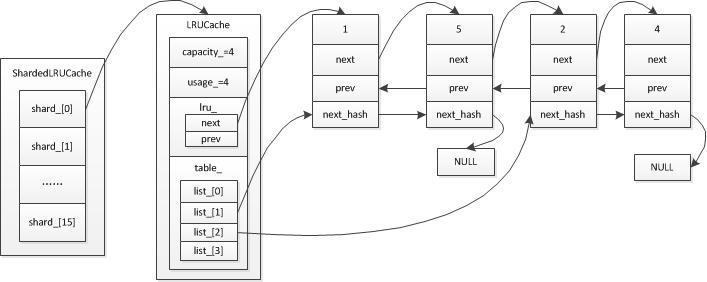
此时已达到最大容量,假设要继续插入一个元素9(对应list[1]),插入9后,usage>capacity,则要从链表头部开始移除元素,即元素1会被移除,得到结果如下:
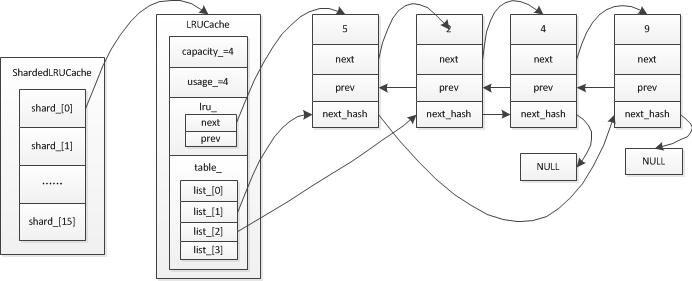















 455
455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









