







本地模式 :
1台主机
不具备HDFS,只能测试MapReduce程序
伪分布模式:
1台主机
具备Hadoop的所有功能,在单机上模拟一个分布式的环境
(1)HDFS:主:NameNode,数据节点:DataNode
(2)Yarn:容器,运行MapReduce程序
主节点:ResourceManager
从节点:NodeManager
全分布模式:
至少3台
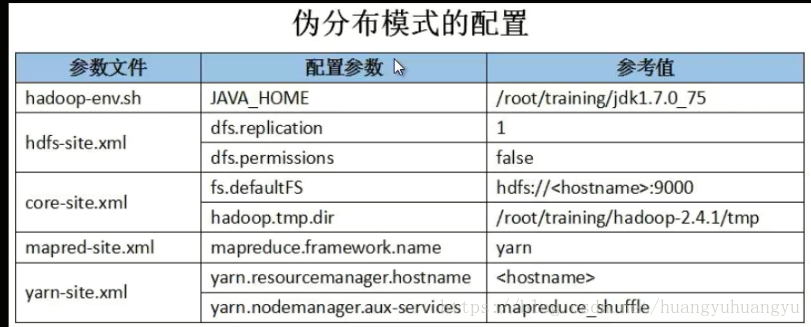
第一个hadoop-env.sh在上篇文章本地模式中有介绍这里不需要更改,就不再赘述
第二个文件hdfs-site.xml这个文件中需要配置两个参数:
第一个参数是dfs.replicaton冗余度,默认值为3,在伪分布环境下配置为1;
第二个参数是dfs.permissions 是进行权限的检查,默认值是true,这里推荐改为false。
切换至配置目录:cd /root/training/hadoop-2.4.1/etc/hadoop/
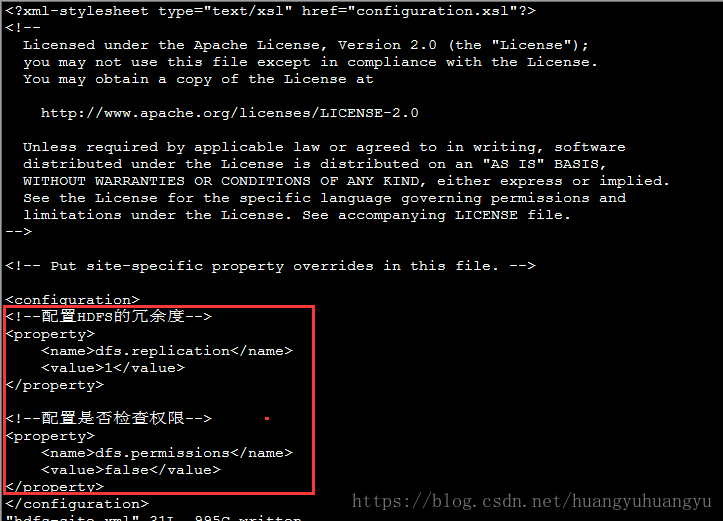
(1)修改hdfs-site.xml:冗余度1、权限检查false
<!--配置HDFS的冗余度-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--配置是否检查权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>将以上配置copy到configuration中
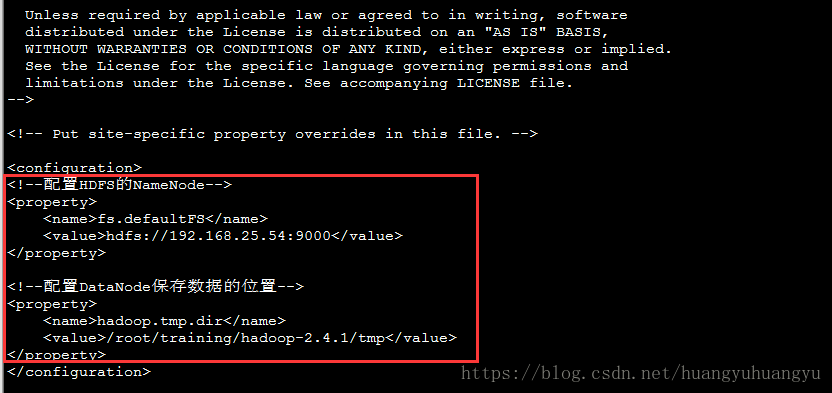
(2)修改core-site.xml
<!--配置HDFS的NameNode-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.25.54:9000</value>
</property>
<!--配置DataNode保存数据的位置-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.4.1/tmp</value>
</property>将以上配置copy到configuration中
(3)修改mapred-site.xml
<!--配置MR运行的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> 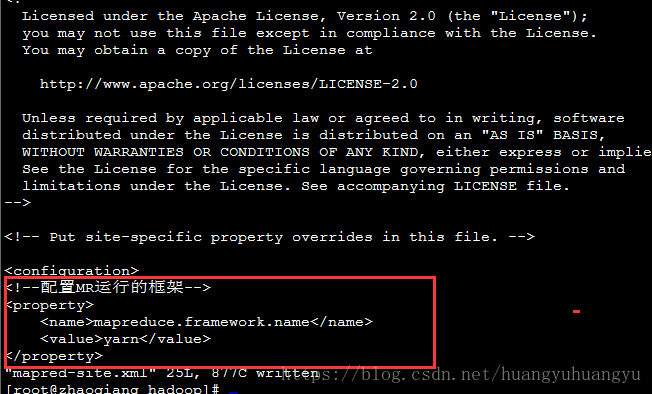
(4)修改yarn-site.xml
先copy一份mapred-site.xml.template修改名为mapred-site.xml

编辑修改mapred-site.xml
<!--配置ResourceManager地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.25.54</value>
</property>
<!--配置NodeManager执行任务的方式-->
<property>
<name>yarn.nodemanager.aux-service</name>
<value>mapreduce_shuffle</value>
</property>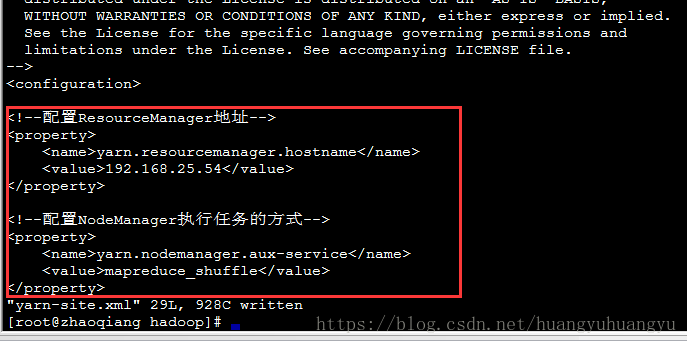
(5)格式化NameNode
因为NameNode是文件系统的管理员,只有经过格式化了才能使用
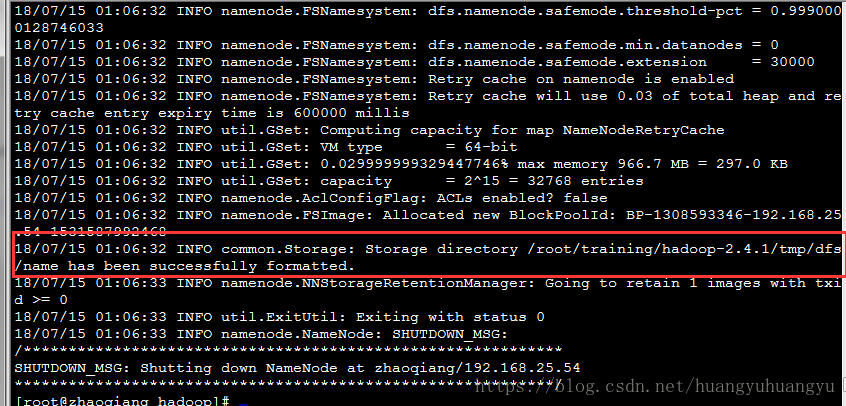
hdfs namenode -format
看到common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted表示格式化成功
(6)启动
start-all.sh
(*)HDFS:存储数据
(*)YARN:执行计算
使用jps查看:
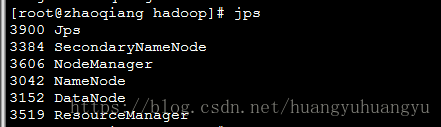
到此我们的伪分布环境就搭建成功了
访问
(*)命令行
(*)Java Api
(*)WEB Console
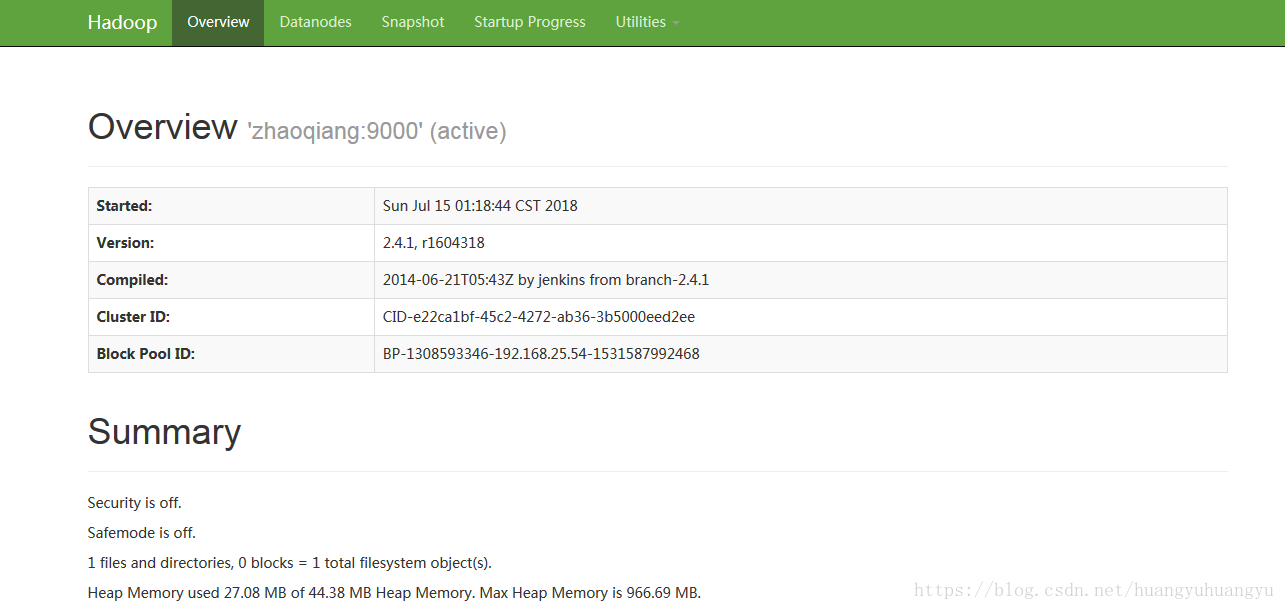
HDFS: http://192.168.25.54:50070
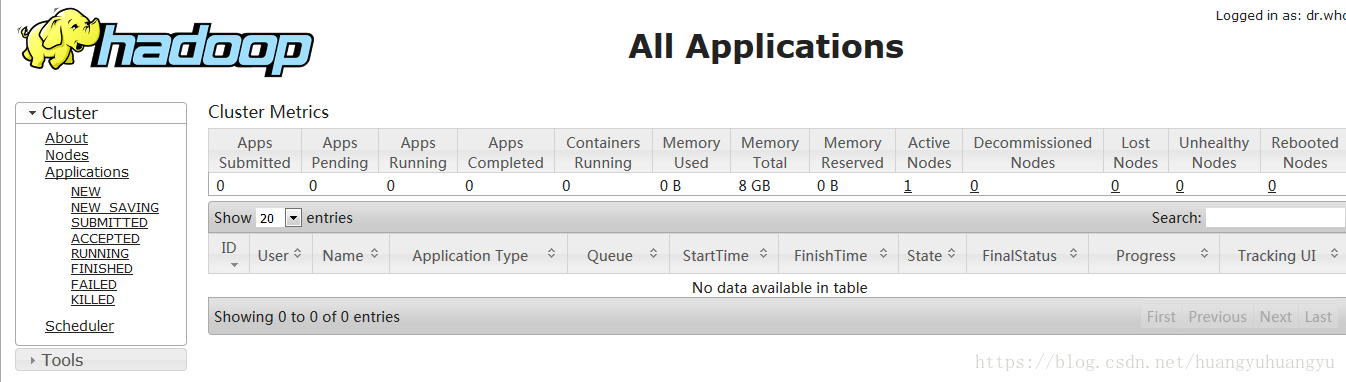
Yarn: http://192.168.25.54:8088














 2338
2338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









