






搜索代码
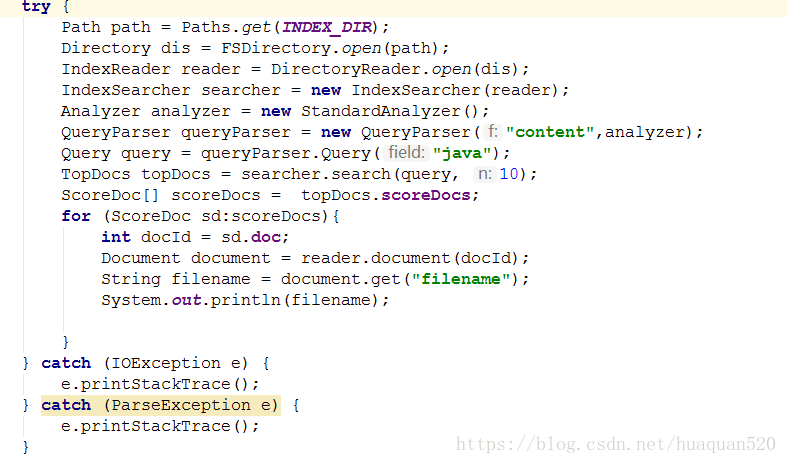
运行时出现如下异常
| org.apache.lucene.queryparser.classic.ParseException: Encountered "<EOF>" at line 1, column 0. Was expecting one of: <NOT> ... "+" ... "-" ... <BAREOPER> ... "(" ... "*" ... <QUOTED> ... <TERM> ... <PREFIXTERM> ... <WILDTERM> ... <REGEXPTERM> ... "[" ... "{" ... <NUMBER> ... <TERM> ... at org.apache.lucene.queryparser.classic.QueryParser.generateParseException(QueryParser.java:931) at org.apache.lucene.queryparser.classic.QueryParser.jj_consume_token(QueryParser.java:813) at org.apache.lucene.queryparser.classic.QueryParser.Query(QueryParser.java:252) at com.qhcccy.lucene.SearchIndex.searchIndex(SearchIndex.java:38) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.junit.platform.commons.util.ReflectionUtils.invokeMethod(ReflectionUtils.java:513) at org.junit.jupiter.engine.execution.ExecutableInvoker.invoke(ExecutableInvoker.java:115) at org.junit.jupiter.engine.descriptor.TestMethodTestDescriptor.lambda$invokeTestMethod$6(TestMethodTestDescriptor.java:170) at org.junit.jupiter.engine.execution.ThrowableCollector.execute(ThrowableCollector.java:40) at org.junit.jupiter.engine.descriptor.TestMethodTestDescriptor.invokeTestMethod(TestMethodTestDescriptor.java:166) at org.junit.jupiter.engine.descriptor.TestMethodTestDescriptor.execute(TestMethodTestDescriptor.java:113) at org.junit.jupiter.engine.descriptor.TestMethodTestDescriptor.execute(TestMethodTestDescriptor.java:58) at org.junit.platform.engine.support.hierarchical.HierarchicalTestExecutor$NodeExecutor.lambda$executeRecursively$3(HierarchicalTestExecutor.java:113) at org.junit.platform.engine.support.hierarchical.SingleTestExecutor.executeSafely(SingleTestExecutor.java:66) at org.junit.platform.engine.support.hierarchical.HierarchicalTestExecutor$NodeExecutor.executeRecursively(HierarchicalTestExecutor.java:108) at org.junit.platform.engine.support.hierarchical.HierarchicalTestExecutor$NodeExecutor.execute(HierarchicalTestExecutor.java:79) at org.junit.platform.engine.support.hierarchical.HierarchicalTestExecutor$NodeExecutor.lambda$executeRecursively$2(HierarchicalTestExecutor.java:121) at java.util.stream.ForEachOps$ForEachOp$OfRef.accept(ForEachOps.java:184) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.Iterator.forEachRemaining(Iterator.java:116) at java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:151) at java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:174) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:418) at org.junit.platform.engine.support.hierarchical.HierarchicalTestExecutor$NodeExecutor.lambda$executeRecursively$3(HierarchicalTestExecutor.java:121) at org.junit.platform.engine.support.hierarchical.SingleTestExecutor.executeSafely(SingleTestExecutor.java:66) at org.junit.platform.engine.support.hierarchical.HierarchicalTestExecutor$NodeExecutor.executeRecursively(HierarchicalTestExecutor.java:108) at org.junit.platform.engine.support.hierarchical.HierarchicalTestExecutor$NodeExecutor.execute(HierarchicalTestExecutor.java:79) at org.junit.platform.engine.support.hierarchical.HierarchicalTestExecutor$NodeExecutor.lambda$executeRecursively$2(HierarchicalTestExecutor.java:121) at java.util.stream.ForEachOps$ForEachOp$OfRef.accept(ForEachOps.java:184) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.Iterator.forEachRemaining(Iterator.java:116) at java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:151) at java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:174) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:418) at org.junit.platform.engine.support.hierarchical.HierarchicalTestExecutor$NodeExecutor.lambda$executeRecursively$3(HierarchicalTestExecutor.java:121) at org.junit.platform.engine.support.hierarchical.SingleTestExecutor.executeSafely(SingleTestExecutor.java:66) at org.junit.platform.engine.support.hierarchical.HierarchicalTestExecutor$NodeExecutor.executeRecursively(HierarchicalTestExecutor.java:108) at org.junit.platform.engine.support.hierarchical.HierarchicalTestExecutor$NodeExecutor.execute(HierarchicalTestExecutor.java:79) at org.junit.platform.engine.support.hierarchical.HierarchicalTestExecutor.execute(HierarchicalTestExecutor.java:55) at org.junit.platform.engine.support.hierarchical.HierarchicalTestEngine.execute(HierarchicalTestEngine.java:43) at org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:170) at org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:154) at org.junit.platform.launcher.core.DefaultLauncher.execute(DefaultLauncher.java:90) at com.intellij.junit5.JUnit5IdeaTestRunner.startRunnerWithArgs(JUnit5IdeaTestRunner.java:65) at com.intellij.rt.execution.junit.IdeaTestRunner$Repeater.startRunnerWithArgs(IdeaTestRunner.java:47) at com.intellij.rt.execution.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:242) at com.intellij.rt.execution.junit.JUnitStarter.main(JUnitStarter.java:70) |
解决办法:
把

改成















 2361
2361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









