



lwIP 数据流与 tcpip_thread
本文对 lwIP 从网卡接收数据到内核处理的完整流程做系统、结构化且可操作的说明。结合 tcpip 源码片段(tcpip_thread / tcpip_inpkt / tcpip_input / tcpip_timeouts_mbox_fetch),重点说明:消息构造与传递、pbuf(所有权)约定、线程与中断的交互、锁策略选项的影响、以及实现驱动时的注意点与常见问题排查方法。
一、整体流程概览
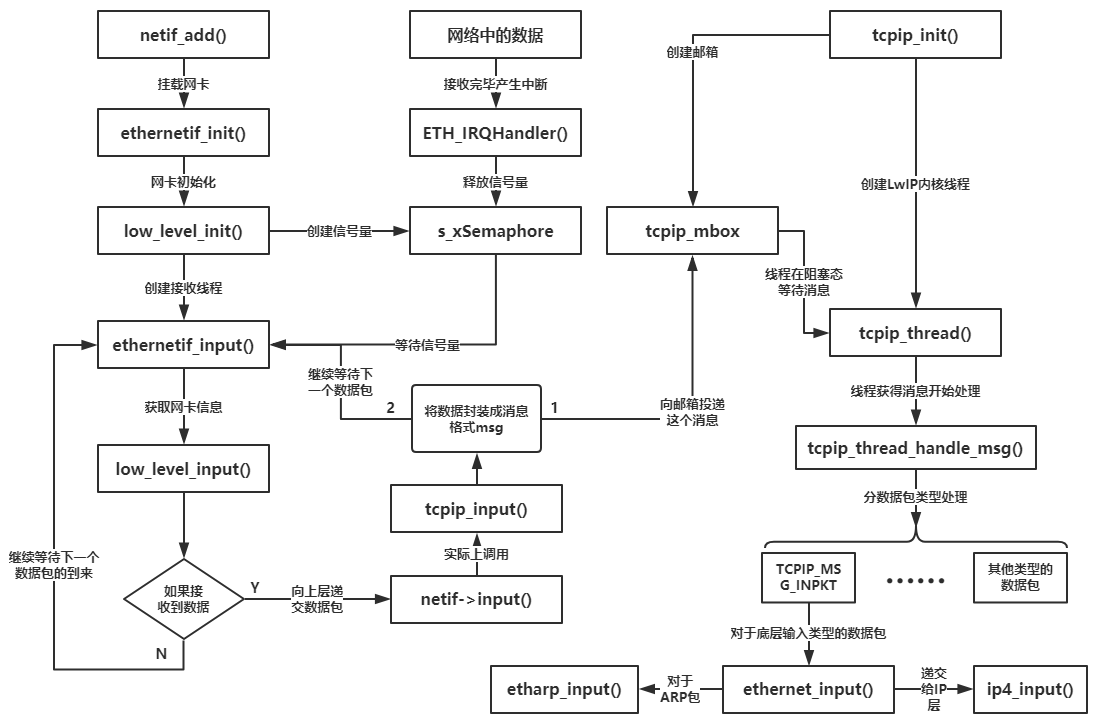
硬件接收帧 → 中断/底层驱动唤醒接收线程 → 驱动把帧打包成 pbuf 并构造 TCPIP_MSG_INPKT 投递到 tcpip_mbox → tcpip_thread 从邮箱取消息并在内核线程上下文执行 ethernet_input/ip_input 等处理(完成后由内核负责后续释放或转发)。
图示中关键环节对应源码:ethernet IRQ → s_xSemaphore → ethernetif_input → low_level_input → tcpip_input/tcpip_inpkt → sys_mbox_post(&tcpip_mbox, msg) → tcpip_thread 的 TCPIP_MBOX_FETCH → tcpip_thread_handle_msg()。
二、分步详解
- 硬件中断与网卡驱动(IRQ 上下文)
- ETH_IRQHandler 中通常只做最小工作:读取/清中断、简短统计、释放接收信号量(例如 s_xSemaphore)或直接使用 sys_mbox_trypost_fromisr/tcpip_callbackmsg_trycallback_fromisr。不要在 ISR 中做耗时拷贝或 pbuf_alloc(可能会阻塞/失败)。
- 接收线程(ethernetif_input)——驱动任务级处理
- 等待信号量被唤醒后调用 low_level_input 获取 DMA 描述符里帧信息。此处会:invalidate D-Cache、计算帧长、决定是否为零拷贝或 memcpy 到 pbuf。常见做法:
- p = pbuf_alloc(PBUF_RAW/PBUF_POOL, len, PBUF_POOL); memcpy 或 pbuf_alloced_custom 填充 DMA 缓冲(零拷贝)。
- 关键:当把 pbuf 交给 tcpip_input 时,驱动不再持有 pbuf 的所有权(除非采用自定义 free 回调归还 DMA)。
- 如果驱动无法上送(mbox 满、pbuf NULL),需统计并正确释放 DMA 描述符,避免卡死 RX。
- tcpip_input / tcpip_inpkt(接口层)
- tcpip_input 根据是否以太网选择 ethernet_input 或 ip_input:
- tcpip_input() → tcpip_inpkt(p, inp, ethernet_input)
- tcpip_inpkt 在 NO_SYS=0 且 !LWIP_TCPIP_CORE_LOCKING_INPUT 情况下,构造 struct tcpip_msg(类型 TCPIP_MSG_INPKT),并 memp_malloc(MEMP_TCPIP_MSG_INPKT),然后 sys_mbox_trypost(&tcpip_mbox, msg)。
- 成功投递后立即返回 ERR_OK;失败需调用方处理(驱动通常在失败路径释放 pbuf 或计数丢包)。
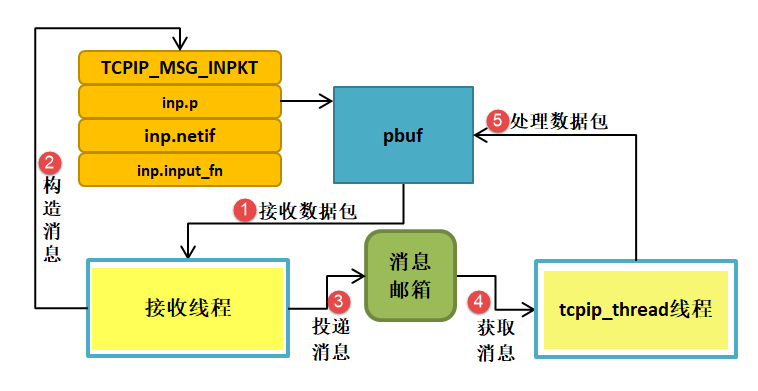
- tcpip_thread:邮箱取消息并处理(核心)
- tcpip_thread 主循环:TCPIP_MBOX_FETCH(&tcpip_mbox, &msg);取到 msg 后调用 tcpip_thread_handle_msg(msg)。
- TCPIP_MBOX_FETCH 在启用定时器(LWIP_TIMERS)时会调用 tcpip_timeouts_mbox_fetch:在等待消息期间处理超时(sys_check_timeouts),保证定时器回调在 tcpip_thread 上下文执行。
- tcpip_thread_handle_msg 对 TCPIP_MSG_INPKT:调用 msg->msg.inp.input_fn(msg->msg.inp.p, msg->msg.inp.netif)。注意:如果 input_fn 返回非 ERR_OK,代码会 pbuf_free(msg->msg.inp.p)。这说明:一旦消息交给 tcpip_thread,上下文切换后失败由内核释放 pbuf。
- ethernet_input / ip_input 处理(协议栈内)
- ethernet_input 解析以太网帧类型,ARP 包由 etharp_input 处理并更新 ARP 表;IP 包调用 ip_input。ip_input 进一步将分片、路由、传给传输层(TCP/UDP)。
- 在处理过程中,pbuf 可能被链式分割、clone 或引用计数(例如转发给上层 socket)。引用计数管理很重要:若 pbuf 被多个对象持有,必须使用 pbuf_ref,释放时由最后持有者调用 pbuf_free。
从上图可以看出Lwip并没有明确的分层。接收通常有一个驱动级的“接收线程”(ethernetif_input),或者只有 ISR + 驱动任务。也就是说常见部署会有 tcpip_thread + 一个或多个网卡驱动线程(再加上若干用户线程)。通常没有一个独立的“发送线程”在 lwIP core 中。发送由调用方(应用线程/stack 内的处理函数)触发,通过 netif->linkoutput / low_level_output 启动 DMA 发送。驱动的 TX 完成由 ISR 处理并通知(或通过回调在 tcpip_thread 上释放 pbuf)。当然如果你想的话也可以把接受线程去掉,直接在中断做接受,不过不建议这么做。
三、消息类型与同步方式(源码对应)
- TCPIP_MSG_API / TCPIP_MSG_API_CALL:用于各类 API 请求(netconn/socket 等)。API_CALL 会带信号量用于同步等待(tcpip_api_call / tcpip_send_msg_wait_sem)。
- TCPIP_MSG_INPKT:接收数据包消息,由驱动投递到 tcpip_mbox。
- TCPIP_MSG_CALLBACK / TCPIP_MSG_CALLBACK_STATIC:用于在 tcpip_thread 上执行回调(pbuf_free_callback、mem_free_callback、或其他延迟处理)。
- 若定义 LWIP_TCPIP_CORE_LOCKING:可以在调用线程直接通过 LOCK_TCPIP_CORE() 执行内核相关函数,避免消息收发开销(但要正确处理互斥)。若定义 LWIP_TCPIP_CORE_LOCKING_INPUT:驱动可以直接在驱动线程调用 input_fn(p, inp)(在驱动线程内获得锁),不再构造 TCPIP_MSG_INPKT。选择策略与系统可预见性/实时性有关。
四、tcpip_timeouts_mbox_fetch 的作用
- 当启用 LWIP_TIMERS 时,tcpip_thread 需要既能处理来自驱动的消息,也要在正确线程上下文调用 sys_check_timeouts。tcpip_timeouts_mbox_fetch 的逻辑:
- 计算下一次超时 sleeptime;若为 infinite,则阻塞等待消息;若为 0,立即调用 sys_check_timeouts 并重试取消息;否则在解锁并等待 mbox 的 sleeptime 时间,若超时则处理超时后重试取消息。
- 结果:tcpip_thread 同时成为消息处理与系统定时器的执行线程。实现上要求 lock/unlock 核心时机正确,避免死锁。
五、pbuf 所有权与调用约定
- 驱动分配 pbuf 后上送 tcpip_input(投递消息)时,驱动必须遵循:
- 一旦将 pbuf 交给 tcpip_inpkt 并成功投递消息,驱动不能再直接访问或释放该 pbuf(除非是自定义 pbuf 的 free 回调机制)。
- 如果 sys_mbox_trypost 失败(投递失败路径),驱动必须负责释放 pbuf(pbuf_free)并归还 DMA 描述符。否则会泄漏或丢帧。- tcpip_thread 在处理 input_fn 时若返回 ERR_OK,则内核继续持有并按协议层逻辑转交;若返回非 ERR_OK,tcpip_thread 会调用 pbuf_free。
- 若使用零拷贝(pbuf_alloced_custom),必须提供 custom_free_function 在最后释放时归还 DMA buffer;确保 custom_free_function 在 tcpip_thread 或安全上下文中运行或做原子归还。
六、实现驱动与系统配置建议
- 在 IRQ 中尽量只做通知(sem/give/try_post_fromisr),不要做 pbuf_alloc/mem_malloc。- ethernetif_input 中做 pbuf_alloc(PBUF_POOL, len, PBUF_POOL) 或 pbuf_alloced_custom(零拷贝)并尽快 sys_mbox_trypost;若 mbox 满,采用退避/统计丢包并及时归还 DMA 描述符。- lwipopts.h 推荐关注:TCPIP_MBOX_SIZE(邮箱深度)、PBUF_POOL_SIZE、MEMP_TCPIP_MSG_INPKT 的池大小、LWIP_TCPIP_CORE_LOCKING 与 LWIP_TCPIP_CORE_LOCKING_INPUT 的配置。mbox 太小会导致驱动投递失败并丢包。- 若平台有 CPU cache,务必在传给 DMA/从 DMA 读取前做 DCache Clean/Invalidate。零拷贝更依赖缓存一致性。- 若对延迟敏感,考虑:LWIP_TCPIP_CORE_LOCKING 可以减少消息切换,但需要正确使用 LOCK_TCPIP_CORE/UNLOCK。
七、常见故障与排查要点
- 接收突然停止 / pbuf 在驱动中无法分配:检查 PBUF_POOL_SIZE 与 MEMP_NUM_PBUF 使用率(开启 MEMP_STATS)并统计 memp_malloc 失败计数。- mailbox 满导致丢包:增加 TCPIP_MBOX_SIZE 或在驱动中使用带退避的重试/丢弃策略;记录 sys_mbox_trypost 失败的次数。- pbuf 双重释放/崩溃:检查是否在驱动把 pbuf 交给 tcpip 后仍然访问/释放;检查是否正确使用 pbuf_ref。- 定时器不执行:检查 LWIP_TIMERS 与 tcpip_timeouts_mbox_fetch 是否启用;确认 tcpip_thread 正常运行且没有长时间阻塞。- 中断上下文调用错误 API:不能在 ISR 中直接调用 pbuf_free(应使用 pbuf_free_callback/tcpip_try_callback_fromisr)。
八、构造时序
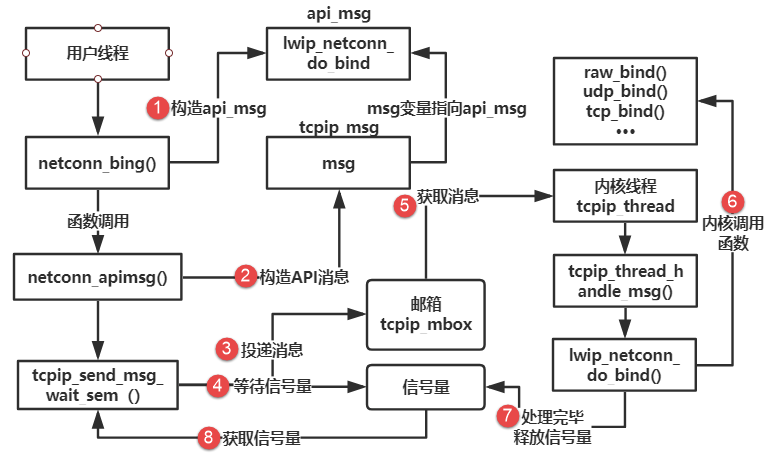
-
用户线程调用 netconn_bind()/socket API
- 由上层 API 构造“api_msg”或 netconn_apimsg(携带参数、指针、等待信号等)。
-
构造 tcpip_msg(包装 API)
- tcpip 层用 memp_malloc(MEMP_TCPIP_MSG_API) 分配 struct tcpip_msg,设置 type = TCPIP_MSG_API 或 TCPIP_MSG_API_CALL,并填充 msg.api_msg / msg.api_call 字段(即要在 tcpip_thread 调用的函数指针与参数)。
-
投递消息到 tcpip_mbox(sys_mbox_post 或 trypost)
- 阻塞型一般用 sys_mbox_post;从 ISR/try 用 trypost_fromisr/trypost。若失败要返回 ERR_MEM 并释放相关资源(pbuf/参数)。
-
用户线程等待信号量(sys_arch_sem_wait)
- 等待方式视实现:tcpip_send_msg_wait_sem 会创建/使用一个信号量并在投递后等待;当使用 LWIP_NETCONN_SEM_PER_THREAD 时,线程复用 semaphore,降低开销。
-
tcpip_thread 从 tcpip_mbox 取到消息(TCPIP_MBOX_FETCH)并分发处理
- tcpip_thread_handle_msg 对 TCPIP_MSG_API:执行 msg->msg.api_msg.function(msg->msg.api_msg.msg)
- 对 TCPIP_MSG_API_CALL:执行并将返回值写入 call->err,随后 sys_sem_signal 用于唤醒等待者
-
实际的 API 实现函数在 tcpip_thread 上下文执行(例如 wip_netconn_do_bind)
- 在这里可以安全访问 lwIP 内核数据结构(netif、pcb、memp 等),无需再跨线程同步(除非你禁用 core locking)。
-
处理完毕后释放/signal
- 对于 API_CALL 模式,tcpip_thread 会直接 sys_sem_signal(msg->msg.api_call.sem)。
- 对于普通 API(TCPIP_MSG_API),被调用的函数通常负责在完成时做 sys_sem_signal(tcpip_send_msg_wait_sem 的设计),调用者随后继续执行并做 TCPIP_MSG_VAR_FREE。
-
用户线程获得信号量,继续执行并清理(free msg 等)
- TCPIP_MSG_VAR_FREE 或 memp_free 会由调用者或 tcpip_thread 按配置释放(见 API_VAR_* 宏的行为)。
九、结论
- 明确“pbuf 的所有权转移”是理解整个流程的关键:驱动把 pbuf 交给 tcpip_thread 后不再访问;tcpip_thread(或协议栈)负责释放或转移所有权。- 选择 LWIP_TCPIP_CORE_LOCKING 与 LWIP_TCPIP_CORE_LOCKING_INPUT 影响性能与复杂度:锁能减少消息开销但需正确互斥;无锁设计更通用但会有线程切换开销。- 对于高吞吐场景,优先保证 RX 不会被 PBUF_POOL/TCPIP_MBOX 等资源饿死:合适的缓冲大小、合理的 mailbox 大小与驱动退避/统计是必要的工程手段。

















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









