







选举机制
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking(选举状态)。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟。
分布式锁
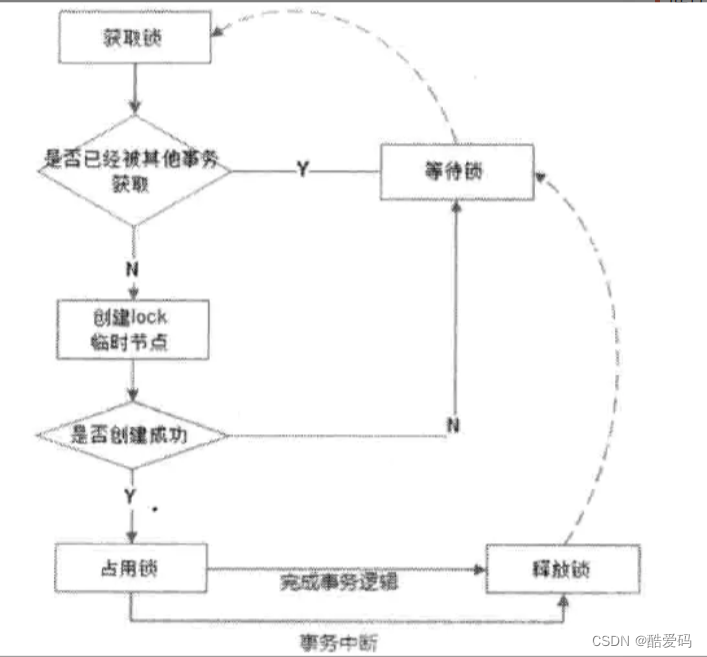
1)查看目标Node是否已经创建,已经创建,那么等待锁。
2)如果未创建,创建一个瞬时Node,表示已经占有锁。
3)如果创建失败,那么证明锁已经被其他线程占有了,那么同样等待锁。
4)当释放锁,或者当前Session超时的时候,节点被删除,唤醒之前等待锁的线程去争抢锁。
zookeeper四种类型的znode

zookeeper的通知机制
Znode发生变化(Znode本身的增加,删除,修改,以及子Znode的变化)可以通过Watch机制通知到客户端。那么要实现Watch,就必须实现org.apache.zookeeper.Watcher接口,并且将实现类的对象传入到可以Watch的方法中。Zookeeper中所有读操作(getData(),getChildren(),exists())都可以设置Watch选项。Watch事件具有one-time trigger(一次性触发)的特性,如果Watch监视的Znode有变化,那么就会通知设置该Watch的客户端。
如何保证主从节点状态同步
1)顺序一致性
来自客户端的更新将严格按照客户端发送的顺序处理;
2)原子性
更新或者成功或者失败,不存在部分成功或者部分失败的场景;
3)单一视图
无论客户端连接到哪个服务器,看到的都是一样的视图;
4)可靠性
一旦一个更新生效,它将一直保留,直到再次更新;
5)实时性
在特定的一段时间内,任何系统的改变都能被客户端看到,或者被监听到。
,直到再次更新;
5)实时性
在特定的一段时间内,任何系统的改变都能被客户端看到,或者被监听到。
















 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











