







前提条件:
安装好hadoop2.7.3(Linux系统下)
安装好Flume,参考:Flume安装配置
原理:
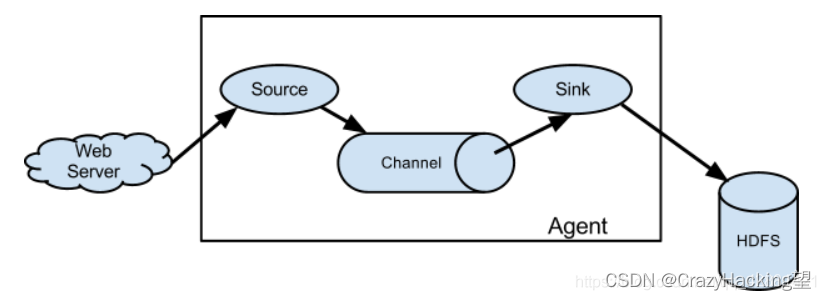
Flume数据流模型
题目:
完成通过Avro Source接收外部数据源,数据缓存在memory channel中,然后通过Logger sink将打印出数据,即:
avro source --> memory channel --> logger sink
步骤:
1.进入有权限的目录,例如~目录
cd ~
2.创建配置文件avro.conf(关键)
vim avro.conf
内容如下:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#配置source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
# 配置sink
a1.sinks.k1.type = logger
# 配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 绑定 source 和sink 到 channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3.启动Flume agent
flume-ng agent --conf ./ --conf-file avro.conf --name a1 -Dflume.root.logger=INFO,console
注意: --conf为配置文件所在目录,这里配置为"./"表示当前目录; --conf-file表示配置文件名称; --name表示 flume代理名称,其他的为日志级别
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









