









——清明给自己放了假,见了高中老铁和他妻子,谨以此博客献给这幸福的一对,就这样度过一生哦:)
我们开始讲我们的第一个估计value functions、发现optimal policies的学习方法。
由于这一系列[RL]的博客都是围绕着增强学习问题讲的,因此建议从[RL] 3 Finite Markov Decision Processes (1)看起,至少需要了解建好的MDP模型。
与之前不同,这里我们不再假设我们完全了解environment。蒙特卡洛方法(Monte Carlo Methods)需要的只是经验(experience)——一些从实际或仿真环境得到的states、actions和rewards序列的样本。从实际经验中学习policy是非常吸引人的,因为它不需要对环境的变化
p(s′,r∣s,a)
有一个先验的知识。
蒙特卡罗方法是基于平均样本回报来解决强化学习问题的方法。为了确保return有良好的定义,我们只在episodic task下讨论蒙特卡洛方法,即任务存在终结状态。蒙特卡洛方法只有在每一个episode结束的时候,才会进行value estimates、改变policies,因此,是一个episode-by-spisode的学习过程,而不是step-by-step的学习过程。
术语“蒙特卡罗”通常用于一些估计方法,它们操作具有显著的随机成分。比如用蒙特卡洛方法估计圆周率,在边长为2的正方形里作一个半径为1的圆,然后随机生成一批点,根据点在圆内和圆外的概率估计圆周率。
我们会沿用General Policy Iteration (GPI)的想法,先考虑预测问题,即在给定 policyπ 的情况下,计算 vπ,qπ ,然后改进policy,最终根据GPI将问题收敛,得到解。不同的是,DP根据对MDP的了解来计算value function,而蒙特卡洛方法则是根据return的采样来学习得到value function。
Monte Carlo Prediction
我们先考虑使用蒙特卡洛方法学习给定policy下的state-value function。
回顾一下,一个state的value,是它所能获得的return的期望,即从它开始累积reward的期望。
一个使用experience来估计state-value的直观方法,即简单的对experience中,经过state s后获得的return取平均值。随着经过state s后获得的return越来越多地被观测到,均值将收敛到期望值。这个想法是所有蒙特卡洛方法的基础。
假设我们要估计
vπ(s)
,即
policyπ
下state s的value,给出一个遵循
policyπ
并且经过s的episodes集合。在某个episode中,state s的每一次出现我们称为对s的一次访问(visit)。显然,在同一个episode中s可能被多次访问到,我们称s在一个episode中的第一次访问为first visit。
使用蒙特卡洛方法估计
vπ(s)
有两种方法。first-visit MC method:使用s的first visit得到的return的均值来估计
vπ(s)
。every-visit MC method:使用所有s的visit得到的return的均值来估计
vπ(s)
。这两种方法很相似,但具有略微不同的理论性质。first-visit MC method已经有了广泛的研究,也是我们这里要讲的重点,下面给出伪代码:
Initialize:
π←policytobeevaluated
V←anarbitrarystate-valuefunction
Returns(s)←anemptylist,foralls∈S
Repeat forever:
Generateanepisodeusingπ
Foreachstatesappearingintheepisode:
G←returnfollowingthefirstoccurrenceofs
AppendGtoReturns(s)
V(s)←average(Returns(s))
first-visit MC和every-visit MC两种方法,随着对s的访问次数增加,都可以收敛到 vπ(s) 。对于first-visit MC,每一个return是独立同分布的,都是在有限的方差下对 vπ(s) 的估计,根据大数定理,这些returns的均值,最终会收敛到 vπ(s) 。而且,returns的均值是一个无偏估计,误差的标准差会降到 1n√ ,n为returns的数量(这我们称为是二次收敛的)。every-visit MC并没有这么直接,但它的估计也是二次收敛到 vπ(s) 的。
关于蒙特卡洛方法的一个重要事实:每个state的估计是相互独立的。对一个state的估计不依赖于另一个state。
另外,值得注意的是,估计一个state的计算开销,与states的总数目无关。因此,如果只需要估计一个或几个states的value时,蒙特卡洛算法是非常有吸引力的。
Monte Carlo Estimation of Action Values
在有些情况下,估计action value会比state value更有意义。因此,对我们而言,蒙特卡洛方法的一项重要任务是估计
q∗
。为了实现这个目标,我们首先考虑policy evaluation问题,即估计
qπ(s,a)
——在state s下选择action a,之后遵循policy
π
的期望return。
用蒙特卡洛方法估计action value,思想和估计state value时一样,不同的是我们考虑的是对state-action的访问,而不是对state的访问。当然,估计action value的蒙特卡洛方法也分为every-visit MC和firs-visit MC。这两种方法最终都二次收敛到
qπ(s,a)
。
唯一有问题的是,有些state-action可能永远都不会被访问到。比如,如果
π
是一个确定型的policy,对于一个state,只会采取一个action,因此我们只能观测到这对state-action的return。那么通过experience,蒙特卡洛方法并不能估计其他一些state-action的action value。这是一个严重的问题,因为我们学习action value的目的就是在一堆可选的action中选择一个最优的action。
对于每一个state,我们需要估计所有action的value。这个问题我们称为maintaining exploration,就和我们在k-armed bandit problem中讨论过的一样。对于action value的policy evaluation问题,我们需要保证持续的exporation(探索)。一个方法是为每一个state-action,赋予一个非零的概率,使它可以作为episode的起始动作。这就保证了随着episodes的数量趋向于无穷,每个state-action的访问次数也趋向于无穷。这种方法我们称为exploring starts。
exploring starts非常有用,但它依然不能成为我们的依赖。特别是通过与环境的实际交互,直接从中学习的时候。更好的方法是,使用非确定型的policy,并保证对于每个state,对于每个可选的action,都有一个非零的概率。
Monte Carlo Control
我们现在考虑如何使用蒙特卡洛估计,来获得近似的最优policy。大致的想法来源于Generalized Policy Iteration (GPI)。
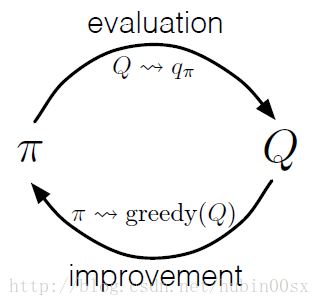
图1 GPI
我们先考虑policy iteration的蒙特卡洛版本。我们从任意的 policyπ0 开始,交替地执行evaluation和improvement,如图2。
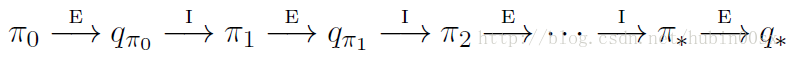
图2 policy iteration
其中 −→E 代表policy evaluation, −→I 代表policy improvement。蒙特卡洛版本的policy evaluation已经在Monte Carlo Prediction和Monte Carlo Estimation of Action Values两节中说明,随着越来越多的episodes被experienced,我们通过蒙特卡洛方法估计的value function会越来越接近真正的value function。
现在我们说明蒙特卡洛版本的policy improvement。首先我们假设已经观测到了无穷多个由exploring starts生成的episodes。在这个假设下,对任意的 πk ,蒙特卡洛policy evaluation可以计算 qπk 。
根据当前的value function,greedy地选择policy就可以实现policy improvement。在确定型的policy下,即:
这就是蒙特卡洛版的policy improvement,对于给定的 qπk ,可以得到 πk+1 。在之前的博客Dynamic Programming中讲的policy improvement theorem同样适用于 πk,πk+1 ,因为对于任意的 s∈S 有:
就像我们在DP中讲的一样,policy improvement theorem保证了 πk 序列是非下降的,当 πk+1 和 πk 一样好的时候,我们就得到了optimal policy。这也保证了GPI的整个过程最终会收敛到optimal policy和optimal value function。通过这种方法,仅仅需要采样一些episodes,不需要其他对environment的了解,就可以使用蒙特卡洛方法找到optimal policy。
为了得到收敛的保证,我们做了两个不太可能的假设。一是exploring starts,还有一个是有无穷多个episodes供policy evaluation使用。在实际应用中,我们可以抛掉这两个假设。对于第一个假设,我们将在之后展开讲一些方法。
这里我们展开讲一下第二个假设。其实在DP方法里也有这个问题,在policy evaluation的时候,我们迭代地求得的value function只是在渐渐逼近真实的value function。迭代的次数越多,越接近真实值,而这里episodes的数量越多,估计地就越准确。对于DP和MC中,有两种方法解决这个问题。一个是设定一个误差的允许范围,只要在每次policy evaluation的时候,采取足够的措施,使得误差足够小即可。这种方法,可以得到某种程度上的近似值。当然,除非问题的规模非常小,这种方法还是需要足够多的episodes。另一种避免无穷多的episodes的方法,是放弃在执行policy improvement之前完整地做完policy evaluation(极端的,就好像value iteration)。
对于MC来说,基于episode-by-episode,evaluation和improvement之间的任意选择是天然的。在每个episode之后,对所有该episode访问到的state做一次policy improvement。伪代码如下,我们称该算法为Monte Carlo ES:
Initialize, for all s∈S,a∈A(s):
Q(s,a)←arbitrary
π(s)←aribitrary
Returns(s,a)←emptylist
Repeart forever:
Choose S0∈SandA0∈A(S0) , s.t. all pairs have probability > 0
Generate an episode starting from S0,A0 , following π
For each pair s,a appearing in the episode:
G←returnfollowingthefi rstoccurrenceofs,a
AppendGtoReturns(s,a)
Q(s,a)←average(Returns(s,a))
For each s in the episode:
π(s)←argmaxaQ(s,a)
注意在Monte Carlo ES中,state-action的所有return都会累积求平均,而不会管当前policy是什么。
容易看出,Monte Carlo ES算法不会收敛到次优policy。如果它收敛到了次优policy,那么随着episode-by-episode,value function会收敛到真实的value function,而这又会导致policy的改变。只有在policy和value function都是最优的时候,才会达到一个稳定状态。
随着episode-by-episode,value function的变化越来越小,收敛到optimal不动点看上去是必然的,但这尚未被证明。这是增强学习中,最根本的开放性理论问题之一。
Next Blog
本篇博客已经将蒙特卡洛方法描述清楚了。唯一不足的是,我们还没有把exploring starts的假设抛掉,下一篇博客讲扩展这部分内容。目测了一下,略艰涩:(
想起自己就要做伴郎了,激动之情难以自抑:)要好好准备呀:)














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









