






 本文介绍了HBase的基本操作及存储方式,并通过实例演示如何使用MapReduce进行HBase数据处理。包括表结构配置、数据读写及MapReduce任务设置等关键步骤。
本文介绍了HBase的基本操作及存储方式,并通过实例演示如何使用MapReduce进行HBase数据处理。包括表结构配置、数据读写及MapReduce任务设置等关键步骤。
前面已经对HBASE有了不少了解了,这篇重点在实践操作。HBase本身是一个很好的Key-Value的存储系统,但是也不是万能的,很多时候还是要看用在什么情形,怎么使用。KV之类的数据库就是要应用在这类快速查找的应用上,而不是像传统的SQL那样关联查询,分组计算,这些可就不是HBase的长处了。下面先来观察下HBase的基本操作和存储,然后介绍下基于HBASE的MapReduce怎么写,在一些应用可能需要的Coprocessor又该怎么玩。
创建一个表test,查看表结构,顺便说下,表结构里面的很多选项是很重要的,DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS
=> '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLO
CKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'这些都是默认的指,可以根据实际需要修改这些选项,对存储和性能有着重要的影响。
hbase(main):023:0> create 'test',{NAME=>'cf1'},{NAME=>'cf2'}
0 row(s) in 0.4220 seconds
hbase(main):024:0> describe 'test'
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS
=> '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLO
CKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
{NAME => 'cf2', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS
=> '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLO
CKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
hbase(main):025:0> put 'test','R001','cf1:c1','v1'
0 row(s) in 0.0170 seconds
hbase(main):026:0> scan 'test'
ROW COLUMN+CELL
R001 column=cf1:c1, timestamp=1457938795242, value=v1
1 row(s) in 0.0240 seconds
hbase(main):027:0> flush 'test'
0 row(s) in 0.3540 seconds
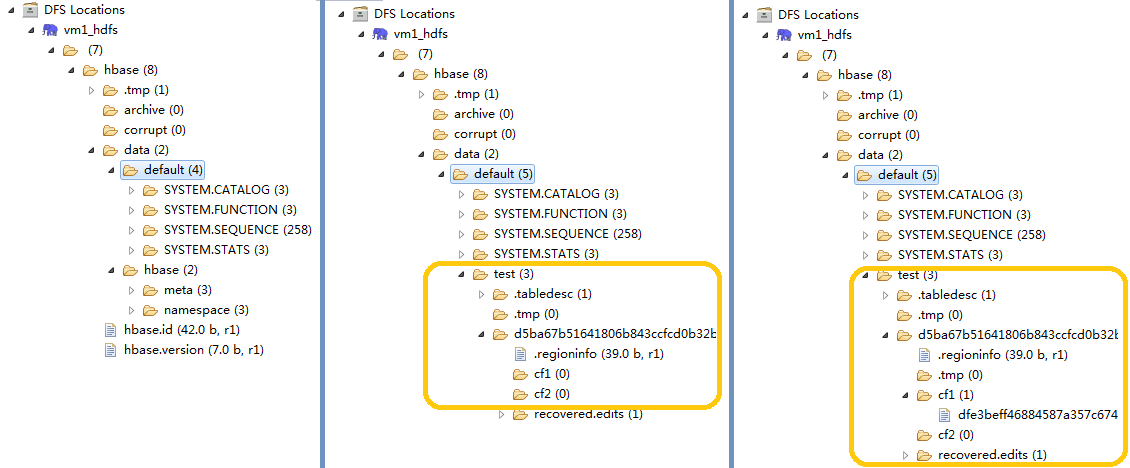
可以在HDFS里面观察下HBase数据在HDFS里面是怎么存放的。左边是系统安装之后,没有建表的情形;
中间的部分是建立了test表之后多出来了一个test目录,两个列族也看到了;
右边是强制flush数据之后看到列族下面多了一个文件,窥豹一斑,可见HBase的数据存储。
HBase的MapReduce怎么写
import java.io.IOException;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MR4Hbase {
public static class WordCountHbaseReaderMapper extends TableMapper<Text, Text> {
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context)
throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer("");
for (Entry<byte[], byte[]> entry : value.getFamilyMap("cf1".getBytes()).entrySet()) {
String str = new String(entry.getValue());
if (str != null) {
sb.append(new String(entry.getKey()));
sb.append(":");
sb.append(str);
}
context.write(new Text(key.get()), new Text(new String(sb)));
}
}
}
public static class WordCountHbaseReaderReduce extends Reducer<Text, Text, Text, Text> {
private Text result = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text val : values) {
result.set(val);
context.write(key, result);
}
}
}
public static void main(String[] args) throws Exception {
String tablename = "t";
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "vm1,vm2,vm3");
conf.set("hbase.zookeeper.property.clientPort", "2181");
System.out.println("---start---");
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 1) {
System.err.println("Usage: MR4Hbase <out>");
System.exit(2);
}
Job job = new Job(conf, "MR4Hbase");
job.setJarByClass(MR4Hbase.class);
FileOutputFormat.setOutputPath(job, new Path(otherArgs[0]));
job.setReducerClass(WordCountHbaseReaderReduce.class);
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes("key973"));
scan.setStopRow(Bytes.toBytes("key999"));
TableMapReduceUtil.initTableMapperJob(tablename, scan, WordCountHbaseReaderMapper.class, Text.class, Text.class,
job);
// job.waitForCompletion(true)
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
下面几个例子都是使用mapreduce读写hbase数据的:
Configuration config = HBaseConfiguration.create();
Job job = new Job(config, "ExampleRead");
job.setJarByClass(MyReadJob.class); // class that contains mapper
Scan scan = new Scan();
scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobs
scan.setCacheBlocks(false); // don't set to true for MR jobs
// set other scan attrs
...
TableMapReduceUtil.initTableMapperJob(
tableName, // input HBase table name
scan, // Scan instance to control CF and attribute selection
MyMapper.class, // mapper
null, // mapper output key
null, // mapper output value
job);
job.setOutputFormatClass(NullOutputFormat.class); // because we aren't emitting anything from mapper
boolean b = job.waitForCompletion(true);
if (!b) {
throw new IOException("error with job!");
}
public static class MyMapper extends TableMapper<Text, Text> {
public void map(ImmutableBytesWritable row, Result value, Context context) throws InterruptedException, IOException {
// process data for the row from the Result instance.
}
}
public static class MyMapper extends TableMapper<ImmutableBytesWritable, Put> {
public void map(ImmutableBytesWritable row, Result value, Context context) throws IOException, InterruptedException {
// this example is just copying the data from the source table...
context.write(row, resultToPut(row,value));
}
private static Put resultToPut(ImmutableBytesWritable key, Result result) throws IOException {
Put put = new Put(key.get());
for (KeyValue kv : result.raw()) {
put.add(kv);
}
return put;
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









