







Python Pandas DataFrame多维的列索引 如何展开成为一维索引?
df_stat = df.groupby(['Student ID'],as_index=False)['entropy', 'Out Count', 'In Count'].agg(['mean','std'])
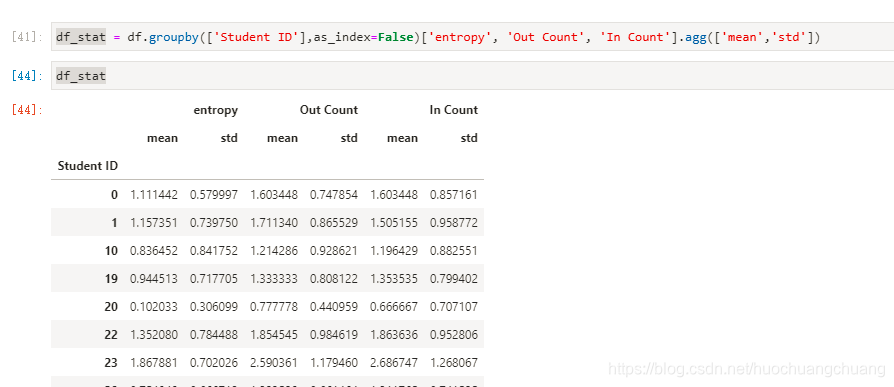
df_stat.columns
MultiIndex(levels=[[‘entropy’, ‘Out Count’, ‘In Count’], [‘mean’, ‘std’]],
codes=[[0, 0, 1, 1, 2, 2], [0, 1, 0, 1, 0, 1]])
def flatten_multi_index(multi_index, join_str='_'):
"""把 MultiIndex 转为 Index
把多维index 展平为 1 维index
参数:
-----------
multi_index: MultiIndex 对象 通过Dataframe.columns 即可得到
join_str: str, 连接字符串
返回:
-----------
index:
1 维 index
"" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 85
85











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









