







分析网站的基本指标
网站基本指标
- PV:page view ,浏览量
- 网站各网页被浏览的总次数
- 用户没打开一个页面就记录一次,多次打开同一页面,访问量累加
- UV:Unique vistor,独立访客数
- 一天内访问某站点的人数(以cookie为依据)
- 一天内同一个访客只记录一次
- VV:Visit View,访客的访问次数
- 记录所有访客一天内访问网站次数
- 当访客完成浏览,并关闭该网站所有页面时记录一次访问
- IP:独立IP数
- 一天内不同IP地址的用户访问网站的数量
- 同一IP不管访问几个页面,独立IP均为1.
日志MapReduce程序获取网页PV指标的
代码
package com.hao.bigdata.hadoop.mapreduce.webPV;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WebPVMapReduce extends Configured implements Tool {
// maper classs
/***
* @author hao public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*/
public static class WebMapper extends
Mapper<LongWritable, Text, IntWritable, IntWritable> { // extends-mapper-jilei
// set map output value
private final static IntWritable mapOutputvalues = new IntWritable(1);
private IntWritable mapOutputKey = new IntWritable();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// line value
String lineValue = value.toString();
// split
String[] values = lineValue.split("\\t");
if (values.length < 30) { //筛选数据,过滤不合格的数据
context.getCounter("APPMAPPER_COUNTERS", //记录不合格数据的数量
"LENGTH_LT30_COUNTER")//
.increment(1L);
return;
}
String provinceIdValues = values[23]; //定义provinceIdValues
String url = values[1]; //定义网站IP
// validate provinceIdValues,url
if (StringUtils.isBlank(provinceIdValues)) {
//计数器,记录provinceIdValues为空的数据数量
context.getCounter("APPMAPPER_COUNTERS",
"provinceIdValues_BLANK_COUNTER")//
.increment(1L);
return;
}
if (StringUtils.isBlank(url)) {
//记录url为空的数量
context.getCounter("APPMAPPER_COUNTERS","URL_BLANK_COUNTER")//
.increment(1L);
return;
}
int provinceId = Integer.MAX_VALUE;
try {
provinceId = Integer.valueOf(provinceIdValues);
} catch (Exception e) {
//记录转换报错的数据
context.getCounter("APPMAPPER_COUNTERS",
"PROVINCEDID_CATCH_COUNTER")//
.increment(1L);
return;
}
if (Integer.MAX_VALUE == provinceId) {
context.getCounter("APPMAPPER_COUNTERS",
"PROVINCEDID_MAXVALUE_COUNTER")//
.increment(1L);
return;
}
// set mapOutputKey ,设置map输出的key
mapOutputKey.set(provinceId);
// output--输出数据
context.write(mapOutputKey, mapOutputvalues);
}
}
// reducer class
/**
* * @author hao public class Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
*/
public static class WebReducer extends
Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
private IntWritable OutputValue = new IntWritable();
@Override
public void reduce(IntWritable key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
int sum = 0;
// interator--迭代器,循环获取数据
for (IntWritable value : values) {
sum += value.get();
}
// set,reduce,outputvalues --设置reduce输出的value
OutputValue.set(sum);
// output,reduce --输出reduce数据
context.write(key, OutputValue);
}
}
// driver
public int run(String args[]) throws Exception {
// step 1: get Configuration
Configuration configuration = super.getConf();
// step 2: creat Job chuanlian input-> map->reduce->output
Job job = Job.getInstance(configuration, this.getClass()
.getSimpleName());
job.setJarByClass(this.getClass()); // jar bao
/**
* step 3:job input ->map ->reduce ->output
*/
// step 3.1:input
Path inpath = new Path(args[0]); // fengzhuang lujing
FileInputFormat.addInputPath(job, inpath);
// step 3.2:mapper
job.setMapperClass(WebMapper.class);
job.setMapOutputKeyClass(IntWritable.class); // zhiding,map,shuchu<key,value>leixing
job.setMapOutputValueClass(IntWritable.class);
// =============shuffle========================
// partitioner
// job.setPartitionerClass(cls);
// sort
// job.setSortComparatorClass(cls);
// combin
job.setCombinerClass(WebReducer.class);
// compress
// set by configuration
// group
job.setGroupingComparatorClass(cls);
// ==============shuffle=======================
// step 3.3:reducer
job.setReducerClass(WebReducer.class);// zhiding,reduce,shuchu<keyK,value>,leixing
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
/*
* //set reduce num job.setNumReduceTasks(0);
*/
// step 3.4:output
Path outpath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outpath);
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0 : 1;
}
// main
public static void main(String[] args) throws Exception {
// args = new String[] {
// "hdfs://bigdata00.hadoop-hao.com:8020/data/inputFiles/inputWeb",
// "hdfs://bigdata00.hadoop-hao.com:8020/data/outputFiles/outputWeb001"
// };
//
// create configuration
Configuration configuration = new Configuration();
// run job
int status = ToolRunner.run(configuration, new WebPVMapReduce(), args);
// exit program
System.exit(status);
}
}
输出结果
将mapreduce程序封装成jar包,然后执行
执行mapreduce程序

输出结果中的计数器显示

查看输出结果
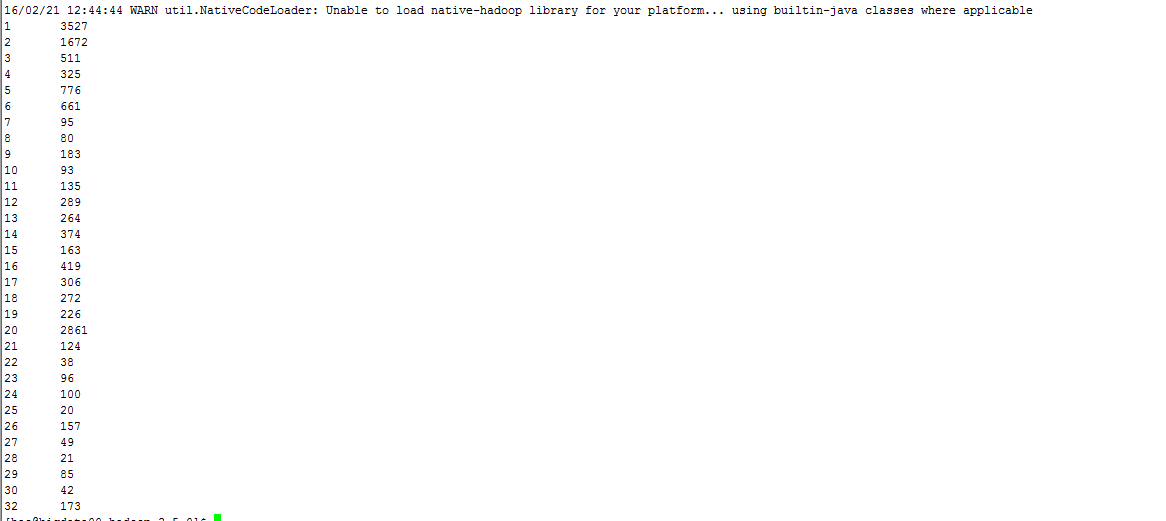
计数器
在mapreduce程序中我们可以将其中的数据记录下来,可以通过计数器来计算这些数据量
计数器包括两种,
分组计数器,
context.getCounter(groupName, counterName)枚举计数器
context.getCounter(CounterName)我们在mapreduce的输出结果中可以看出,mapreduce中的计数器都是以组进行展示,
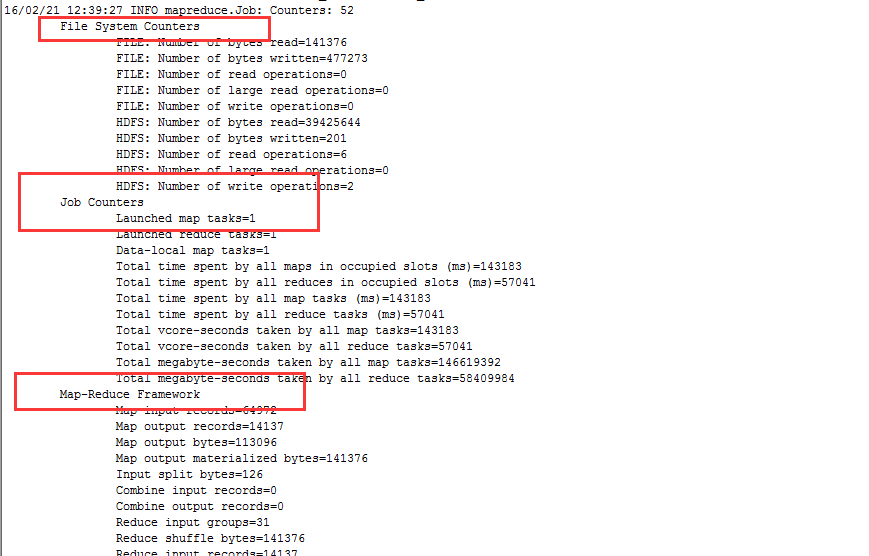
系统默认的计数器分组:
File System Counters
Map-Reduce Framework
APPMAPPER_COUNTERS
Shuffle Errors
File Input Format Counters
File Output Format Counters
计数器的使用,对于我们进一步的理解数据有很大的帮助














 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









