







什么是Sqoop

sqoop是一个数据转换的工具,可以将hadoop和关系型数据库中的数据进行相互高效的转换
1.把关系型数据库的数据导入到hadoop与其相关的系统(HIVE,HBASE)中
2.把数据从Hadoop系统抽取并导出到关系型数据库中
sqoop利用MapReduce加快数据传输的速度,批处理的方式进行数据传输。注意,只有Map任务,没有Reduce任务
Sqoop1和Sqoop2的对比
1.Sqoop1和Sqoop2是两个完全不兼容的版本,功能相差不大
版本划分方式:
sqoop1 :1.4.x~
sqoop2:1.99.x~
2.Sqoop2比Sqoop1改进的地方
引入sqoop server,集中管理Connector等
多种访问访问方式:cli,Web UI,REST API
引入基于角色的安全机制
3.sqoop在企业中的使用场景;
1.将关系型数据库表中的数据增量抽取到Hive表中,或者Hdfs文件(import)
2.将hive表中的数据,导出到关系型数据库中(export)
Sqoop的结构
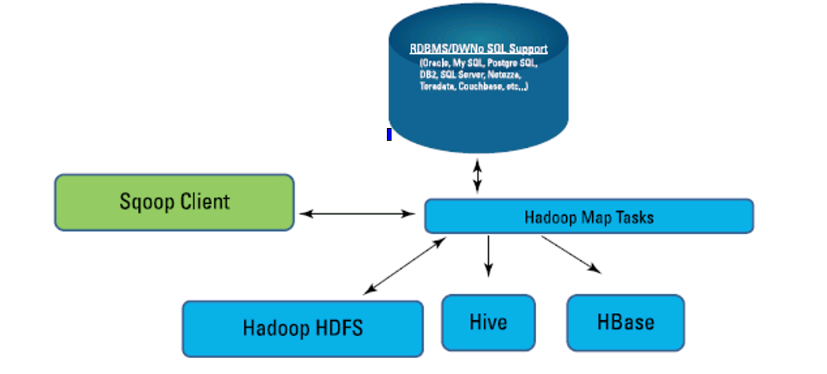
sqoop将hadoop相关系统的数据和关系型数据库数据之间进行相互的操作。
sqoop访问入口,输入命令,进行将数据的导入,导出、
Sqoop的安装配置
sqoop文档
http://archive.cloudera.com/cdh5/cdh/5/sqoop-1.4.5-cdh5.3.6/
解压sqoop安装包
$ tar zxf sqoop-1.4.5-cdh5.3.6.tar.gz -C /opt/cdh5.3.6/
配置conf目录下文件sqoop-env-template.sh
1.更改sqoop-env-template.sh文件名为 sqoop-env.sh
mv sqoop-env-template.cmd sqoop-env.sh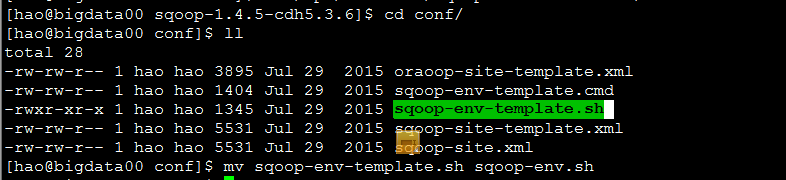
2修改文件内容
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/opt/cdh5.3.6/hadoop-2.5.0-cdh5.3.6
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/opt/cdh5.3.6/hadoop-2.5.0-cdh5.3.6
#Set the path to where bin/hive is available
export HIVE_HOME=/opt/cdh5.3.6/hive-0.13.1-cdh5.3.6
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/opt/cdh5.3.6/zookeeper-3.4.5-cdh5.3.6/conf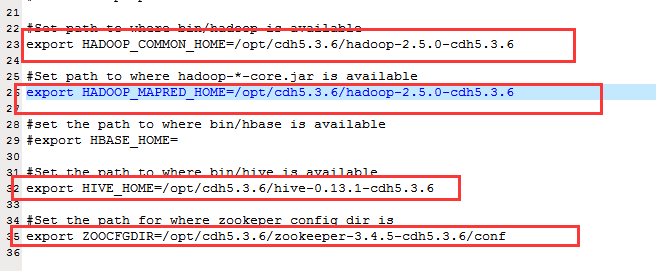
3.拷贝mysql驱动文件到sqoop的lib文件夹下
cp -r /opt/cdh5.3.6/hive-0.13.1-cdh5.3.6/lib/mysql-connector-java-5.1.27-bin.jar /opt/cdh5.3.6/sqoop-1.4.5-cdh5.3.6/lib/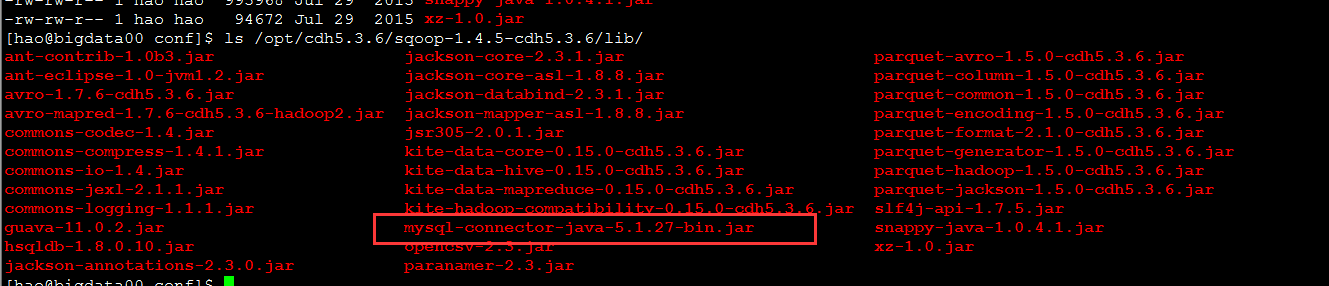
启动sqoop
进入sqoop文件
bin/sqoop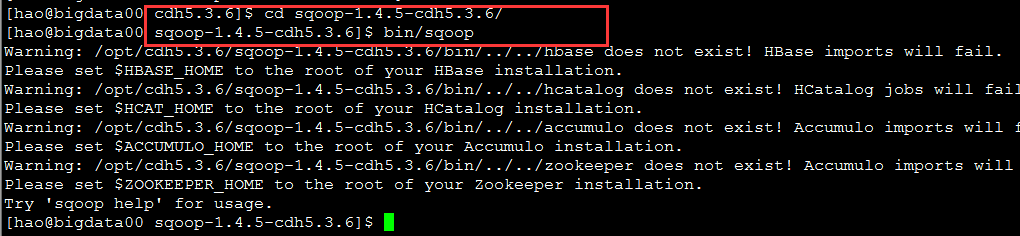
使用 bin/sqoop help
查看帮助
使用sqoop连接数据库
bin/sqoop list-databases 使用命令查看连接数据库的信息
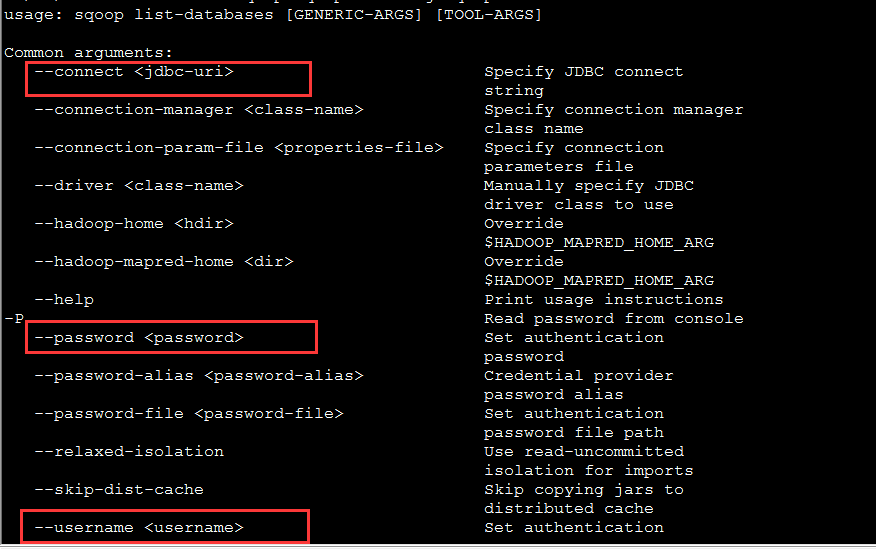
连接数据库
bin/sqoop list-databases \
--connect jdbc:mysql://localhost:3306 \
--username root \
--password 123456 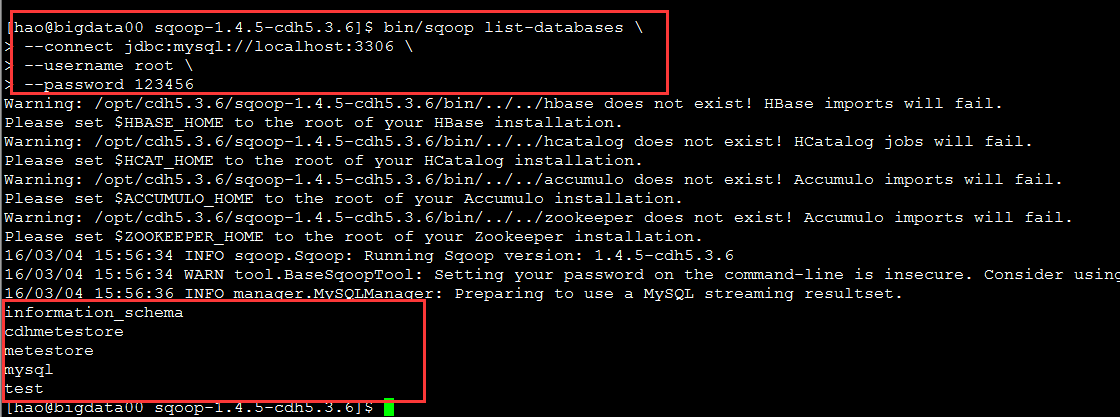
sqoop导入(import),导出数据(export)
sqoop import(导入数据到hdfs)
常规导入
bin/sqoop import \
--connect jdbc:mysql://localhost:3306/sqoop_test \
--username root \
--password 123456
--table my_user --设置要导出的表名
--num-mappers 1 --设置map的数量
--delete-target-dir --导入目录删除之前的目录
--target-dir /sqoop/imp/ --设置导出到hdfs的目录
--direct --直接使用mysqldump命令
--fields-terminated-by '\t' --设置字符的格式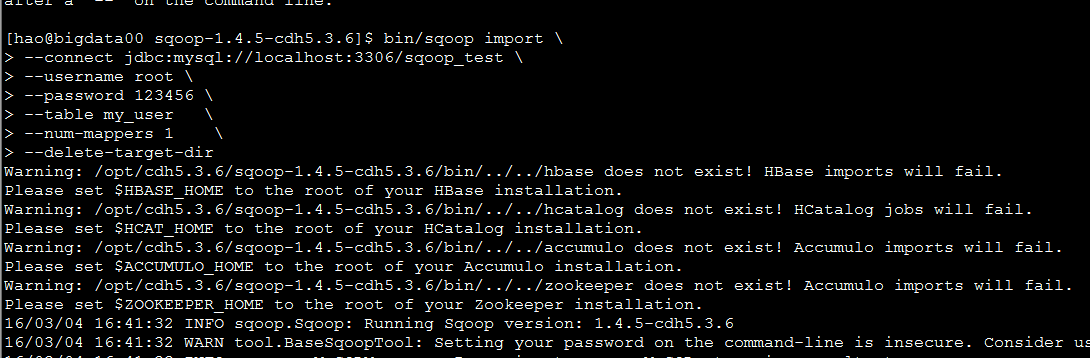
查看导出结果
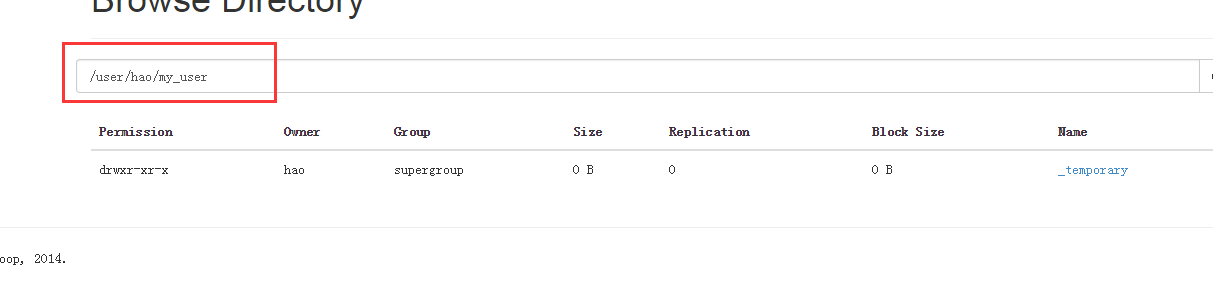
注意
1.使用direct时必须保证在每个yarn上都要有mysqldump
2.–incremental和–delete-target-dir 不可以同时使用
增量导入
bin/sqoop import \
--connect jdbc:mysql://localhost:3306/sqoop_test \
--username root \
--password 123456
--table my_user --设置要导出的表名
--num-mappers 1 --设置map的数量
--delete-target-dir --导入目录删除之前的目录
--target-dir /sqoop/imp/ --设置导出到hdfs的目录
--direct --直接使用mysqldump命令
--fields-terminated-by '\t' --设置字符的格式
--check-column --制定一个字段(数据插入的时间)
--incremental --追加信息(增量)
--last-value 4 --上一次插入最后一列的数增量导入主要属性:
–check-column –制定一个字段(数据插入的时间)
–incremental –追加信息(增量)
–last-value 4 –上一次插入最后一列的数
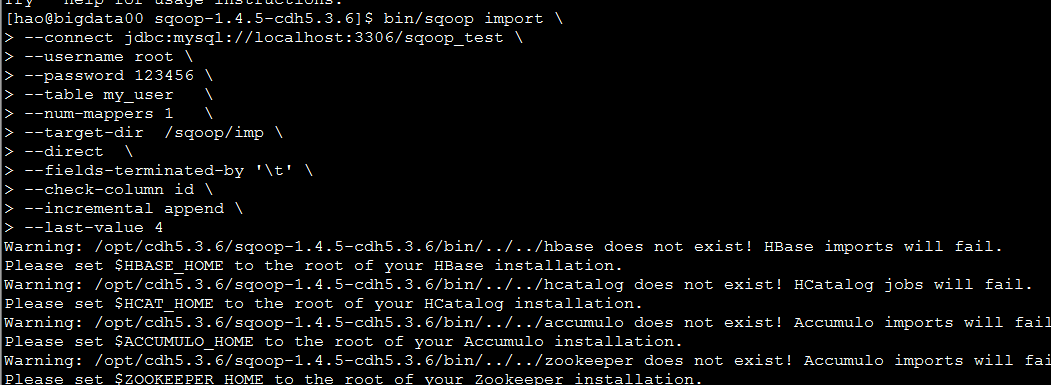
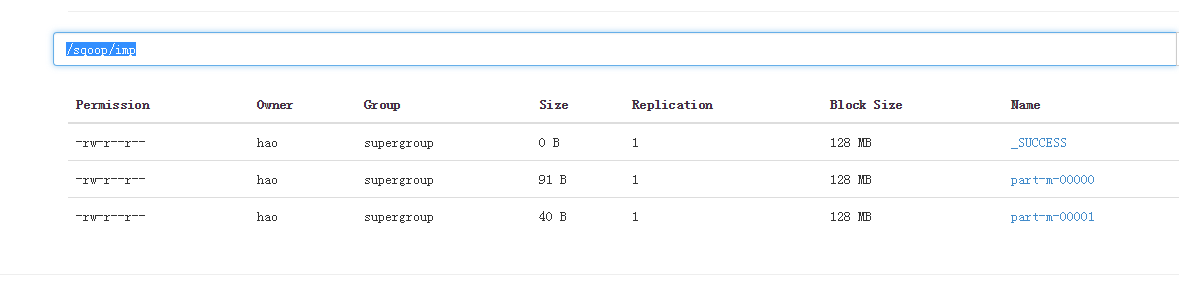
查看导出结果
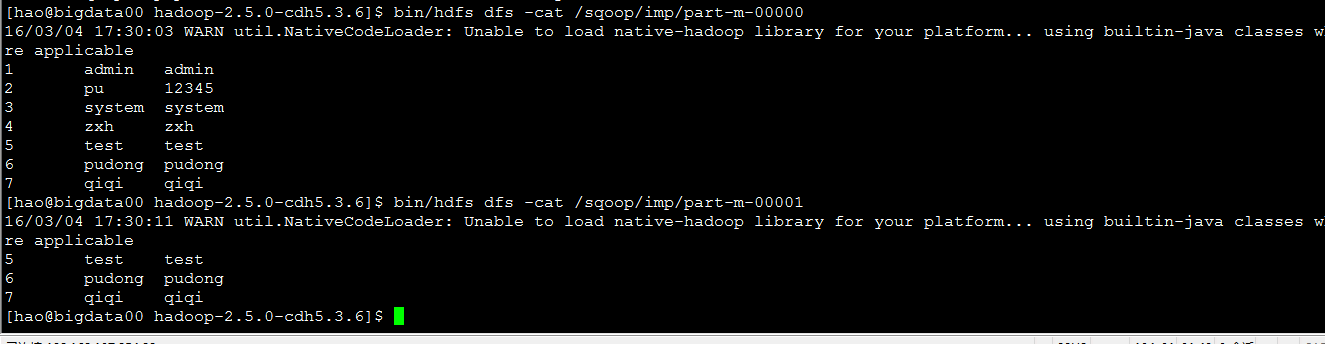
查询语句导入
bin/sqoop import \
--connect jdbc:mysql://localhost:3306/sqoop_test \
--username root \
--password 123456 \
--query "select * from my_user where \$CONDITIONS" \
--num-mappers 1 \
--delete-target-dir \
--target-dir /sqoop/imp \
--direct \
--fields-terminated-by '\t'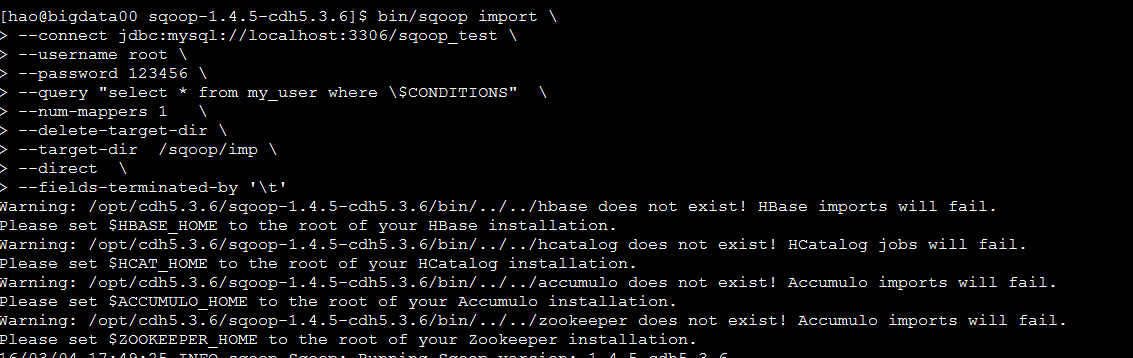
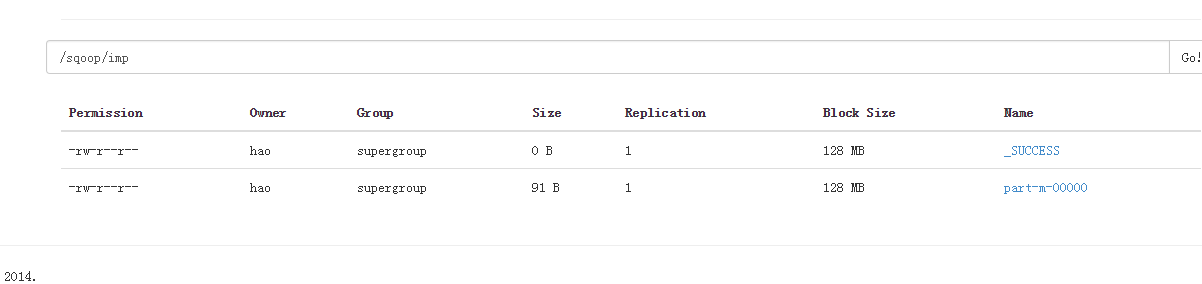
查看导出结果
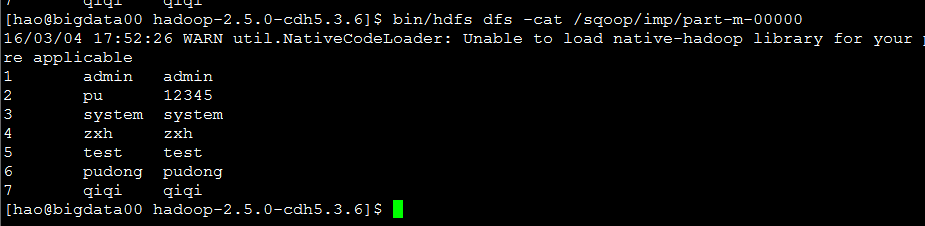
注意!
使用–query 查询语句查询导入的时候,–table不能与之同时使用
指定字段导入
bin/sqoop import \
--connect jdbc:mysql://localhost:3306/sqoop_test \
--username root \
--password 123456 \
--table my_user \
--columns "id,account" \
--num-mappers 1 \
--delete-target-dir \
--target-dir /sqoop/imp \
--direct \
--fields-terminated-by '\t'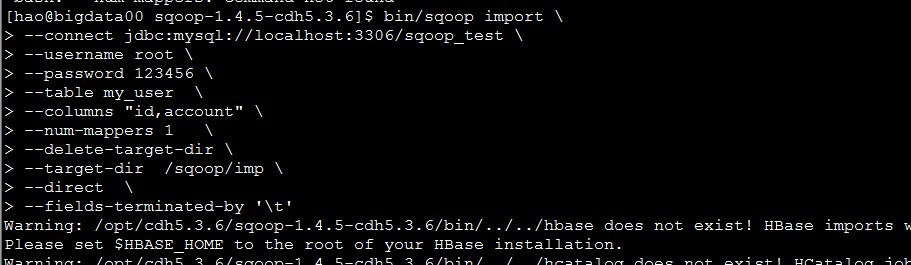
查看导出结果
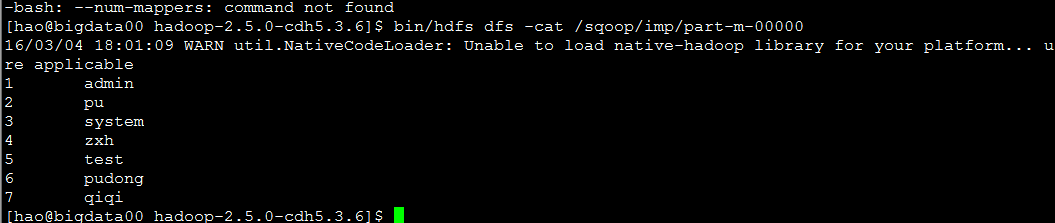
where 条件查询导入
bin/sqoop import \
--connect jdbc:mysql://localhost:3306/sqoop_test \
--username root \
--password 123456 \
--table my_user \
--where "passwd ='admin' or account='put'" \
--num-mappers 1 \
--delete-target-dir \
--target-dir /sqoop/imp \
--direct \
--fields-terminated-by '\t'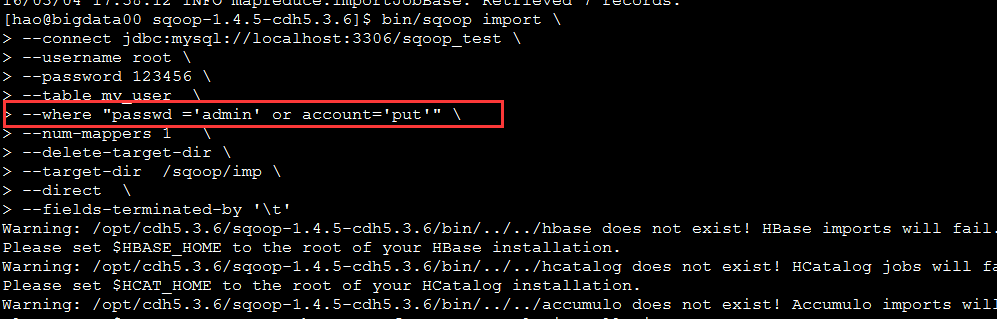
查看导出结果

sqoop export(导出数据到mysql)
使用hellp命令查看export的相关参数
bin/sqoop export --help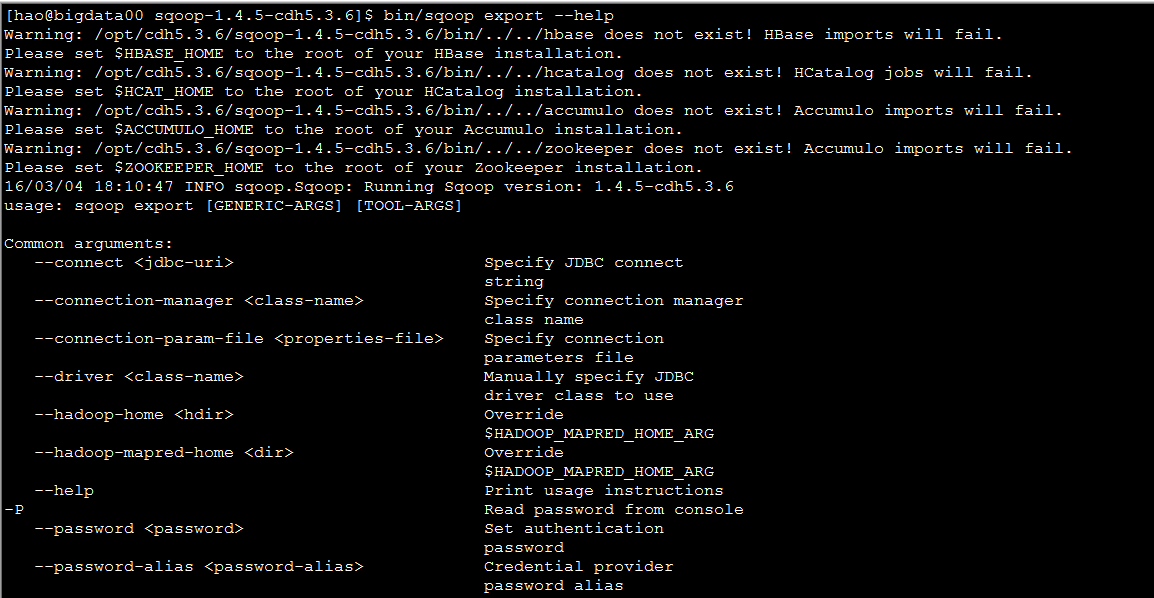
导出hdfs数据到数据库
bin/sqoop export \
--connect jdbc:mysql://localhost:3306/sqoop_test \
--username root \
--password 123456 \
--table export_my_user \
--num-mappers 1 \
--export-dir /user/hao/my_user \
--input-fields-terminated-by ',' 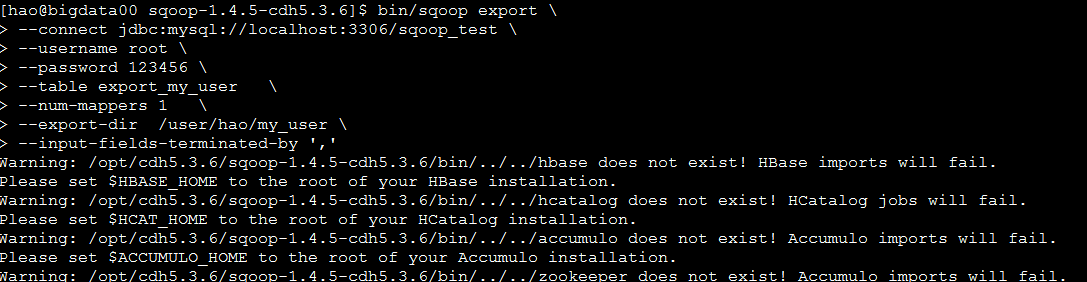
查看结果
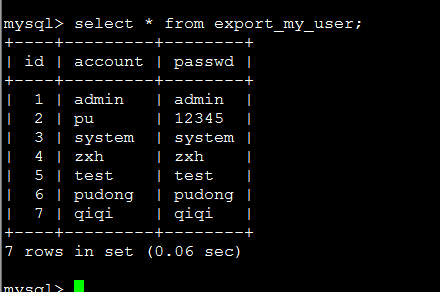
注意要上传的数据格式,是分隔符还是逗号等。。。
导入数据到hive表
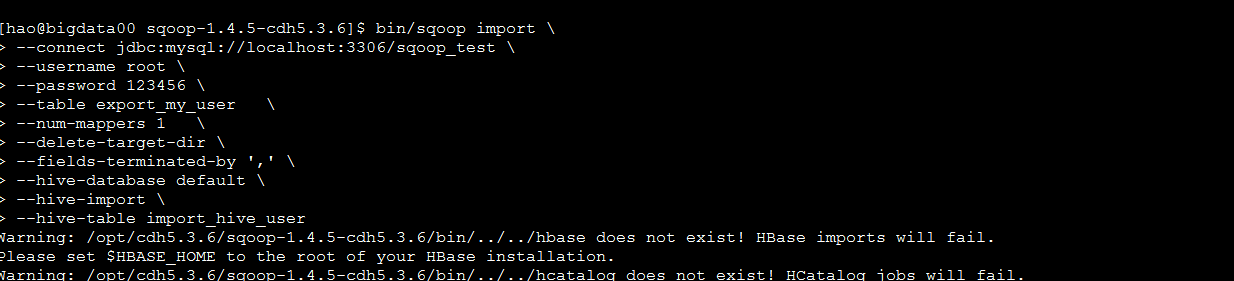
查看结果,要注意数据格式,”\t”,”,”
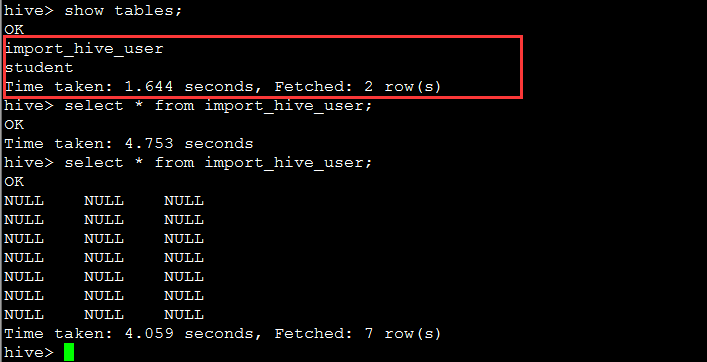
注意
hive 尽量使用默认的用户,否则可能无法加载数据
















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









