







《模型思维》第二十六章 “学习模型” 的核心内容总结,结合斯科特·佩奇的核心观点与逻辑框架:
1. 学习模型的本质与目标
-
核心思想:个体或系统通过经验积累和反馈调整优化行为策略,适应动态环境。
-
关键机制:
“学习是理性与探索的交织——过去的知识引导方向,未知的可能性驱动创新。”
-
探索(Exploration):尝试新策略以发现潜在收益。
-
利用(Exploitation):优化已知有效策略以最大化短期收益。
-
2. 学习模型的经典类型
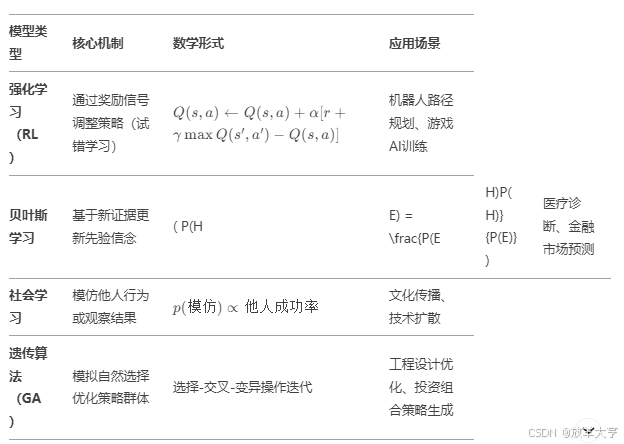
3. 学习模型的动态过程
(1)探索-利用困境(Exploration-Exploitation Tradeoff)
-
多臂老虎机问题:在未知奖励分布的机器中选择最优拉杆。
-
策略对比:
策略 逻辑 优势 劣势 ε-贪婪 以概率ε随机探索,否则利用最优 简单易实现 探索效率低 汤普森采样 基于贝叶斯后验概率动态平衡 自适应探索与利用 计算复杂度高 UCB(置信区间上界) 选择置信区间上限最大的选项 理论最优性保证 需已知收益分布形式
(2)学习曲线与收敛性
-
学习曲线:随着时间或经验增长,性能(如准确率、收益)的变化趋势。
-
S型曲线:初期快速提升,后期边际收益递减(如语言学习)。
-
渐进收敛:逼近理论最优值(如深度学习模型训练)。
-
4. 应用场景与典型案例
| 领域 | 问题 | 模型工具 | 成果 |
|---|---|---|---|
| 人工智能 | 自动驾驶决策系统 | 深度强化学习(Deep Q-Network) | Tesla Autopilot路径规划优化 |
| 市场营销 | 动态定价策略 | 贝叶斯Bandit算法 | 亚马逊实时调整商品价格最大化收益 |
| 教育科学 | 个性化学习路径推荐 | 多臂老虎机框架 | Khan Academy自适应学习平台 |
| 生态学 | 动物觅食行为模拟 | 遗传算法与强化学习结合 | 鸟类迁徙路线优化模型 |
5. 学习模型的挑战与对策
| 挑战 | 对策 | 案例 |
|---|---|---|
| 局部最优陷阱 | 引入随机扰动(如模拟退火) | 避免优化算法陷入次优解 |
| 过拟合 | 正则化与交叉验证 | 机器学习模型防止训练数据过度适应 |
| 维度灾难 | 降维与特征选择(如PCA) | 高维数据(图像、文本)处理效率提升 |
| 延迟反馈 | 信用分配(Credit Assignment) | 强化学习中长期动作的奖励回溯机制 |
6. 学习模型的实践启示
-
动态适应设计:
-
在快速变化环境中(如金融市场),采用在线学习(实时更新策略)。
-
在稳定环境中(如制造业流程),采用批量学习(定期优化模型)。
-
-
混合学习策略:
-
结合社会学习(模仿成功者)与个体试错(探索新路径)。
-
-
认知多样性:
“学习模型的终极力量来自多样性——不同的学习规则相互竞争,催生更优解。”
-
组织内允许多种学习方式共存(如数据驱动与直觉决策互补)。
-
总结:学习模型的进化力量
斯科特·佩奇强调,学习模型是**“适应性智慧的引擎”**,其核心价值在于:
-
从个体到系统:
-
个体学习:优化个人决策(如职业发展中的技能迭代)。
-
集体学习:组织知识积累(如企业经验数据库与AI结合)。
-
-
从理论到实践:
“学习不是信息的堆积,而是模型的进化——淘汰无效假设,保留生存法则。”
正如书中所言:
“世界是一本打开的书,学习模型是我们解读它的语法——每一次翻页,都是认知的跃迁。”
通过学习模型,我们得以在不确定中寻找规律,在失败中孕育创新,重新定义人类与智能的协作边界。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









